当你在浏览器中输入 google.com 并且按下回车之后发生了什么?
整理自 https://github.com/skyline75489/what-happens-when-zh_CN
Java Volatile的内存语义与AQS锁内存可见性
提到volatile首先想到就是:
- 保证此变量对所有线程的可见性,这里的 “可见性”是指当一个线程修改了这个变量的值,新值对于其他线程来说是可以立即得知的。
- 禁止指令重排序优化。
到这里大家感觉自己对volatile理解了吗?
如果理解了,大家考虑这么一个问题:ReentrantLock(或者其它基于AQS实现的锁)是如何保证代码段中变量(变量主要是指共享变量,存在竞争问题的变量)的可见性?
1 | private static ReentrantLock reentrantLock = new ReentrantLock(); |
既然提到了可见性,那就先熟悉几个概念:
JMM
JMM:Java Memory Model 即 Java 内存模型
The Java Memory Model describes what behaviors are legal in multithreaded code, and how threads may interact through memory.
It describes the relationship between variables in a program and the low-level details of storing and retrieving them to and from memory or registers in a real computer system.
It does this in a way that can be implemented correctly using a wide variety of hardware and a wide variety of compiler optimizations.
Java内存模型的主要目标是定义程序中各个变量的访问规则,即在虚拟机中将变量存储到内存和从内存中取出变量这样的底层细节。此处的变量主要是指共享变量,存在竞争问题的变量。Java内存模型规定所有的变量都存储在主内存中,而每个线程还有自己的工作内存,线程的工作内存中保存了该线程使用到的变量的主内存副本拷贝,线程对变量的所有操作(读取、赋值等)都必须在工作内存中进行,而不能直接读写主内存中的变量(根据Java虚拟机规范的规定,volatile变量依然有共享内存的拷贝,但是由于它特殊的操作顺序性规定——从工作内存中读写数据前,必须先将主内存中的数据同步到工作内存中,所有看起来如同直接在主内存中读写访问一般,因此这里的描述对于volatile也不例外)。不同线程之间也无法直接访问对方工作内存中的变量,线程间变量值得传递均需要通过主内存来完成。
重排序
在执行程序时,为了提高性能,编译器和处理器常常会对指令做重排序。重排序分3种类型:
- 编译器优化的重排序。编译器在不改变单线程程序语义的前提下,可以重新安排语句的执行顺序。
- 指令级并行的重排序。现代处理器采用了指令级并行技术(Instruction-Level Parallelism,ILP)来将多条指令重叠执行。如果不存在数据依赖性,处理器可以改变语句对应机器指令的执行顺序。
- 内存系统的重排序。由于处理器使用缓存和读/写缓冲区,这使得加载和存储操作看上去可能是在乱序执行。
从Java源代码到最终实际执行的指令序列,会分别经历下面3种重排序:

对于编译器,JMM的编译器重排序规则会禁止特定类型的编译器重排序(不是所有的编译器重排序都要禁止)。对于处理器重排序,JMM的处理器重排序规则会要求Java编译器在生成指令序列时,插入特定类型的内存屏障(Memory Barriers,Intel称之为Memory Fence)指令,通过内存屏障指令来禁止特定类型的处理器重排序。
JMM属于语言级的内存模型,它确保在不同的编译器和不同的处理器平台之上,通过禁止特定类型的编译器重排序和处理器重排序,为程序员提供一致的内存可见性保证。
happens-before
- 程序顺序规则:一个线程中的每个操作,happens-before于该线程中的任意后续操作。
- 监视器锁规则:对一个锁的解锁,happens-before于随后对这个锁的加锁。
- volatile变量规则:对一个volatile域的写,happens-before于任意后续对这个volatile域的读。(对一个volatile变量的读,总是能看到【任意线程】对这个volatile变量最后的写入)
- 传递性:如果A happens-before B,且B happens-before C,那么A happens-before C。
