历史背景
日志对于程序开发人员而言应该再熟悉不过了,从最简单的测试程序到复杂的分布式应用,从客户端(页面、App)到服务端,从系统内核态到用户态,日志无处不在,开发人员需要通过日志分析程序问题,记录程序状态,日志几乎伴随软件发展的各个历史阶段:
- 单机软件开发阶段,日志最主要的功能就是定位与分析软件的问题;
- 分布式开发阶段,日志的功能在定位问题的基础上增加了业务分析的功能,业务系统会通常会记录业务相关的日志用于后续分析系统的使用情况;
- 云原生开发阶段,日志相较于分布式阶段又引入了新的问题,如: 因应用动态编排(动态性)日志如何记录,大量微服务并发调用如何梳理日志时序与上下文等;
云原生日志
近年来随着以 Kubernetes 为代表的云原生技术的崛起,应用上云是大势所趋,随之而来的也为日志处理增加了新的挑战,如之前提到的日志如何记录,如何存储,如何检索等,以下简要罗列了云原生时代系统中日志处理面对的部分问题:
- 动态性变强
在Kubernetes中,机器下线、上线、Pod销毁、扩容/缩容等都是常态,这种情况下日志的存在是瞬时的(例如如果Pod销毁后该Pod日志就不可见了),所以日志必须有实时采集与存储的能力。 - 复杂性变强
