private void createShard(DiscoveryNodes nodes, RoutingTable routingTable, ShardRouting shardRouting, ClusterState state) { assert shardRouting.initializing() : "only allow shard creation for initializing shard but was " + shardRouting;
DiscoveryNode sourceNode = null; // 如果恢复方式是peer,则会找到shard所在的源节点进行恢复 if (shardRouting.recoverySource().getType() == Type.PEER) { sourceNode = findSourceNodeForPeerRecovery(logger, routingTable, nodes, shardRouting); if (sourceNode == null) { logger.trace("ignoring initializing shard {} - no source node can be found.", shardRouting.shardId()); return; } }
try { final long primaryTerm = state.metadata().index(shardRouting.index()).primaryTerm(shardRouting.id()); logger.debug("{} creating shard with primary term [{}]", shardRouting.shardId(), primaryTerm); indicesService.createShard( shardRouting, recoveryTargetService, new RecoveryListener(shardRouting, primaryTerm), repositoriesService, failedShardHandler, this::updateGlobalCheckpointForShard, retentionLeaseSyncer, nodes.getLocalNode(), sourceNode); } catch (Exception e) { failAndRemoveShard(shardRouting, true, "failed to create shard", e, state); } }
/** * Finds the routing source node for peer recovery, return null if its not found. Note, this method expects the shard * routing to *require* peer recovery, use {@link ShardRouting#recoverySource()} to check if its needed or not. */ private static DiscoveryNode findSourceNodeForPeerRecovery(Logger logger, RoutingTable routingTable, DiscoveryNodes nodes, ShardRouting shardRouting) { DiscoveryNode sourceNode = null; if (!shardRouting.primary()) { ShardRouting primary = routingTable.shardRoutingTable(shardRouting.shardId()).primaryShard(); // only recover from started primary, if we can't find one, we will do it next round if (primary.active()) { // 找到primary shard所在节点 sourceNode = nodes.get(primary.currentNodeId()); if (sourceNode == null) { logger.trace("can't find replica source node because primary shard {} is assigned to an unknown node.", primary); } } else { logger.trace("can't find replica source node because primary shard {} is not active.", primary); } } else if (shardRouting.relocatingNodeId() != null) { // 找到搬迁的源节点 sourceNode = nodes.get(shardRouting.relocatingNodeId()); if (sourceNode == null) { logger.trace("can't find relocation source node for shard {} because it is assigned to an unknown node [{}].", shardRouting.shardId(), shardRouting.relocatingNodeId()); } } else { throw new IllegalStateException("trying to find source node for peer recovery when routing state means no peer recovery: " + shardRouting); } return sourceNode; }
private void doRecovery(final long recoveryId, final StartRecoveryRequest preExistingRequest) { final String actionName; final TransportRequest requestToSend; final StartRecoveryRequest startRequest; final RecoveryState.Timer timer; try (RecoveryRef recoveryRef = onGoingRecoveries.getRecovery(recoveryId)) { if (recoveryRef == null) { logger.trace("not running recovery with id [{}] - can not find it (probably finished)", recoveryId); return; } final RecoveryTarget recoveryTarget = recoveryRef.target(); timer = recoveryTarget.state().getTimer(); if (preExistingRequest == null) { try { final IndexShard indexShard = recoveryTarget.indexShard(); indexShard.preRecovery(); assert recoveryTarget.sourceNode() != null : "can not do a recovery without a source node"; logger.trace("{} preparing shard for peer recovery", recoveryTarget.shardId()); indexShard.prepareForIndexRecovery(); final long startingSeqNo = indexShard.recoverLocallyUpToGlobalCheckpoint(); assert startingSeqNo == UNASSIGNED_SEQ_NO || recoveryTarget.state().getStage() == RecoveryState.Stage.TRANSLOG : "unexpected recovery stage [" + recoveryTarget.state().getStage() + "] starting seqno [ " + startingSeqNo + "]"; // 构造recovery request startRequest = getStartRecoveryRequest(logger, clusterService.localNode(), recoveryTarget, startingSeqNo); requestToSend = startRequest; actionName = PeerRecoverySourceService.Actions.START_RECOVERY; } catch (final Exception e) { // this will be logged as warning later on... logger.trace("unexpected error while preparing shard for peer recovery, failing recovery", e); onGoingRecoveries.failRecovery(recoveryId, new RecoveryFailedException(recoveryTarget.state(), "failed to prepare shard for recovery", e), true); return; } logger.trace("{} starting recovery from {}", startRequest.shardId(), startRequest.sourceNode()); } else { startRequest = preExistingRequest; requestToSend = new ReestablishRecoveryRequest(recoveryId, startRequest.shardId(), startRequest.targetAllocationId()); actionName = PeerRecoverySourceService.Actions.REESTABLISH_RECOVERY; logger.trace("{} reestablishing recovery from {}", startRequest.shardId(), startRequest.sourceNode()); } } // 向源节点发送请求,请求恢复 transportService.sendRequest(startRequest.sourceNode(), actionName, requestToSend, new RecoveryResponseHandler(startRequest, timer)); }
