基于OpenJDK 12
阅读本文前,推荐先阅读以下两篇文章,以便能更好的对比理解:
LongAdder是JDK 1.8 新增的原子类,基于Striped64实现。 从官方文档看,LongAdder在高并发的场景下会比AtomicLong 具有更好的性能,代价是消耗更多的内存空间:
This class is usually preferable to AtomicLong when multiple threads update a common sum that is used for purposes such as collecting statistics, not for fine-grained synchronization control. Under low update contention, the two classes have similar characteristics. But under high contention, expected throughput of this class is significantly higher, at the expense of higher space consumption.
那么LongAdder是怎么实现的?
先看一下LongAdder的类图: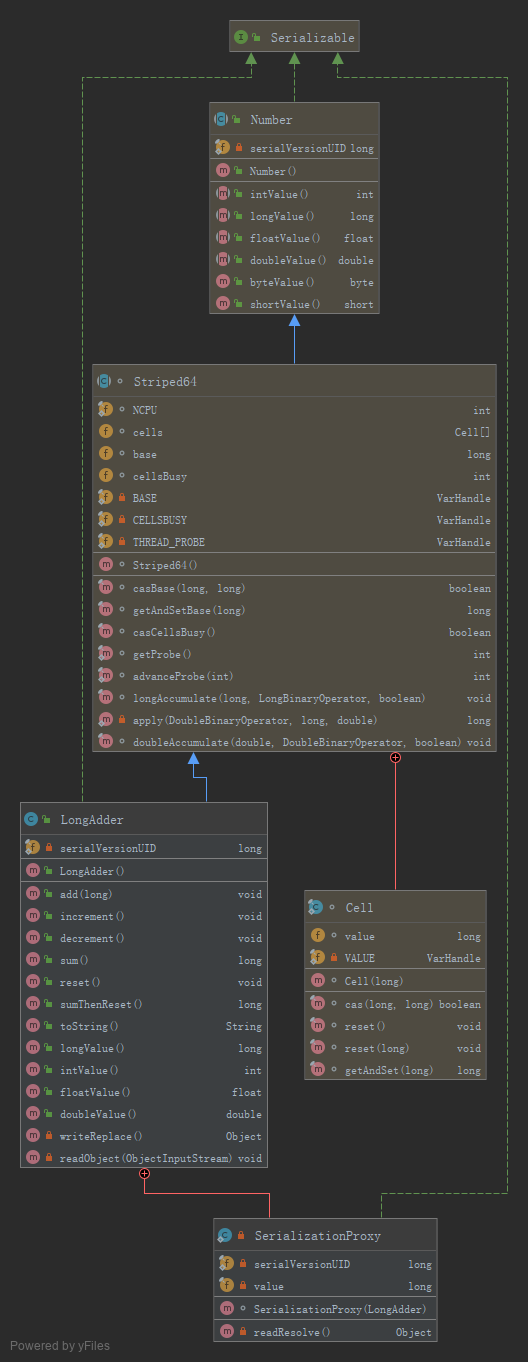
基类Number,Number是一个抽象类其中没有任何逻辑,该类是byte、double、float、int、long、short的基类。
Striped64
设计思想
该部分翻译自Striped64源码注释,可以略过,概括起来就是:
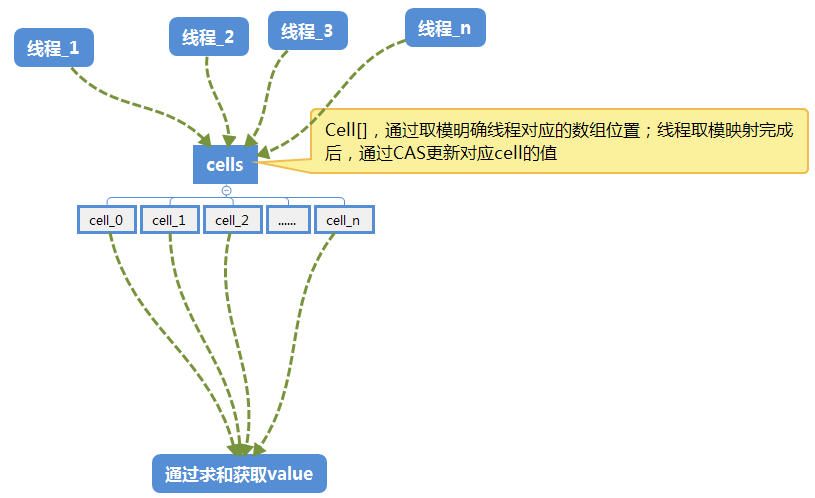
分散热点,将value值分散到一个数组中,不同线程会命中到数组的不同槽中,各个线程只对自己槽中的那个值进行CAS操作,这样热点就被分散了,冲突的概率就小很多。如果要获取真正的long值,只要将各个槽中的变量值累加返回。
从Striped64类注释可以看到:
Striped64是package内使用的,对于在64位元素上动态分片提供统一实现(感觉有点像:AbstractQueuedSynchronizer)
Striped64继承了Number类,这也就是说具体实现的子类也必须实现相关的内容
该类维护一个原子更新变量的延迟初始化表,以及一个额外的“base”字段。表的大小是2的幂。索引使用掩码下的每个线程的hash code。这个类中的几乎所有声明都是package私有的,由子类直接访问。
表格内的元素是Cell类,Cell类是一个为了减少缓存争用而填充的AtomicLong的变种。填充对于大多数原子来说是多余的,因为它们通常不规则地分散在内存中,因此彼此之间不会有太多的干扰。但是,驻留在数组中的原子对象往往是彼此相邻的,因此在没有这种预防措施的情况下,最常见的情况是共享高速缓存线(这对性能有很大的负面影响)。