两个操作之间具有happens-before关系,并不意味着前一个操作必须要在后一个操作之前执行!happens-before仅仅要求前一个操作(执行的结果)对后一个操作可见,且前一个操作按顺序排在第二个操作之前(the first is visible to and ordered before the second)。
内存屏障
- 硬件层的内存屏障分为两种:Load Barrier 和 Store Barrier即读屏障和写屏障。
- 对于Load Barrier来说,在指令前插入Load Barrier,可以让高速缓存中的数据失效,强制从新从主内存加载数据;
- 对于Store Barrier来说,在指令后插入Store Barrier,能让写入缓存中的最新数据更新写入主内存,让其他线程可见。
- 内存屏障有两个作用:
- 阻止屏障两侧的指令重排序;
- 强制把写缓冲区/高速缓存中的数据等写回主内存,让缓存中相应的数据失效。
volatile的内存语义
从JSR-133开始(即从JDK5开始),volatile变量的写-读可以实现线程之间的通信。
从内存语义的角度来说,volatile的写-读与锁的释放-获取有相同的内存效果:
- volatile写和锁的释放有相同的内存语义;
- volatile读与锁的获取有相同的内存语义。
volatile仅仅保证对单个volatile变量的读/写具有原子性,而锁的互斥执行的特性可以确保对整个临界区代码的执行具有原子性。在功能上,锁比volatile更强大;在可伸缩性和执行性能上,volatile更有优势。
volatile变量自身具有下列特性:
- 可见性。对一个volatile变量的读,总是能看到(任意线程)对这个volatile变量最后的写入。
- 原子性:对任意单个volatile变量的读/写具有原子性,即使是64位的long型和double型变量,只要它是volatile变量,对该变量的读/写就具有原子性。如果是多个volatile操作或类似于volatile++这种复合操作,这些操作整体上不具有原子性。
volatile写和volatile读的内存语义:
- 线程A写一个volatile变量,实质上是线程A向接下来将要读这个volatile变量的某个线程发出了(其对共享变量所做修改的)消息。
- 线程B读一个volatile变量,实质上是线程B接收了之前某个线程发出的(在写这个volatile变量之前对共享变量所做修改的)消息。
- 线程A写一个volatile变量,随后线程B读这个volatile变量,这个过程实质上是线程A通过主内存向线程B发送消息。
JMM针对编译器制定的volatile重排序规则表

- 当第二个操作是volatile写时,不管第一个操作是什么,都不能重排序。这个规则确保volatile写之前的操作不会被编译器重排序到volatile写之后。
- 当第一个操作是volatile读时,不管第二个操作是什么,都不能重排序。这个规则确保volatile读之后的操作不会被编译器重排序到volatile读之前。
- 当第一个操作是volatile写,第二个操作是volatile读时,不能重排序。
为了实现volatile的内存语义,编译器在生成字节码时,会在指令序列中插入内存屏障来禁止特定类型的处理器重排序。对于编译器来说,发现一个最优布置来最小化插入屏障几乎是不可能的。为此,JMM采取保守策略。下面是基于保守策略的JMM内存屏障插入策略。
- 在每个volatile写操作的前面插入一个StoreStore屏障。
- 在每个volatile写操作的后面插入一个StoreLoad屏障。
- 在每个volatile读操作的后面插入一个LoadLoad屏障。
- 在每个volatile读操作的后面插入一个LoadStore屏障。
LoadLoad屏障:对于这样的语句Load1; LoadLoad; Load2,在Load2及后续读取操作要读取的数据被访问前,保证Load1要读取的数据被读取完毕。
StoreStore屏障:对于这样的语句Store1; StoreStore; Store2,在Store2及后续写入操作执行前,保证Store1的写入操作对其它处理器可见。 LoadStore屏障:对于这样的语句Load1; LoadStore; Store2,在Store2及后续写入操作被刷出前,保证Load1要读取的数据被读取完毕。
StoreLoad屏障:对于这样的语句Store1; StoreLoad; Load2,在Load2及后续所有读取操作执行前,保证Store1的写入对所有处理器可见。它的开销是四种屏障中最大的。在大多数处理器的实现中,这个屏障是个万能屏障,兼具其它三种内存屏障的功能。
上述内存屏障插入策略非常保守,但它可以保证在任意处理器平台,任意的程序中都能得到正确的volatile内存语义。
下面是保守策略下,volatile写插入内存屏障后生成的指令序列示意图.