/** * Prepare the start recovery request. * * @param logger the logger * @param localNode the local node of the recovery target * @param recoveryTarget the target of the recovery * @param startingSeqNo a sequence number that an operation-based peer recovery can start with. * This is the first operation after the local checkpoint of the safe commit if exists. * @return a start recovery request */ public static StartRecoveryRequest getStartRecoveryRequest(Logger logger, DiscoveryNode localNode, RecoveryTarget recoveryTarget, long startingSeqNo) { final StartRecoveryRequest request; logger.trace("{} collecting local files for [{}]", recoveryTarget.shardId(), recoveryTarget.sourceNode());
Store.MetadataSnapshot metadataSnapshot; try { metadataSnapshot = recoveryTarget.indexShard().snapshotStoreMetadata(); // Make sure that the current translog is consistent with the Lucene index; otherwise, we have to throw away the Lucene index. try { final String expectedTranslogUUID = metadataSnapshot.getCommitUserData().get(Translog.TRANSLOG_UUID_KEY); final long globalCheckpoint = Translog.readGlobalCheckpoint(recoveryTarget.translogLocation(), expectedTranslogUUID); assert globalCheckpoint + 1 >= startingSeqNo : "invalid startingSeqNo " + startingSeqNo + " >= " + globalCheckpoint; } catch (IOException | TranslogCorruptedException e) { logger.warn(new ParameterizedMessage("error while reading global checkpoint from translog, " + "resetting the starting sequence number from {} to unassigned and recovering as if there are none", startingSeqNo), e); metadataSnapshot = Store.MetadataSnapshot.EMPTY; startingSeqNo = UNASSIGNED_SEQ_NO; } } catch (final org.apache.lucene.index.IndexNotFoundException e) { // happens on an empty folder. no need to log assert startingSeqNo == UNASSIGNED_SEQ_NO : startingSeqNo; logger.trace("{} shard folder empty, recovering all files", recoveryTarget); metadataSnapshot = Store.MetadataSnapshot.EMPTY; } catch (final IOException e) { if (startingSeqNo != UNASSIGNED_SEQ_NO) { logger.warn(new ParameterizedMessage("error while listing local files, resetting the starting sequence number from {} " + "to unassigned and recovering as if there are none", startingSeqNo), e); startingSeqNo = UNASSIGNED_SEQ_NO; } else { logger.warn("error while listing local files, recovering as if there are none", e); } metadataSnapshot = Store.MetadataSnapshot.EMPTY; } logger.trace("{} local file count [{}]", recoveryTarget.shardId(), metadataSnapshot.size()); request = new StartRecoveryRequest( recoveryTarget.shardId(), recoveryTarget.indexShard().routingEntry().allocationId().getId(), recoveryTarget.sourceNode(), localNode, metadataSnapshot, recoveryTarget.state().getPrimary(), recoveryTarget.recoveryId(), startingSeqNo); return request; }
private void recover(StartRecoveryRequest request, ActionListener<RecoveryResponse> listener) { final IndexService indexService = indicesService.indexServiceSafe(request.shardId().getIndex()); final IndexShard shard = indexService.getShard(request.shardId().id());
final ShardRouting routingEntry = shard.routingEntry();
if (routingEntry.primary() == false || routingEntry.active() == false) { throw new DelayRecoveryException("source shard [" + routingEntry + "] is not an active primary"); }
if (request.isPrimaryRelocation() && (routingEntry.relocating() == false || routingEntry.relocatingNodeId().equals(request.targetNode().getId()) == false)) { logger.debug("delaying recovery of {} as source shard is not marked yet as relocating to {}", request.shardId(), request.targetNode()); throw new DelayRecoveryException("source shard is not marked yet as relocating to [" + request.targetNode() + "]"); }
/** * performs the recovery from the local engine to the target */ public void recoverToTarget(ActionListener<RecoveryResponse> listener) { addListener(listener); final Closeable releaseResources = () -> IOUtils.close(resources); try { cancellableThreads.setOnCancel((reason, beforeCancelEx) -> { final RuntimeException e; if (shard.state() == IndexShardState.CLOSED) { // check if the shard got closed on us e = new IndexShardClosedException(shard.shardId(), "shard is closed and recovery was canceled reason [" + reason + "]"); } else { e = new CancellableThreads.ExecutionCancelledException("recovery was canceled reason [" + reason + "]"); } if (beforeCancelEx != null) { e.addSuppressed(beforeCancelEx); } IOUtils.closeWhileHandlingException(releaseResources, () -> future.onFailure(e)); throw e; }); final Consumer<Exception> onFailure = e -> { assert Transports.assertNotTransportThread(RecoverySourceHandler.this + "[onFailure]"); IOUtils.closeWhileHandlingException(releaseResources, () -> future.onFailure(e)); };
final SetOnce<RetentionLease> retentionLeaseRef = new SetOnce<>();
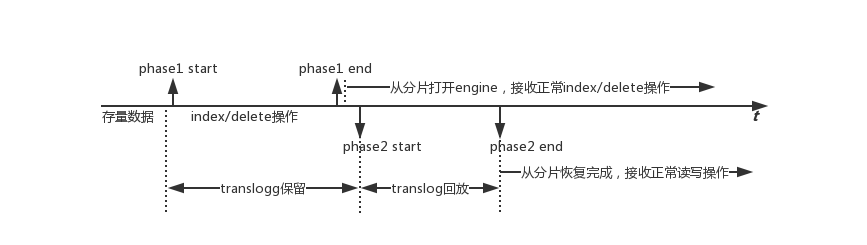