在某种程度上,因为Cell类相对较大,只有他们真正被需要的时候,我们才创建。如果没有竞争,那么所有的更新操作将对base字段实现。当发生第一次争用(也就是说如果第一次对base字段的CAS操作失败),初始化为大小是2的表格。当进一步的争用发生的时候,表的大小会加倍,直到达到等于大于cpu的数量。表在未使用之前一直为null。
利用一个自旋锁(cellsBusy)来初始化和调整表的大小,以及用新Cells填充slots。这个地方没有必要使用阻塞锁,如果锁不可达,线程可以尝试其他的slots,或者尝试base字段。在这些重试期间,竞争加剧,但是降低了局部性,这仍然比阻塞锁来得好。
通过ThreadLocalRandom维护的Thread.probe字段用作每个线程的哈希码。我们让它们保持未初始化(为零)(如果它们以这种方式出现),直到它们在插槽0竞争。出现竞争后初始化为通常不会和其他的的值冲突的值,比如线程的哈希码。在执行更新时发生CAS操作失败意味着出现了争用或者表碰撞,或两者都有。在发生冲突时,如果表的大小小于容量,那么它的大小将加倍,除非其他线程持有锁。如果哈希后的slot为空,并且锁可用,则创建一个新单元格。如果存在了那么会进行CAS尝试。通过双重哈希进行重试,利用一个辅助哈希(Marsaglia XorShift随机数算法)来尝试寻找一个空闲的slot。
表的大小是有上限的,因为当线程多于CPU时,假设每个线程都绑定到一个CPU,就会有一个完美的散列函数将线程映射到插槽,从而消除冲突。当我们达到容量时,我们通过随机改变冲突线程的哈希代码来搜索这个映射。因为搜索是随机的,冲突只有通过CAS失败才知道,收敛可能会很慢,而且因为线程通常不会永远绑定到CPU,所以根本不会发生。然而,尽管有这些限制,在这些情况下观察到的竞争率通常很低。
Cell可能会出现不可用的情况,包括进行哈希的线程终止,或者由于table扩容导致线程哈希不正确。我们不尝试检测或删除这样的单元格,假设对于长时间运行的实例,争用会再次发生,因此最终将再次需要这些单元格;而对于短时间运行的实例,花费时间去销毁又没有什么必要。
Cell类
Atomiclong的变体,仅支持原始访问和CAS。
Cell类被注解@jdk.internal.vm.annotation.Contended修饰。
Contended的作用(详细信息参见:JEP 142):
Define a way to specify that one or more fields in an object are likely to be highly contended across processor cores so that the VM can arrange for them not to share cache lines with other fields, or other objects, that are likely to be independently accessed.