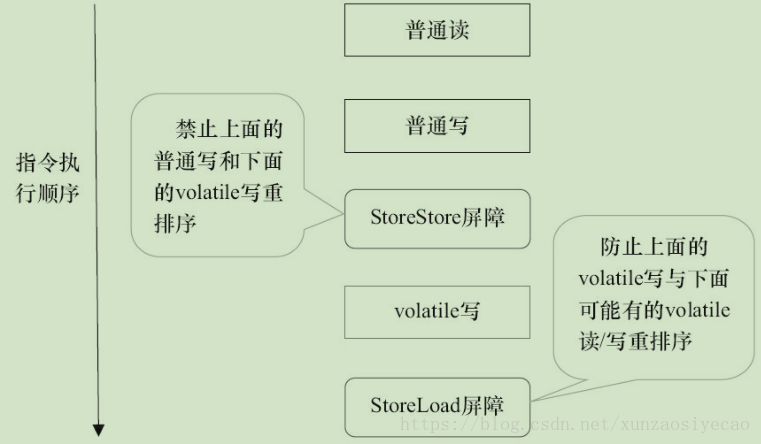
图中的StoreStore屏障可以保证在volatile写之前,其前面的所有普通写操作已经对任意处理器可见了。这是因为StoreStore屏障将保障上面所有的普通写在volatile写之前刷新到主内存。
这里比较有意思的是,volatile写后面的StoreLoad屏障。此屏障的作用是避免volatile写与后面可能有的volatile读/写操作重排序。因为编译器常常无法准确判断在一个volatile写的后面是否需要插入一个StoreLoad屏障(比如,一个volatile写之后方法立即return)。为了保证能正确实现volatile的内存语义,JMM在采取了保守策略:在每个volatile写的后面,或者在每个volatile读的前面插入一个StoreLoad屏障。从整体执行效率的角度考虑,JMM最终选择了在每个volatile写的后面插入一个StoreLoad屏障。因为volatile写-读内存语义的常见使用模式是:一个写线程写volatile变量,多个读线程读同一个volatile变量。当读线程的数量大大超过写线程时,选择在volatile写之后插入StoreLoad屏障将带来可观的执行效率的提升。从这里可以看到JMM在实现上的一个特点:首先确保正确性,然后再去追求执行效率。
下面是在保守策略下,volatile读插入内存屏障后生成的指令序列示意图: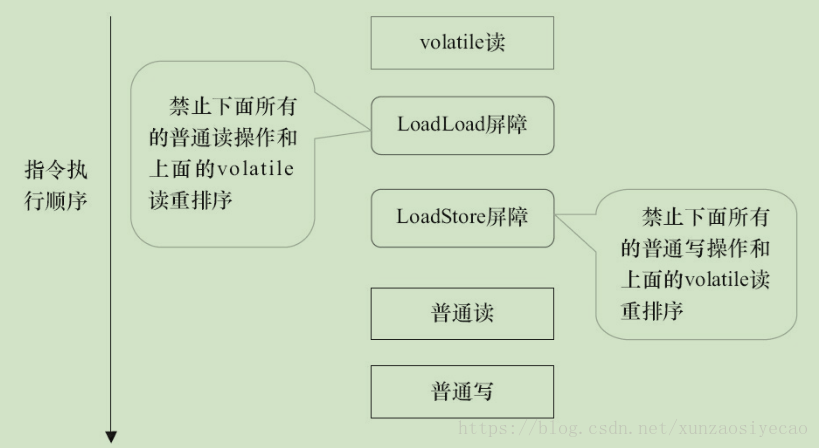
图中的LoadLoad屏障用来禁止处理器把上面的volatile读与下面的普通读重排序。LoadStore屏障用来禁止处理器把上面的volatile读与下面的普通写重排序。
上述volatile写和volatile读的内存屏障插入策略非常保守。在实际执行时,只要不改变volatile写-读的内存语义,编译器可以根据具体情况省略不必要的屏障。
AQS
对于AQS需要了解这么几点:
- 锁的状态通过volatile int state来表示。
- 获取不到锁的线程会进入AQS的队列等待。
- 子类需要重写tryAcquire、tryRelease等方法。
AQS 详解参见:面试必备:Java AQS 实现原理(图文)分析
ReentrantLock
以公平锁为例,看看 ReentrantLock 获取锁 & 释放锁的关键代码:
1 | /** |
通过ReentrantLock实例调用lock()、unlock()时,acquires、releases的值都是1。
公平锁在释放锁的最后写volatile变量state,在获取锁时首先读这个volatile变量。根据volatile的happens-before规则,释放锁的线程在写volatile变量之前可见的共享变量,在获取锁的线程读取同一个volatile变量后将立即变得对获取锁的线程可见。从而保证了代码段中变量(变量主要是指共享变量,存在竞争问题的变量)的可见性。
小结
如果我们仔细分析concurrent包的源代码实现,会发现一个通用化的实现模式。
- 首先,声明共享变量为volatile。
- 然后,使用CAS的原子条件更新来实现线程之间的同步。
- 同时,配合以volatile的读/写和CAS所具有的volatile读和写的内存语义来实现线程之间的通信。
前文我们提到过,编译器不会对volatile读与volatile读后面的任意内存操作重排序;编译器不会对volatile写与volatile写前面的任意内存操作重排序。组合这两个条件,意味着为了同时实现volatile读和volatile写的内存语义,编译器不能对CAS与CAS前面和后面的任意内存操作重排序。
推荐阅读:
https://jiankunking.com/java-volatile-keyword.html
本文参考:
1、《Java并发编程的艺术》 方腾飞 魏鹏 程晓明 著
Java Lambda表达式 实现原理分析
本文分析基于JDK 9
Java AQS 实现原理(图文)分析
AQS:AbstractQueuedSynchronizer
1、AQS设计简介
- AQS的实现是基于一个FIFO的等待队列。
- 使用单个原子变量来表示获取、释放锁状态(final int)改变该int值使用的是CAS。(思考:为什么一个int值可以保证内存可见性?)