runUnderPrimaryPermit(() -> { final IndexShardRoutingTable routingTable = shard.getReplicationGroup().getRoutingTable(); ShardRouting targetShardRouting = routingTable.getByAllocationId(request.targetAllocationId()); if (targetShardRouting == null) { logger.debug("delaying recovery of {} as it is not listed as assigned to target node {}", request.shardId(), request.targetNode()); throw new DelayRecoveryException("source node does not have the shard listed in its state as allocated on the node"); } assert targetShardRouting.initializing() : "expected recovery target to be initializing but was " + targetShardRouting; retentionLeaseRef.set( shard.getRetentionLeases().get(ReplicationTracker.getPeerRecoveryRetentionLeaseId(targetShardRouting))); }, shardId + " validating recovery target ["+ request.targetAllocationId() + "] registered ", shard, cancellableThreads, logger); // 获取一个保留锁,使得translog不被清理 final Closeable retentionLock = shard.acquireHistoryRetentionLock(); resources.add(retentionLock); final long startingSeqNo; // 判断是否可以从SequenceNumber恢复 // 除了异常检测和版本号检测,主要在shard.hasCompleteHistoryOperations()方法中判断请求的序列号是否小于主分片节点的localCheckpoint, // 以及translog中的数据是否足以恢复(有可能因为translog数据太大或者过期删除而无法恢复) final boolean isSequenceNumberBasedRecovery = request.startingSeqNo() != SequenceNumbers.UNASSIGNED_SEQ_NO && isTargetSameHistory() && shard.hasCompleteHistoryOperations("peer-recovery", request.startingSeqNo()) && ((retentionLeaseRef.get() == null && shard.useRetentionLeasesInPeerRecovery() == false) || (retentionLeaseRef.get() != null && retentionLeaseRef.get().retainingSequenceNumber() <= request.startingSeqNo())); // NB check hasCompleteHistoryOperations when computing isSequenceNumberBasedRecovery, even if there is a retention lease, // because when doing a rolling upgrade from earlier than 7.4 we may create some leases that are initially unsatisfied. It's // possible there are other cases where we cannot satisfy all leases, because that's not a property we currently expect to hold. // Also it's pretty cheap when soft deletes are enabled, and it'd be a disaster if we tried a sequence-number-based recovery // without having a complete history.
if (isSequenceNumberBasedRecovery && retentionLeaseRef.get() != null) { // all the history we need is retained by an existing retention lease, so we do not need a separate retention lock retentionLock.close(); logger.trace("history is retained by {}", retentionLeaseRef.get()); } else { // all the history we need is retained by the retention lock, obtained before calling shard.hasCompleteHistoryOperations() // and before acquiring the safe commit we'll be using, so we can be certain that all operations after the safe commit's // local checkpoint will be retained for the duration of this recovery. logger.trace("history is retained by retention lock"); }
final StepListener<SendFileResult> sendFileStep = new StepListener<>(); final StepListener<TimeValue> prepareEngineStep = new StepListener<>(); final StepListener<SendSnapshotResult> sendSnapshotStep = new StepListener<>(); final StepListener<Void> finalizeStep = new StepListener<>(); // 若可以基于序列号进行恢复,则获取开始的序列号 if (isSequenceNumberBasedRecovery) { // 如果基于SequenceNumber恢复,则startingSeqNo取值为恢复请求中的序列号, // 从请求的序列号开始快照translog。否则取值为0,快照完整的translog。 logger.trace("performing sequence numbers based recovery. starting at [{}]", request.startingSeqNo()); // 获取开始序列号 startingSeqNo = request.startingSeqNo(); if (retentionLeaseRef.get() == null) { createRetentionLease(startingSeqNo, sendFileStep.map(ignored -> SendFileResult.EMPTY)); } else { // 发送的文件设置为空 sendFileStep.onResponse(SendFileResult.EMPTY); } } else { final Engine.IndexCommitRef safeCommitRef; try { // Releasing a safe commit can access some commit files. safeCommitRef = acquireSafeCommit(shard); resources.add(safeCommitRef); } catch (final Exception e) { throw new RecoveryEngineException(shard.shardId(), 1, "snapshot failed", e); }
// Try and copy enough operations to the recovering peer so that if it is promoted to primary then it has a chance of being // able to recover other replicas using operations-based recoveries. If we are not using retention leases then we // conservatively copy all available operations. If we are using retention leases then "enough operations" is just the // operations from the local checkpoint of the safe commit onwards, because when using soft deletes the safe commit retains // at least as much history as anything else. The safe commit will often contain all the history retained by the current set // of retention leases, but this is not guaranteed: an earlier peer recovery from a different primary might have created a // retention lease for some history that this primary already discarded, since we discard history when the global checkpoint // advances and not when creating a new safe commit. In any case this is a best-effort thing since future recoveries can // always fall back to file-based ones, and only really presents a problem if this primary fails before things have settled // down. startingSeqNo = Long.parseLong(safeCommitRef.getIndexCommit().getUserData().get(SequenceNumbers.LOCAL_CHECKPOINT_KEY)) + 1L; logger.trace("performing file-based recovery followed by history replay starting at [{}]", startingSeqNo);