示意图
具体实现
Striped64的核心方法是longAccumulate、doubleAccumulate,两者类似,下面主要看一下longAccumulate,对于这种代码,个人建议是理解思路即可,毕竟咱们又不是过来修改JDK的,如果真的要修改了或者有类似的需求了,再回来细看即可。
1 | //x 元素 |
这一段的核心是这样的:
- longAccumulate会根据当前线程来计算一个哈希值,然后根据(hashCode & (length - 1))取模,以定位到该线程被分散到的Cell数组中的位置
- 如果Cell数组还没有被创建,那么就去获取cellBusy这个锁(相当于锁,但是更为轻量级),如果获取成功,则初始化Cell数组,初始容量为2,初始化完成之后将x包装成一个Cell,哈希计算之后分散到相应的index上。如果获取cellBusy失败,那么会试图将x累计到base上,更新失败会重新尝试直到成功。
- 如果Cell数组已经被初始化过了,那么就根据线程的哈希值分散到一个Cell数组元素上,获取这个位置上的Cell并且赋值给变量a,如果a为null,说明该位置还没有被初始化,那么就初始化,当然在初始化之前需要竞争cellBusy变量。
- 如果Cell数组的大小已经最大了(大于等于CPU的数量),那么就需要重新计算哈希,来重新分散当前线程到另外一个Cell位置上再走一遍该方法的逻辑,否则就需要对Cell数组进行扩容,然后将原来的计数内容迁移过去。由于Cell里面保存的是计数值,所以扩容后没有必要做其他处理,直接根据index将旧的Cell数组内容复制到新的Cell数组中。
LongAdder
LongAdder的基本思路就是分散热点,将value值分散到一个数组中,不同线程会命中到数组的不同槽中,各个线程只对自己槽中的那个值进行CAS操作,这样热点就被分散了,冲突的概率就小很多。如果要获取真正的long值,只要将各个槽中的变量值累加返回。
说明
保持一个或者多个变量,初始值设置为零用于求和。当更新出现多个线程竞争时,变量集合动态增长以减少争用。最后当需要求和的时候或者说需要这个Long型的值时,可以通过把当前这些变量求和,合并后得出最终的和。
LongAdder在一些高并发场景下表现要比AtomicLong好,比如多个线程同时更新一个求和的变量,比如统计集合的数量,但是不能用于细粒度同步控制,换句话说这个是可能有误差的(因为更新与读取是并行的)。在低并发场景场景下LongAdder和AtomicLong的性能表现没什么差别,但是当高并发竞争的时候,这个类将具备更好的吞吐性能,但是相应的也会耗费相当的空间。
LongAdder继承了Number抽象类,但是并没有实现一些方法例如: equals、hashCode、compareTo,因为LongAdder实例的预期用途是进行一些比较频繁的变化,所以也不适合作为集合的key。
具体实现
看一下LongAdder有哪些方法: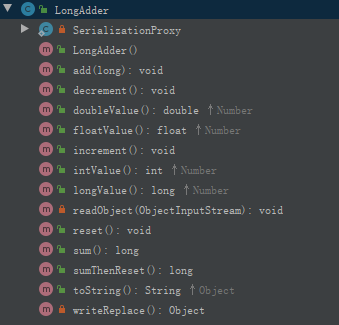
下面主要解析LongAdder increment、sum方法,先看一下源码:
1 | /** |
LongAdder vs AtomicLong Performance
Java 8 Performance Improvements: LongAdder vs AtomicLong
对比LongAccumulator
LongAdder类可以看做是LongAccumulator的一个特例,LongAccumulator提供了比LongAdder更强大、灵活的功能。
1 | /** |
构造函数其中accumulatorFunction一个双目运算接口,根据输入的两个参数返回一个计算值,identity则是LongAccumulator累加器的初始值。
accumulatorFunction主要用于Striped64 longAccumulate中使用,如果fn==null,则默认是相加,否则会调用fn.applyAsLong(v, x)
LongAccumulator相比于LongAdder,可以为累加器提供非0的初始值,而LongAdder只能提供默认的0值。
另外,LongAccumulator还可以指定累加规则,比如累加或者相乘,只需要在构造LongAccumulator时,传入自定义的双目运算器即可,后者则内置累加规则。
Reference
https://www.jianshu.com/p/9a7de5644dd4
http://openjdk.java.net/jeps/142
http://mail.openjdk.java.net/pipermail/hotspot-dev/2012-November/007309.html