- 子类应该定义一个非公开的内部类继承AQS,并实现其中方法。
- AQS支持exclusive与shared两种模式。
- 内部类ConditionObject用于支持子类实现exclusive模式
- 子类需要重写:
- tryAcquire
- tryRelease
- tryReleaseShared
- isHeldExclusively等方法,并确保是线程安全的。
贯穿全文的图(核心):

模板方法设计模式:定义一个操作中算法的骨架,而将一些步骤的实现延迟到子类中。
2、类结构
- ConditionObject类
- Node类
- N多方法

3、FIFO队列
等待队列是CLH(Craig, Landin, and Hagersten)锁队列。
通过节点中的“状态”字段来判断一个线程是否应该阻塞。当该节点的前一个节点释放锁的时候,该节点会被唤醒。

1 | private transient volatile Node head; |
AQS维护了一个volatile int state(代表共享资源)和一个FIFO线程等待队列(多线程争用资源被阻塞时会进入此队列)。
state的访问方式有三种:
- getState()
- setState()
- compareAndSetState()
AQS定义两种资源共享方式:Exclusive(独占,只有一个线程能执行,如ReentrantLock)和Share(共享,多个线程可同时执行,如Semaphore/CountDownLatch)。
不同的自定义同步器争用共享资源的方式也不同。自定义同步器在实现时只需要实现共享资源state的获取与释放方式即可,至于具体线程等待队列的维护(如获取资源失败入队/唤醒出队等),AQS已经在顶层实现好了。
自定义同步器实现时主要实现以下几种方法:
- isHeldExclusively():该线程是否正在独占资源。只有用到condition才需要去实现它。
- tryAcquire(int):独占方式。尝试获取资源,成功则返回true,失败则返回false。
- tryRelease(int):独占方式。尝试释放资源,成功则返回true,失败则返回false。
- tryAcquireShared(int):共享方式。尝试获取资源。负数表示失败;0表示成功,但没有剩余可用资源;正数表示成功,且有剩余资源。
- tryReleaseShared(int):共享方式。尝试释放资源,如果释放后允许唤醒后续等待结点返回true,否则返回false。
以ReentrantLock为例,state初始化为0,表示未锁定状态。A线程lock()时,会调用tryAcquire()独占该锁并将state+1。此后,其他线程再tryAcquire()时就会失败,直到A线程unlock()到state=0(即释放锁)为止,其它线程才有机会获取该锁。当然,释放锁之前,A线程自己是可以重复获取此锁的(state会累加),这就是可重入的概念。但要注意,获取多少次就要释放多么次,这样才能保证state是能回到零态的。
再以CountDownLatch以例,任务分为N个子线程去执行,state也初始化为N(注意N要与线程个数一致)。这N个子线程是并行执行的,每个子线程执行完后countDown()一次,state会CAS减1。等到所有子线程都执行完后(即state=0),会unpark()主调用线程,然后主调用线程就会从await()函数返回,继续后续动作。
一般来说,自定义同步器要么是独占方法,要么是共享方式,他们也只需实现:
- tryAcquire-tryRelease
- tryAcquireShared-tryReleaseShared
中的一种即可。
当然AQS也支持自定义同步器同时实现独占和共享两种方式,如ReentrantReadWriteLock。
以下部分来自源码注释:
每次进入CLH队列时,需要对尾节点进入队列过程,是一个原子性操作。在出队列时,我们只需要更新head节点即可。在节点确定它的后继节点时, 需要花一些功夫,用于处理那些,由于等待超时时间结束或中断等原因, 而取消等待锁的线程。
节点的前驱指针,主要用于处理,取消等待锁的线程。如果一个节点取消等待锁,则此节点的前驱节点的后继指针,要指向,此节点后继节点中,非取消等待锁的线程(有效等待锁的线程节点)。
我们用next指针连接实现阻塞机制。每个节点均持有自己线程,节点通过节点的后继连接唤醒其后继节点。