try { final int estimateNumOps = estimateNumberOfHistoryOperations(startingSeqNo); final Releasable releaseStore = acquireStore(shard.store()); resources.add(releaseStore); sendFileStep.whenComplete(r -> IOUtils.close(safeCommitRef, releaseStore), e -> { try { IOUtils.close(safeCommitRef, releaseStore); } catch (final IOException ex) { logger.warn("releasing snapshot caused exception", ex); } });
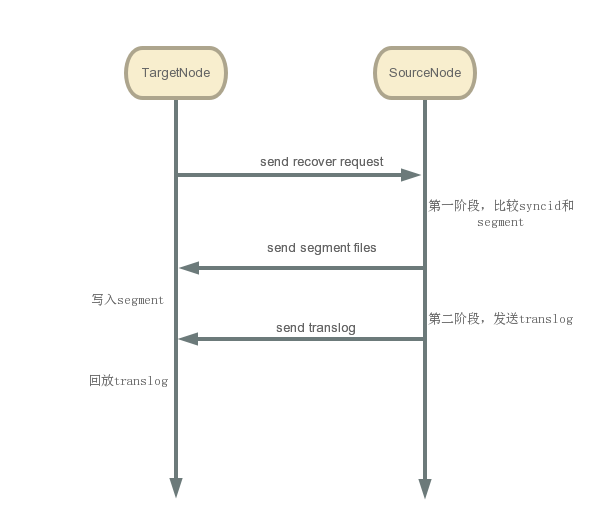
final StepListener<ReplicationResponse> deleteRetentionLeaseStep = new StepListener<>(); runUnderPrimaryPermit(() -> { try { // If the target previously had a copy of this shard then a file-based recovery might move its global // checkpoint backwards. We must therefore remove any existing retention lease so that we can create a // new one later on in the recovery. shard.removePeerRecoveryRetentionLease(request.targetNode().getId(), new ThreadedActionListener<>(logger, shard.getThreadPool(), ThreadPool.Names.GENERIC, deleteRetentionLeaseStep, false)); } catch (RetentionLeaseNotFoundException e) { logger.debug("no peer-recovery retention lease for " + request.targetAllocationId()); deleteRetentionLeaseStep.onResponse(null); } }, shardId + " removing retention lease for [" + request.targetAllocationId() + "]", shard, cancellableThreads, logger); // 第一阶段 deleteRetentionLeaseStep.whenComplete(ignored -> { assert Transports.assertNotTransportThread(RecoverySourceHandler.this + "[phase1]"); phase1(safeCommitRef.getIndexCommit(), startingSeqNo, () -> estimateNumOps, sendFileStep); }, onFailure);
} catch (final Exception e) { throw new RecoveryEngineException(shard.shardId(), 1, "sendFileStep failed", e); } } assert startingSeqNo >= 0 : "startingSeqNo must be non negative. got: " + startingSeqNo;
sendFileStep.whenComplete(r -> { assert Transports.assertNotTransportThread(RecoverySourceHandler.this + "[prepareTargetForTranslog]"); // 等待phase1执行完毕,主分片节点通知副分片节点启动此分片的Engine:prepareTargetForTranslog // 该方法会阻塞处理,直到分片 Engine 启动完毕。 // 待副分片启动Engine 完毕,就可以正常接收写请求了。 // 注意,此时phase2尚未开始,此分片的恢复流程尚未结束。 // 等待当前操作处理完成后,以startingSeqNo为起始点,对translog做快照,开始执行phase2: // For a sequence based recovery, the target can keep its local translog prepareTargetForTranslog(estimateNumberOfHistoryOperations(startingSeqNo), prepareEngineStep); }, onFailure);
prepareEngineStep.whenComplete(prepareEngineTime -> { assert Transports.assertNotTransportThread(RecoverySourceHandler.this + "[phase2]"); /* * add shard to replication group (shard will receive replication requests from this point on) now that engine is open. * This means that any document indexed into the primary after this will be replicated to this replica as well * make sure to do this before sampling the max sequence number in the next step, to ensure that we send * all documents up to maxSeqNo in phase2. */ runUnderPrimaryPermit(() -> shard.initiateTracking(request.targetAllocationId()), shardId + " initiating tracking of " + request.targetAllocationId(), shard, cancellableThreads, logger);
final long endingSeqNo = shard.seqNoStats().getMaxSeqNo(); logger.trace("snapshot for recovery; current size is [{}]", estimateNumberOfHistoryOperations(startingSeqNo)); final Translog.Snapshot phase2Snapshot = shard.newChangesSnapshot("peer-recovery", startingSeqNo, Long.MAX_VALUE, false); resources.add(phase2Snapshot); retentionLock.close();
// we have to capture the max_seen_auto_id_timestamp and the max_seq_no_of_updates to make sure that these values // are at least as high as the corresponding values on the primary when any of these operations were executed on it. final long maxSeenAutoIdTimestamp = shard.getMaxSeenAutoIdTimestamp(); final long maxSeqNoOfUpdatesOrDeletes = shard.getMaxSeqNoOfUpdatesOrDeletes(); final RetentionLeases retentionLeases = shard.getRetentionLeases(); final long mappingVersionOnPrimary = shard.indexSettings().getIndexMetadata().getMappingVersion(); // 第二阶段,发送translog phase2(startingSeqNo, endingSeqNo, phase2Snapshot, maxSeenAutoIdTimestamp, maxSeqNoOfUpdatesOrDeletes, retentionLeases, mappingVersionOnPrimary, sendSnapshotStep);
}, onFailure);
// Recovery target can trim all operations >= startingSeqNo as we have sent all these operations in the phase 2 final long trimAboveSeqNo = startingSeqNo - 1; sendSnapshotStep.whenComplete(r -> finalizeRecovery(r.targetLocalCheckpoint, trimAboveSeqNo, finalizeStep), onFailure);
finalizeStep.whenComplete(r -> { final long phase1ThrottlingWaitTime = 0L; // TODO: return the actual throttle time final SendSnapshotResult sendSnapshotResult = sendSnapshotStep.result(); final SendFileResult sendFileResult = sendFileStep.result(); final RecoveryResponse response = new RecoveryResponse(sendFileResult.phase1FileNames, sendFileResult.phase1FileSizes, sendFileResult.phase1ExistingFileNames, sendFileResult.phase1ExistingFileSizes, sendFileResult.totalSize, sendFileResult.existingTotalSize, sendFileResult.took.millis(), phase1ThrottlingWaitTime, prepareEngineStep.result().millis(), sendSnapshotResult.sentOperations, sendSnapshotResult.tookTime.millis()); try { future.onResponse(response); } finally { IOUtils.close(resources); } }, onFailure); } catch (Exception e) { IOUtils.closeWhileHandlingException(releaseResources, () -> future.onFailure(e)); } }