CLH队列需要一个傀儡结点作为开始节点。我们不会再构造函数中创建它,因为如果没有线程竞争锁,那么,努力就白费了。取而代之的方案是,当有第一个竞争者时,我们才构造头指针和尾指针。
线程通过同一节点等待条件,但是用另外一个连接。条件只需要放在一个非并发的连接队列与节点关联,因为只有当线程独占持有锁的时候,才会去访问条件。当一个线程等待条件的时候,节点将会插入到条件队列中。当条件触发时,节点将会转移到主队列中。用一个状态值,描述节点在哪一个队列上。
4、Node
1 | static final class Node { |
waitStatus不同值含义:
- SIGNAL(-1):当前节点的后继节点已经 (或即将)被阻塞(通过park) , 所以当当前节点释放或则被取消时候,一定要unpark它的后继节点。为了避免竞争,获取方法一定要首先设置node为signal,然后再次重新调用获取方法,如果失败,则阻塞。
- CANCELLED(1):当前节点由于超时或者被中断而被取消。一旦节点被取消后,那么它的状态值不在会被改变,且当前节点的线程不会再次被阻塞。
- CONDITION(-2) :该节点的线程处于等待条件状态,不会被当作是同步队列上的节点,直到被唤醒(signal),设置其值为0,重新进入阻塞状态.
- PROPAGATE(-3:)共享模式下的释放操作应该被传播到其他节点。该状态值在doReleaseShared方法中被设置的。
- 0:以上都不是
该状态值为了简便使用,所以使用了数值类型。非负数值意味着该节点不需要被唤醒。所以,大多数代码中不需要检查该状态值的确定值。
一个正常的Node,它的waitStatus初始化值是0。如果想要修改这个值,可以使用AQS提供CAS进行修改。
5、独占模式与共享模式
在锁的获取时,并不一定只有一个线程才能持有这个锁(或者称为同步状态),所以此时有了独占模式和共享模式的区别,也就是在Node节点中由nextWaiter来标识。比如ReentrantLock就是一个独占锁,只能有一个线程获得锁,而WriteAndReadLock的读锁则能由多个线程同时获取,但它的写锁则只能由一个线程持有。
5.1、独占模式
5.1.1 独占模式同步状态的获取
1 | //忽略中断的(即不手动抛出InterruptedException异常)独占模式下的获取方法。 |
该方法首先尝试获取锁(tryAcquire(arg)的具体实现定义在了子类中),如果获取到,则执行完毕,否则通过addWaiter(Node.EXCLUSIVE), arg)方法把当前节点添加到等待队列末尾,并设置为独占模式。
1 | private Node addWaiter(Node mode) { |
如果tail节点为空,执行enq(node);重新尝试,最终把node插入.在把node插入队列末尾后,它并不立即挂起该节点中线程,因为在插入它的过程中,前面的线程可能已经执行完成,所以它会先进行自旋操作acquireQueued(node, arg),尝试让该线程重新获取锁!当条件满足获取到了锁则可以从自旋过程中退出,否则继续。
1 | final boolean acquireQueued(final Node node, int arg) { |
如果没获取到锁,则判断是否应该挂起,而这个判断则得通过它的前驱节点的waitStatus来确定:
1 | private static boolean shouldParkAfterFailedAcquire(Node pred, Node node) { |
最后,我们对获取独占式锁过程对做个总结:
AQS的模板方法acquire通过调用子类自定义实现的tryAcquire获取同步状态失败后->将线程构造成Node节点(addWaiter)->将Node节点添加到同步队列对尾(addWaiter)->节点以自旋的方法获取同步状态(acquirQueued)。在节点自旋获取同步状态时,只有其前驱节点是头节点的时候才会尝试获取同步状态,如果该节点的前驱不是头节点或者该节点的前驱节点是头节点单获取同步状态失败,则判断当前线程需要阻塞,如果需要阻塞则需要被唤醒过后才返回。
获取锁的过程:
- 当线程调用acquire()申请获取锁资源,如果成功,则进入临界区。
- 当获取锁失败时,则进入一个FIFO等待队列,然后被挂起等待唤醒。
- 当队列中的等待线程被唤醒以后就重新尝试获取锁资源,如果成功则进入临界区,否则继续挂起等待。
5.1.2 独占模式同步状态的释放
既然是释放,那肯定是持有锁的该线程执行释放操作,即head节点中的线程释放锁.
AQS中的release释放同步状态和acquire获取同步状态一样,都是模板方法,tryRelease释放的具体操作都有子类去实现,父类AQS只提供一个算法骨架。
1 | public final boolean release(int arg) { |
过程:首先调用子类的tryRelease()方法释放锁,然后唤醒后继节点,在唤醒的过程中,需要判断后继节点是否满足情况,如果后继节点不为空且不是作废状态,则唤醒这个后继节点,否则从tail节点向前寻找合适的节点,如果找到,则唤醒。
释放锁过程:
- 当线程调用release()进行锁资源释放时,如果没有其他线程在等待锁资源,则释放完成。
- 如果队列中有其他等待锁资源的线程需要唤醒,则唤醒队列中的第一个等待节点(先入先出)。
5.2、共享模式
5.2.1 共享模式同步状态的获取
- 当线程调用acquireShared()申请获取锁资源时,如果成功,则进入临界区。
- 当获取锁失败时,则创建一个共享类型的节点并进入一个FIFO等待队列,然后被挂起等待唤醒。
- 当队列中的等待线程被唤醒以后就重新尝试获取锁资源,如果成功则唤醒后面还在等待的共享节点并把该唤醒事件传递下去,即会依次唤醒在该节点后面的所有共享节点,然后进入临界区,否则继续挂起等待。
5.2.2 共享模式同步状态的释放
- 当线程调用releaseShared()进行锁资源释放时,如果释放成功,则唤醒队列中等待的节点,如果有的话。
6. AQS小结
java.util.concurrent中的很多可阻塞类(比如ReentrantLock)都是基于AQS来实现的。AQS是一个同步框架,它提供通用机制来原子性管理同步状态、阻塞和唤醒线程,以及维护被阻塞线程的队列。
JDK中AQS被广泛使用,基于AQS实现的同步器包括:
- ReentrantLock
- Semaphore
- ReentrantReadWriteLock(后续会出文章讲解)
- CountDownLatch
- FutureTask
每一个基于AQS实现的同步器都会包含两种类型的操作,如下:
- 至少一个acquire操作。这个操作阻塞调用线程,除非/直到AQS的状态允许这个线程继续执行。
- 至少一个release操作。这个操作改变AQS的状态,改变后的状态可允许一个或多个阻塞线程被解除阻塞。
基于“复合优先于继承”的原则,基于AQS实现的同步器一般都是:声明一个内部私有的继承于AQS的子类Sync,对同步器所有公有方法的调用都会委托给这个内部子类。
7.后续
后面会推出以下有关AQS的文章,已加深对于AQS的理解
8.思考
多人抢锁
多个线程同时取争取一个锁(在争取之前资源未被锁定),这时候如何保证,只有一个人能获取到?
下面以非公平锁来看一下
1 | /** |
从代码中可以看出通过compareAndSetState来保证只会有一个线程获取到锁。
LockSupport(park/unpark)
实现
Unsafe.park和Unsafe.unpark的底层实现原理
在Linux系统下,是用的Posix线程库pthread中的mutex(互斥量),condition(条件变量)来实现的。
mutex和condition保护了一个_counter的变量,当park时,这个变量被设置为0,当unpark时,这个变量被设置为1。
Object类的wait/notify和LockSupport(park/unpark)s的区别
park函数是将当前调用Thread阻塞,而unpark函数则是将指定线程Thread唤醒。
与Object类的wait/notify机制相比,park/unpark有两个优点:
- 以thread为操作对象更符合阻塞线程的直观定义
- 操作更精准,可以准确地唤醒某一个线程。
区别是:notify随机唤醒一个线程,notifyAll唤醒所有等待的线程,增加了灵活性
synchronized 实现
可以参考下这个:
https://xiaomi-info.github.io/2020/03/24/synchronized/
9.感谢
本文很多内容整理自网络,参考文献:
https://segmentfault.com/a/1190000011376192
https://segmentfault.com/a/1190000011391092
https://zhuanlan.zhihu.com/p/27134110
https://blog.csdn.net/wojiaolinaaa/article/details/50070031
https://www.cnblogs.com/waterystone/p/4920797.html
TCP与UDP 笔记
本文整理自:《图解TCP/IP 第5版》
作者:[日] 竹下隆史,[日] 村山公保,[日] 荒井透,[日] 苅田幸雄 著
译者:乌尼日其其格
出版时间:2013-07
[转]理解 Go Channels
Golang Channel
Go 1.9 Sync Map
基于Go 1.9 解析Sync Map
cs-interview
Java部分
- java比较 icompare
- tomcat 热部署 加载方式与双亲委派模型?