/** * Checks if we have a completed history of operations since the given starting seqno (inclusive). * This method should be called after acquiring the retention lock; See {@link #acquireHistoryRetentionLock()} */ public boolean hasCompleteHistoryOperations(String reason, long startingSeqNo) { return getEngine().hasCompleteOperationHistory(reason, startingSeqNo); }
/** * Perform phase1 of the recovery operations. Once this {@link IndexCommit} * snapshot has been performed no commit operations (files being fsync'd) * are effectively allowed on this index until all recovery phases are done * <p> * Phase1 examines the segment files on the target node and copies over the * segments that are missing. Only segments that have the same size and * checksum can be reused */ void phase1(IndexCommit snapshot, long startingSeqNo, IntSupplier translogOps, ActionListener<SendFileResult> listener) { cancellableThreads.checkForCancel(); //拿到shard的存储信息 final Store store = shard.store(); try { StopWatch stopWatch = new StopWatch().start(); final Store.MetadataSnapshot recoverySourceMetadata; try { // 拿到snapshot的metadata recoverySourceMetadata = store.getMetadata(snapshot); } catch (CorruptIndexException | IndexFormatTooOldException | IndexFormatTooNewException ex) { shard.failShard("recovery", ex); throw ex; } for (String name : snapshot.getFileNames()) { // MetadataSnapshot:表示从最新的Lucene提交生成的当前目录的快照。 // https://github.com/jiankunking/elasticsearch/blob/master/server/src/main/java/org/elasticsearch/index/store/Store.java#L732 final StoreFileMetadata md = recoverySourceMetadata.get(name); if (md == null) { logger.info("Snapshot differs from actual index for file: {} meta: {}", name, recoverySourceMetadata.asMap()); throw new CorruptIndexException("Snapshot differs from actual index - maybe index was removed metadata has " + recoverySourceMetadata.asMap().size() + " files", name); } } // 如果syncid相等,再继续比较下文档数,如果都相同则不用恢复 if (canSkipPhase1(recoverySourceMetadata, request.metadataSnapshot()) == false) { final List<String> phase1FileNames = new ArrayList<>(); final List<Long> phase1FileSizes = new ArrayList<>(); final List<String> phase1ExistingFileNames = new ArrayList<>(); final List<Long> phase1ExistingFileSizes = new ArrayList<>();
// Total size of segment files that are recovered long totalSizeInBytes = 0; // Total size of segment files that were able to be re-used long existingTotalSizeInBytes = 0;
// Generate a "diff" of all the identical, different, and missing // segment files on the target node, using the existing files on // the source node // 找出target和source有差别的segment // https://github.com/jiankunking/elasticsearch/blob/master/server/src/main/java/org/elasticsearch/index/store/Store.java#L971 final Store.RecoveryDiff diff = recoverySourceMetadata.recoveryDiff(request.metadataSnapshot()); for (StoreFileMetadata md : diff.identical) { phase1ExistingFileNames.add(md.name()); phase1ExistingFileSizes.add(md.length()); existingTotalSizeInBytes += md.length(); if (logger.isTraceEnabled()) { logger.trace("recovery [phase1]: not recovering [{}], exist in local store and has checksum [{}]," + " size [{}]", md.name(), md.checksum(), md.length()); } totalSizeInBytes += md.length(); } List<StoreFileMetadata> phase1Files = new ArrayList<>(diff.different.size() + diff.missing.size()); phase1Files.addAll(diff.different); phase1Files.addAll(diff.missing); for (StoreFileMetadata md : phase1Files) { if (request.metadataSnapshot().asMap().containsKey(md.name())) { logger.trace("recovery [phase1]: recovering [{}], exists in local store, but is different: remote [{}], local [{}]", md.name(), request.metadataSnapshot().asMap().get(md.name()), md); } else { logger.trace("recovery [phase1]: recovering [{}], does not exist in remote", md.name()); } phase1FileNames.add(md.name()); phase1FileSizes.add(md.length()); totalSizeInBytes += md.length(); }
logger.trace("recovery [phase1]: recovering_files [{}] with total_size [{}], reusing_files [{}] with total_size [{}]", phase1FileNames.size(), new ByteSizeValue(totalSizeInBytes), phase1ExistingFileNames.size(), new ByteSizeValue(existingTotalSizeInBytes)); final StepListener<Void> sendFileInfoStep = new StepListener<>(); final StepListener<Void> sendFilesStep = new StepListener<>(); final StepListener<RetentionLease> createRetentionLeaseStep = new StepListener<>(); final StepListener<Void> cleanFilesStep = new StepListener<>(); cancellableThreads.checkForCancel(); recoveryTarget.receiveFileInfo(phase1FileNames, phase1FileSizes, phase1ExistingFileNames, phase1ExistingFileSizes, translogOps.getAsInt(), sendFileInfoStep);