- java io api 过滤器模式?
- threadLocal 实现原理?
- tcp ip协议
- 服务端如何确定seesion是同一个?
- 内存屏障(Memory Barriers)
- lock synchronized ReentrantLock
- jvm JVM的年轻代分为哪几代?年轻代什么时候会进入老年代?
- jvm JVM 垃圾回收算法?(注意年轻代与老年代是不一样的)?
- jvm内存模型 一个变量初始化 怎么分配内存 分配到什么地方?
- 不使用双亲委派模型的缺点?
- java 开源序列化框架有哪些?彼此之间有什么区别(优缺点)?
- java.util.concurrent hashmap 相关问题
- JAVA线程sleep和wait方法区别
https://jiankunking.blog.csdn.net/article/details/79824353 - PriorityQueue(优先级队列) 堆相关问题
- 常见的负载均衡算法
- java 阻塞队列 相关问题,阻塞具体是如何实现的?
- 静态代码块. 构造代码块. 构造函数以及Java类初始化顺序
- java 枚举的实现,内部如何进行存储的?
- 静态内部类与普通内部类,在用法. 初始化方面的区别?
- java 原子性 可见性 顺序性是通过什么来保证的?
- java 多线程内共享的模型
- 阻塞非阻塞与同步异步
- java nio原理
- 读写锁 自旋锁 尝试锁(cas) cas如何保证,查询到修改这个过程是原子的?
- 一个类中的静态变量是在类加载的哪个步骤加载的?
- synchronized与ReentrantLock 实现原理区别?
- threadlocal 实现原理?应用场景?
- 常见的设计模式
- 分布式事务
- 线程池工作原理及机制
- 线程挂了 保活
- keepalive 保活策略?
- Protocol Buffers 适用场景?
- http tcp 相比多了些什么?有什么不一样的地方?
- http与https区别?加密算法是?
- wait 是释放锁?为什么释放了锁,线程就挂起了。为什么线程wait了就挂起了?
- CMS 垃圾回收
- hashmap 线程不安全 什么时候会出现?会出现什么问题?(hashmap为啥线程不安全?)
- equals 比较原理?
- jvm 内存分布
- arraylist linklist
- interger 为null 转int 会发生什么?
- hashmap与hashset的关系?
- 线程与协程的区别?协程的优势?
- JDK8 如何实现协程?
- java lambda 实现原理
- java stream 实现原理
- 永久代(permanent generation)与Metaspace
- 如何保证GC ROOTS找的全?(比如中G1中)
- G1清理老年代. 年轻代是遍历所有吗?
- 可重入锁和不可重入锁?不可重入锁有啥缺陷?
- CPU密集型 Java线程池大小为何会大多被设置成CPU核心数+1?
- 什么情况下会出现ClassNotFoundException?
- 线程有几种状态?
- 如何动态上报JVM信息,以便后期排查OOM等问题?
- ConcurrentHashMap put的时候加锁的是数组上的元素 还是啥?
- Concurrenthashmap中用到的优化技巧?
- LRU如何实现?
- 为什么Concurrenthashmap扩容是安全的?
- LinkedHashMap和HashMap 区别?
- CompletableFuture get(long timeout, TimeUnit unit) throws TimeoutException, ExecutionException实现
https://medium.com/@sergeykuptsov/how-it-works-in-java-completablefuture-3031dbbca66d
64、Java time-based map/cache with expiring keys
https://stackoverflow.com/questions/3802370/java-time-based-map-cache-with-expiring-keys
65、jmap 其实是多个线程 他们之间是怎么通信 dump出数据的?(jmap命令的实现原理)
66、GC的年轻代Survivor区,为什么是2个,而不是1个?
https://stackoverflow.com/questions/10695298/java-gc-why-two-survivor-regions
简单来说2个Survivor区,就是整理内存碎片的时候方便。
67、类加载器及类加载机制
MySQL部分
- MySQL 时间 比较无效 原因?
- MySQL 数据库 索引 是以什么数据结构形式存储的?
- MySQL与sql server 异同点? 原理上?
- 索引顺序对于索引效果的影响?
- 数据库索引如何优化(从哪几个方面)?
- MySQL优化有哪些?
- 比如一个表中有100条数据,a字段的值,是从1到100,我要更新其中的数据,where条件时a>10
MySQL通过innodb引擎的话,是通过表锁还是行锁? - MySQL mvcc多版本并发控制
- MySQL为什么选中B+ TREE而不是B TREE?两种数据结构有什么区别?
B+ 树继承于 B 树,都限定了节点中数据数目和子节点的数目。B 树所有节点都可以映射数据,B+ 树只有叶子节点可以映射数据。
单独看这部分设计,看不出 B+ 树的优势。为了只有叶子节点可以映射数据,B+ 树创造了很多冗余的索引(所有非叶子节点都是冗余索引),这些冗余索引让 B+ 树在插入、删除的效率都更高,而且可以自动平衡,因此 B+ 树的所有叶子节点总是在一个层级上。所以 B+ 树可以用一条链表串联所有的叶子节点,也就是索引数据,这让 B+ 树的范围查找和聚合运算更快。
- MySQL 范围查询?索引的数据结构是如何处理的?
- MySQL事务提交原理?
- 聚集索引 非聚集索引 查询效率?
- MySQL 乐观锁 悲观锁
- 数据库分库分表
基础
- 进程间通信方式有哪些?
- 有些信号你能捕获,有些信号你是捕获不了的,捕获不了的信号有哪些?
- zookeeper 可以通过watch,用来做进程间通信,那么zk底层是使用什么方式来实现进程间通信的?依赖操作系统如何实现的?
- socket通信
- keepalive时间限制
- tcp 如何处理粘包问题
- http协议 如何区分header头还有body体
- tcp 协议网络段 协议簇
- 一次完整的http请求
- http code 302 304含义
线上
- 如何线上debug?比如线上的cpu爆了,这个步骤是?
- 线上fd耗光了,如何排查?
- 如何定位OOM 问题?
Kakfa
- kafka某个broker上是否可以有无限个topic?或者万级别的topic?
- kafka 设计,还有broker上文件存储
- kakfa是否支持顺序消费消息?
- zk在kafka集群中的作用
- kafka 消费时候可以批量拉取?
- 消息队列 选型 为什么选择kafka?
- kafka增加. 删除节点时如何迁移数据?新的数据如何分配?
- kafka写入消息 如何保证回滚或者保证不被消费
- kafka 如何确保消息消费且只消费一次?
- kafka 大批量写入 是怎么传输的?
对象缓存池
https://www.sohu.com/a/346950666_100123073
https://github.com/a0x8o/kafka/blob/master/clients/src/main/java/org/apache/kafka/clients/producer/internals/BufferPool.java - Kafka和RocketMQ存储区别
https://www.cnblogs.com/lewis09/p/11168902.html
ElasticSearch
- 在ElasticSearch中,集群(Cluster),节点(Node),分片(Shard),Indices(索引),replicas(备份)之间是什么关系?
- elasticsearch整个建索引. 查询的过程
- elasticsearch如何选举
- ik 是如何进行分词的?
- es Scroll 原理? Search After原理?
- es 副本作用?
- MySQL elasticsearch 查询对比?(比如整个搜索流程)
- elasticsearch match filter 差异点?
- es 评分机制/原理
OpenTSDB
- OpenTSDB与HBase 关系
脑经急转弯
- 判断一个整数是2的N次方?
- 二叉树拷贝(非递归)
- BitMap算法(应用)
其他
- 分布式锁有哪些实现方式?
- 分布式事务
- 异地多活
- zookeeper集群 当一个节点挂了一天,当再次启动的时候,如何识别哪个是leader?
- 有什么知名的开源apm(Application Performance Management)工具吗?
- pinpoint 原理?
- consul template作用?如何与prometheus交互的?
金融
- 同业拆借
- 信用卡消费一笔钱,是如何到收款人的账户的?(整个流转过程)
- 复式记账
Spring
- spring 注入 接口即如何注入一个接口的多个实现类?
- spring 中用到的设计模式?spring中一次完整的http请求链路?
- 手写stater
- spring 类自动加载机制
- spring fegin 接口相互调用异常问题解决,有没有熔断啥的配置?
关于Spring AOP与IOC的个人思考
在阅读本文前,强烈建议阅读:
Java JDK 动态代理(AOP)使用及实现原理分析
Java HashMap
代码基于 Jdk1.8