createRetentionLeaseStep.whenComplete(retentionLease -> { final long lastKnownGlobalCheckpoint = shard.getLastKnownGlobalCheckpoint(); assert retentionLease == null || retentionLease.retainingSequenceNumber() - 1 <= lastKnownGlobalCheckpoint : retentionLease + " vs " + lastKnownGlobalCheckpoint; // Establishes new empty translog on the replica with global checkpoint set to lastKnownGlobalCheckpoint. We want // the commit we just copied to be a safe commit on the replica, so why not set the global checkpoint on the replica // to the max seqno of this commit? Because (in rare corner cases) this commit might not be a safe commit here on // the primary, and in these cases the max seqno would be too high to be valid as a global checkpoint. cleanFiles(store, recoverySourceMetadata, translogOps, lastKnownGlobalCheckpoint, cleanFilesStep); }, listener::onFailure);
final long totalSize = totalSizeInBytes; final long existingTotalSize = existingTotalSizeInBytes; cleanFilesStep.whenComplete(r -> { final TimeValue took = stopWatch.totalTime(); logger.trace("recovery [phase1]: took [{}]", took); listener.onResponse(new SendFileResult(phase1FileNames, phase1FileSizes, totalSize, phase1ExistingFileNames, phase1ExistingFileSizes, existingTotalSize, took)); }, listener::onFailure); } else { logger.trace("skipping [phase1] since source and target have identical sync id [{}]", recoverySourceMetadata.getSyncId());
// but we must still create a retention lease final StepListener<RetentionLease> createRetentionLeaseStep = new StepListener<>(); createRetentionLease(startingSeqNo, createRetentionLeaseStep); createRetentionLeaseStep.whenComplete(retentionLease -> { final TimeValue took = stopWatch.totalTime(); logger.trace("recovery [phase1]: took [{}]", took); listener.onResponse(new SendFileResult(Collections.emptyList(), Collections.emptyList(), 0L, Collections.emptyList(), Collections.emptyList(), 0L, took)); }, listener::onFailure);
} } catch (Exception e) { throw new RecoverFilesRecoveryException(request.shardId(), 0, new ByteSizeValue(0L), e); } }
/** * Returns a diff between the two snapshots that can be used for recovery. The given snapshot is treated as the * recovery target and this snapshot as the source. The returned diff will hold a list of files that are: * <ul> * <li>identical: they exist in both snapshots and they can be considered the same ie. they don't need to be recovered</li> * <li>different: they exist in both snapshots but their they are not identical</li> * <li>missing: files that exist in the source but not in the target</li> * </ul> * This method groups file into per-segment files and per-commit files. A file is treated as * identical if and on if all files in it's group are identical. On a per-segment level files for a segment are treated * as identical iff: * <ul> * <li>all files in this segment have the same checksum</li> * <li>all files in this segment have the same length</li> * <li>the segments {@code .si} files hashes are byte-identical Note: This is a using a perfect hash function, * The metadata transfers the {@code .si} file content as it's hash</li> * </ul> * <p> * The {@code .si} file contains a lot of diagnostics including a timestamp etc. in the future there might be * unique segment identifiers in there hardening this method further. * <p> * The per-commit files handles very similar. A commit is composed of the {@code segments_N} files as well as generational files * like deletes ({@code _x_y.del}) or field-info ({@code _x_y.fnm}) files. On a per-commit level files for a commit are treated * as identical iff: * <ul> * <li>all files belonging to this commit have the same checksum</li> * <li>all files belonging to this commit have the same length</li> * <li>the segments file {@code segments_N} files hashes are byte-identical Note: This is a using a perfect hash function, * The metadata transfers the {@code segments_N} file content as it's hash</li> * </ul> * <p> * NOTE: this diff will not contain the {@code segments.gen} file. This file is omitted on recovery. */ public RecoveryDiff recoveryDiff(MetadataSnapshot recoveryTargetSnapshot) { final List<StoreFileMetadata> identical = new ArrayList<>();// 相同的file final List<StoreFileMetadata> different = new ArrayList<>();// 不同的file final List<StoreFileMetadata> missing = new ArrayList<>();// 缺失的file final Map<String, List<StoreFileMetadata>> perSegment = new HashMap<>(); final List<StoreFileMetadata> perCommitStoreFiles = new ArrayList<>();
for (StoreFileMetadata meta : this) { if (IndexFileNames.OLD_SEGMENTS_GEN.equals(meta.name())) { // legacy continue; // we don't need that file at all } final String segmentId = IndexFileNames.parseSegmentName(meta.name()); final String extension = IndexFileNames.getExtension(meta.name()); if (IndexFileNames.SEGMENTS.equals(segmentId) || DEL_FILE_EXTENSION.equals(extension) || LIV_FILE_EXTENSION.equals(extension)) { // only treat del files as per-commit files fnm files are generational but only for upgradable DV perCommitStoreFiles.add(meta); } else { perSegment.computeIfAbsent(segmentId, k -> new ArrayList<>()).add(meta); } } final ArrayList<StoreFileMetadata> identicalFiles = new ArrayList<>(); for (List<StoreFileMetadata> segmentFiles : Iterables.concat(perSegment.values(), Collections.singleton(perCommitStoreFiles))) { identicalFiles.clear(); boolean consistent = true; for (StoreFileMetadata meta : segmentFiles) { StoreFileMetadata storeFileMetadata = recoveryTargetSnapshot.get(meta.name()); if (storeFileMetadata == null) { consistent = false; missing.add(meta);// 该segment在target node中不存在,则加入到missing } else if (storeFileMetadata.isSame(meta) == false) { consistent = false; different.add(meta);// 存在但不相同,则加入到different } else { identicalFiles.add(meta);// 存在且相同 } } if (consistent) { identical.addAll(identicalFiles); } else { // make sure all files are added - this can happen if only the deletes are different different.addAll(identicalFiles); } } RecoveryDiff recoveryDiff = new RecoveryDiff(Collections.unmodifiableList(identical), Collections.unmodifiableList(different), Collections.unmodifiableList(missing)); assert recoveryDiff.size() == this.metadata.size() - (metadata.containsKey(IndexFileNames.OLD_SEGMENTS_GEN) ? 1 : 0) : "some files are missing recoveryDiff size: [" + recoveryDiff.size() + "] metadata size: [" + this.metadata.size() + "] contains segments.gen: [" + metadata.containsKey(IndexFileNames.OLD_SEGMENTS_GEN) + "]"; return recoveryDiff; }
/** * Perform phase two of the recovery process. * <p> * Phase two uses a snapshot of the current translog *without* acquiring the write lock (however, the translog snapshot is * point-in-time view of the translog). It then sends each translog operation to the target node so it can be replayed into the new * shard. * * @param startingSeqNo the sequence number to start recovery from, or {@link SequenceNumbers#UNASSIGNED_SEQ_NO} if all * ops should be sent * @param endingSeqNo the highest sequence number that should be sent * @param snapshot a snapshot of the translog * @param maxSeenAutoIdTimestamp the max auto_id_timestamp of append-only requests on the primary * @param maxSeqNoOfUpdatesOrDeletes the max seq_no of updates or deletes on the primary after these operations were executed on it. * @param listener a listener which will be notified with the local checkpoint on the target. */ void phase2( final long startingSeqNo, final long endingSeqNo, final Translog.Snapshot snapshot, final long maxSeenAutoIdTimestamp, final long maxSeqNoOfUpdatesOrDeletes, final RetentionLeases retentionLeases, final long mappingVersion, final ActionListener<SendSnapshotResult> listener) throws IOException { if (shard.state() == IndexShardState.CLOSED) { throw new IndexShardClosedException(request.shardId()); } logger.trace("recovery [phase2]: sending transaction log operations (from [" + startingSeqNo + "] to [" + endingSeqNo + "]"); final StopWatch stopWatch = new StopWatch().start(); final StepListener<Void> sendListener = new StepListener<>(); final OperationBatchSender sender = new OperationBatchSender(startingSeqNo, endingSeqNo, snapshot, maxSeenAutoIdTimestamp, maxSeqNoOfUpdatesOrDeletes, retentionLeases, mappingVersion, sendListener); sendListener.whenComplete( ignored -> { final long skippedOps = sender.skippedOps.get(); final int totalSentOps = sender.sentOps.get(); final long targetLocalCheckpoint = sender.targetLocalCheckpoint.get(); assert snapshot.totalOperations() == snapshot.skippedOperations() + skippedOps + totalSentOps : String.format(Locale.ROOT, "expected total [%d], overridden [%d], skipped [%d], total sent [%d]", snapshot.totalOperations(), snapshot.skippedOperations(), skippedOps, totalSentOps); stopWatch.stop(); final TimeValue tookTime = stopWatch.totalTime(); logger.trace("recovery [phase2]: took [{}]", tookTime); listener.onResponse(new SendSnapshotResult(targetLocalCheckpoint, totalSentOps, tookTime)); }, listener::onFailure); sender.start(); }
/** * Opens the engine on top of the existing lucene engine and translog. * The translog is kept but its operations won't be replayed. */ public void openEngineAndSkipTranslogRecovery() throws IOException { assert routingEntry().recoverySource().getType() == RecoverySource.Type.PEER : "not a peer recovery [" + routingEntry() + "]"; recoveryState.validateCurrentStage(RecoveryState.Stage.TRANSLOG); loadGlobalCheckpointToReplicationTracker(); innerOpenEngineAndTranslog(replicationTracker); getEngine().skipTranslogRecovery(); }
private void innerOpenEngineAndTranslog(LongSupplier globalCheckpointSupplier) throws IOException { assert Thread.holdsLock(mutex) == false : "opening engine under mutex"; if (state != IndexShardState.RECOVERING) { throw new IndexShardNotRecoveringException(shardId, state); } final EngineConfig config = newEngineConfig(globalCheckpointSupplier);
// we disable deletes since we allow for operations to be executed against the shard while recovering // but we need to make sure we don't loose deletes until we are done recovering config.setEnableGcDeletes(false);// 恢复过程中不删除translog updateRetentionLeasesOnReplica(loadRetentionLeases()); assert recoveryState.getRecoverySource().expectEmptyRetentionLeases() == false || getRetentionLeases().leases().isEmpty() : "expected empty set of retention leases with recovery source [" + recoveryState.getRecoverySource() + "] but got " + getRetentionLeases(); synchronized (engineMutex) { assert currentEngineReference.get() == null : "engine is running"; verifyNotClosed(); // we must create a new engine under mutex (see IndexShard#snapshotStoreMetadata). final Engine newEngine = engineFactory.newReadWriteEngine(config);// 创建engine onNewEngine(newEngine); currentEngineReference.set(newEngine); // We set active because we are now writing operations to the engine; this way, // we can flush if we go idle after some time and become inactive. active.set(true); } // time elapses after the engine is created above (pulling the config settings) until we set the engine reference, during // which settings changes could possibly have happened, so here we forcefully push any config changes to the new engine. onSettingsChanged(); assert assertSequenceNumbersInCommit(); recoveryState.validateCurrentStage(RecoveryState.Stage.TRANSLOG); }
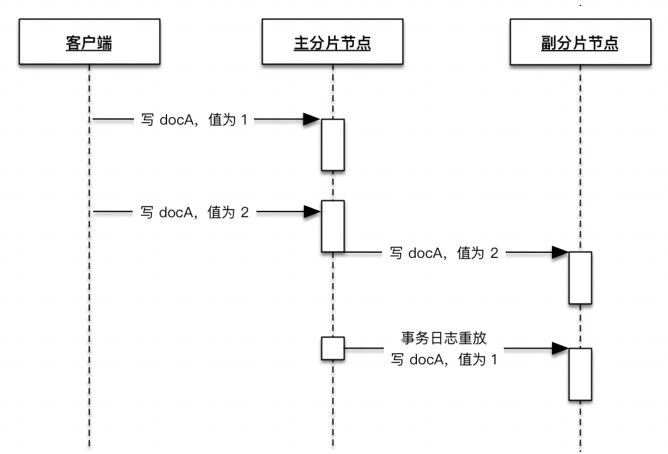
// 重放translog快照中的translog操作到当前引擎。 // 在成功回放每个translog操作后,会通知回调onOperationRecovered。 /** * Replays translog operations from the provided translog {@code snapshot} to the current engine using the given {@code origin}. * The callback {@code onOperationRecovered} is notified after each translog operation is replayed successfully. */ int runTranslogRecovery(Engine engine, Translog.Snapshot snapshot, Engine.Operation.Origin origin, Runnable onOperationRecovered) throws IOException { int opsRecovered = 0; Translog.Operation operation; while ((operation = snapshot.next()) != null) { try { logger.trace("[translog] recover op {}", operation); Engine.Result result = applyTranslogOperation(engine, operation, origin); switch (result.getResultType()) { case FAILURE: throw result.getFailure(); case MAPPING_UPDATE_REQUIRED: throw new IllegalArgumentException("unexpected mapping update: " + result.getRequiredMappingUpdate()); case SUCCESS: break; default: throw new AssertionError("Unknown result type [" + result.getResultType() + "]"); }
opsRecovered++; onOperationRecovered.run(); } catch (Exception e) { // TODO: Don't enable this leniency unless users explicitly opt-in if (origin == Engine.Operation.Origin.LOCAL_TRANSLOG_RECOVERY && ExceptionsHelper.status(e) == RestStatus.BAD_REQUEST) { // mainly for MapperParsingException and Failure to detect xcontent logger.info("ignoring recovery of a corrupt translog entry", e); } else { throw ExceptionsHelper.convertToRuntime(e); } } } return opsRecovered; }
private Engine.Result applyTranslogOperation(Engine engine, Translog.Operation operation, Engine.Operation.Origin origin) throws IOException { // If a translog op is replayed on the primary (eg. ccr), we need to use external instead of null for its version type. final VersionType versionType = (origin == Engine.Operation.Origin.PRIMARY) ? VersionType.EXTERNAL : null; final Engine.Result result; switch (operation.opType()) {// 还原出操作类型及操作数据并调用engine执行相应的动作 case INDEX: final Translog.Index index = (Translog.Index) operation; // we set canHaveDuplicates to true all the time such that we de-optimze the translog case and ensure that all // autoGeneratedID docs that are coming from the primary are updated correctly. result = applyIndexOperation(engine, index.seqNo(), index.primaryTerm(), index.version(), versionType, UNASSIGNED_SEQ_NO, 0, index.getAutoGeneratedIdTimestamp(), true, origin, new SourceToParse(shardId.getIndexName(), index.id(), index.source(), XContentHelper.xContentType(index.source()), index.routing())); break; case DELETE: final Translog.Delete delete = (Translog.Delete) operation; result = applyDeleteOperation(engine, delete.seqNo(), delete.primaryTerm(), delete.version(), delete.id(), versionType, UNASSIGNED_SEQ_NO, 0, origin); break; case NO_OP: final Translog.NoOp noOp = (Translog.NoOp) operation; result = markSeqNoAsNoop(engine, noOp.seqNo(), noOp.primaryTerm(), noOp.reason(), origin); break; default: throw new IllegalStateException("No operation defined for [" + operation + "]"); } return result; }
/** * perform the last stages of recovery once all translog operations are done. * note that you should still call {@link #postRecovery(String)}. */ public void finalizeRecovery() { recoveryState().setStage(RecoveryState.Stage.FINALIZE); Engine engine = getEngine(); engine.refresh("recovery_finalization"); engine.config().setEnableGcDeletes(true); }
/** * the status of the current doc version in lucene, compared to the version in an incoming * operation */ enum OpVsLuceneDocStatus { /** the op is more recent than the one that last modified the doc found in lucene*/ OP_NEWER, /** the op is older or the same as the one that last modified the doc found in lucene*/ OP_STALE_OR_EQUAL, /** no doc was found in lucene */ LUCENE_DOC_NOT_FOUND }