在应用上云之前,大多数应用都是运行在某个服务器上,每个应用程序通常仅生成一个日志。现在随着应用上云、落地微服务架构,服务之间的依赖关系越来越复杂了,排查问题时如何关联各个维度、服务的日志将是一个困难的问题。 - 日志结构复杂
在上云之后,绝大多数的开发者都习惯于通过终端输出日志,但这些日志有的是一条普通文本,有的是一条json,如何兼顾多种日志结构,满足不同的业务需求? - 日志与Trace
当应用开发者根据 Trace 定位到问题模块、方法的时候,如何查看该请求对应的日志上下文?
当应用开发者在日志中发现一个异常的时候,如何查看该日志对应请求的Trace上下文?
架构介绍
为了解决云原生平台日志处理面临的问题,开发者平台整合了业内流行的方案并结合海尔内部业务方的特有需求与特定应用场景作了定制化的修改(包括性能调优,开源组件源码调整等)
主要组件如下:
Filebeat(云原生平台中以Daemonset方式运行于每个Node中收集日志)
Kafka(消息中间件)
Elasticsearch(日志存储)
Kibana(数据查看、分析、图表展示)
自研高性能服务(负责日志存储与提取)
整体架构

解决方案
针对云原生场景下的日志需求(上节所提出的问题),云原生开发者平台提供了以下核心能力:
实时日志
日志实时查询可实时同步查询运行中应用所输出的日志,方便快速定位问题,主要是用于在测试环境分析应用的出现的问题
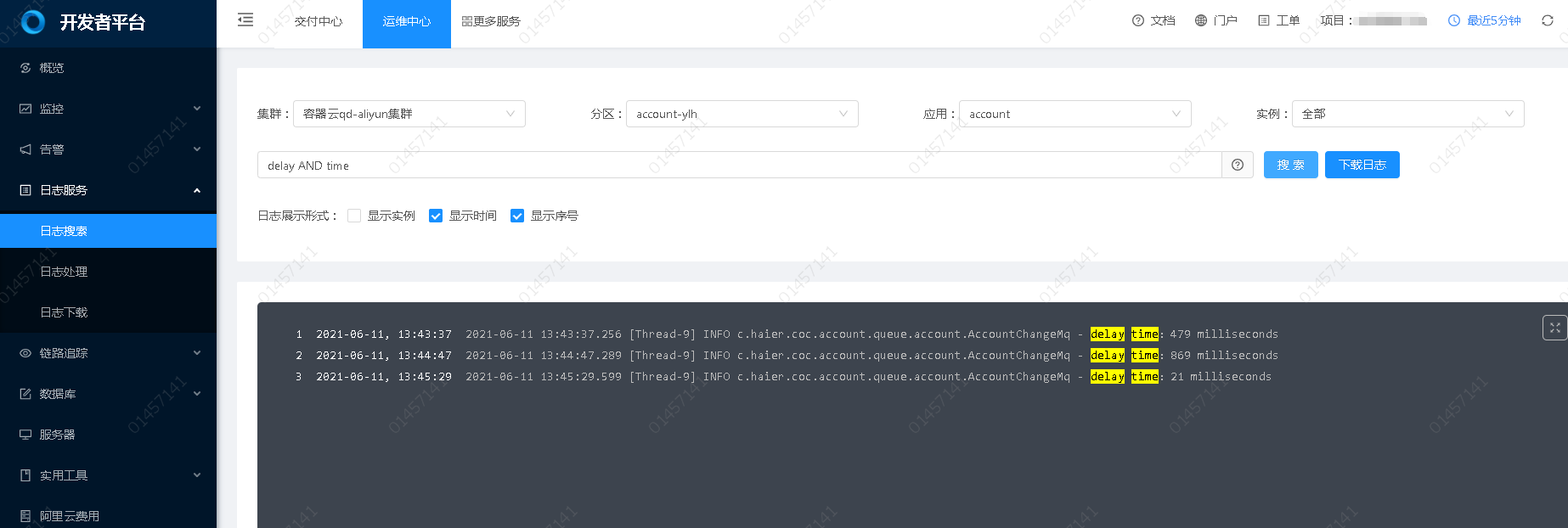
日志查询
日志查询可以帮助开发人员从应用历史日志中快速检索与定位信息,可以通过关键字或是关键字的组合来查询,既可以用于定位应用问题也可以用于分析业务日志, 主要功能如下:
- 历史日志快速检索(则在搜索框输入内容即可)
- 日志上下文关联查询
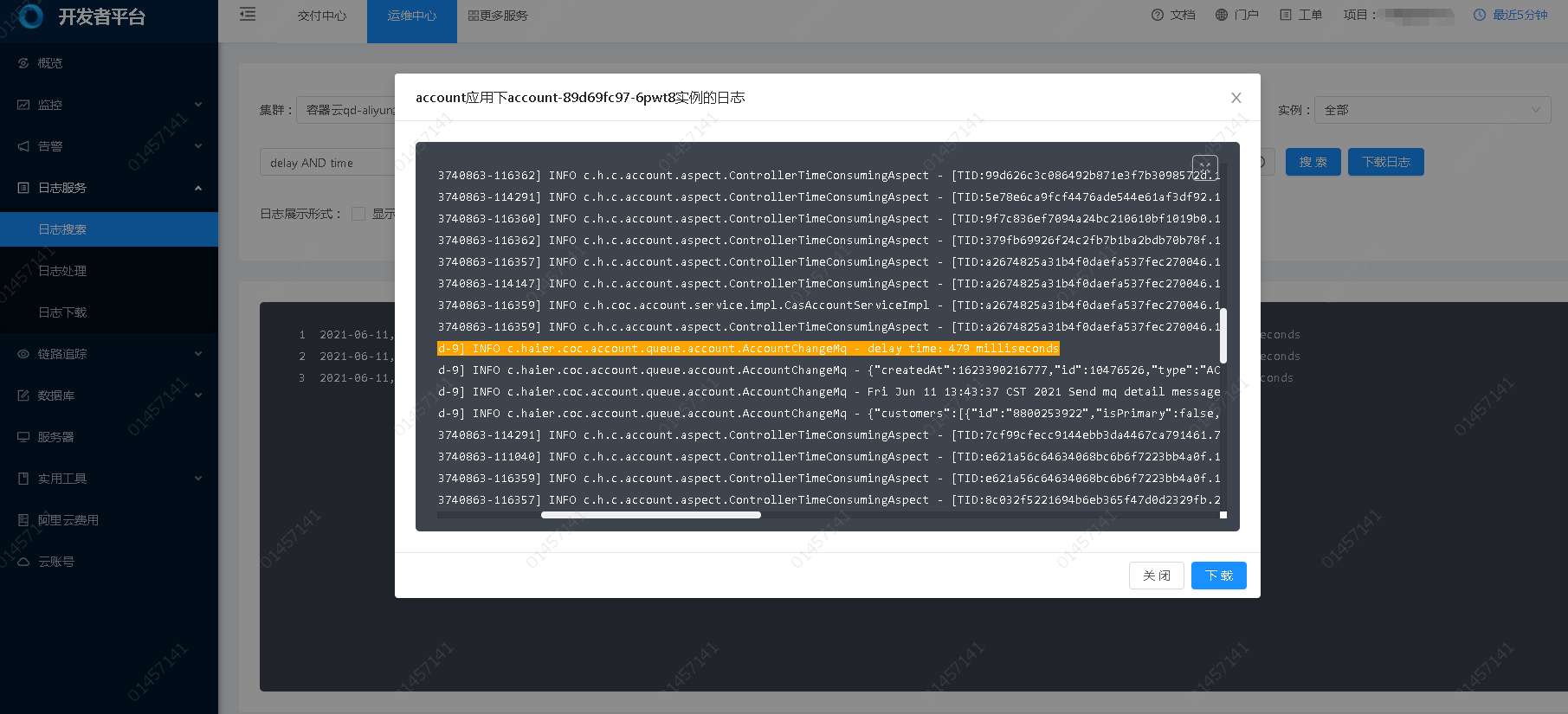
日志处理
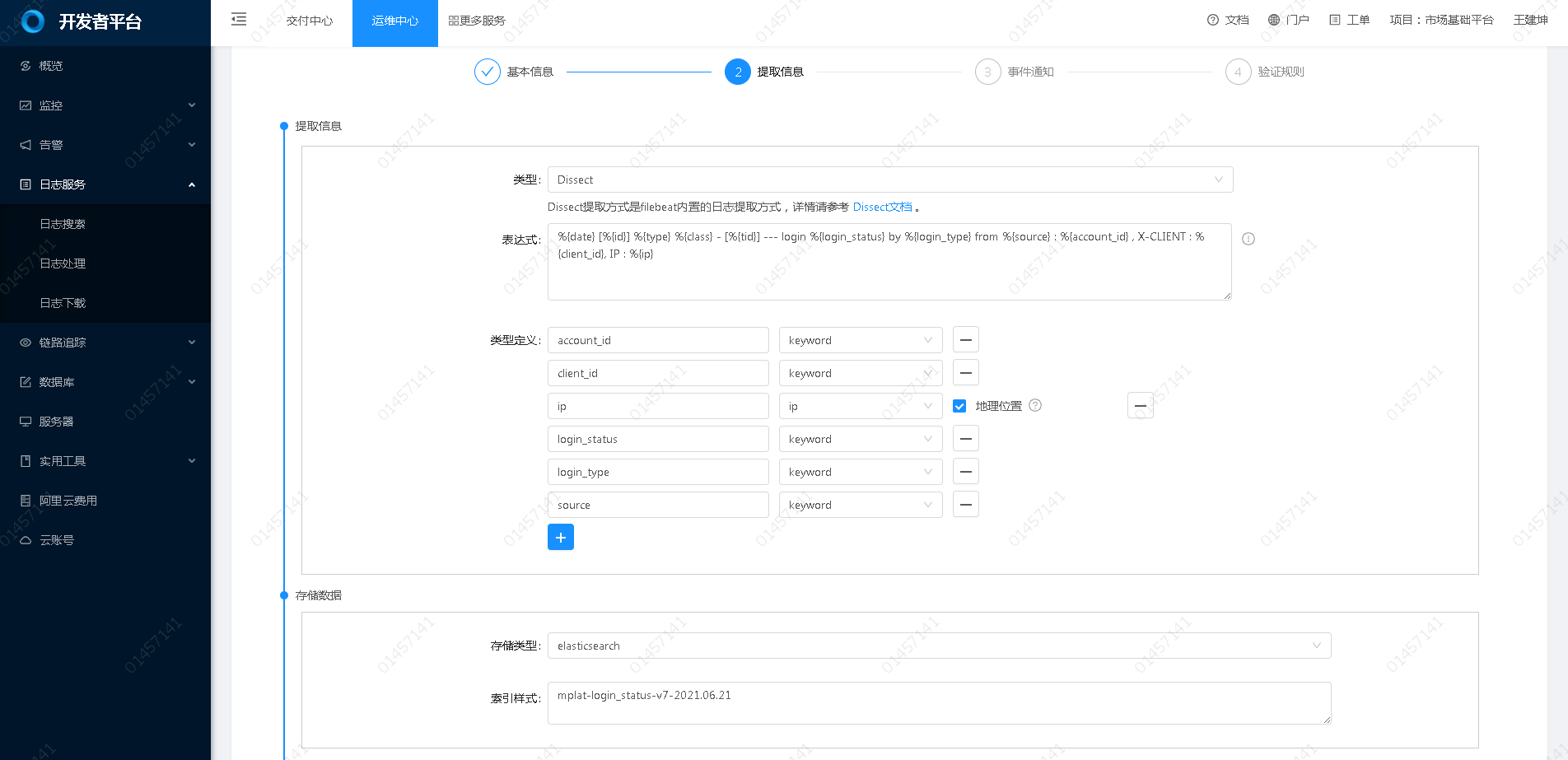
日志处理功能主要针对业务日志处理与分析,通过将特定的业务日志(支持过滤)按照某种方式进行结构化提取将其格式转换并单独存储,后续既可以给开发人员分析特定业务与可以提供给数据分析人员进行数据分析,主要功能如下:
- 日志结构化提取与存储(支持三种结构化提取方式: dissect,grok,json)
- 日志访问地理位置转换(如果日志提取中包含ip信息可以自动转换其地理位置)
- 特定日志事件通知(可针对特定的日志触发通知)
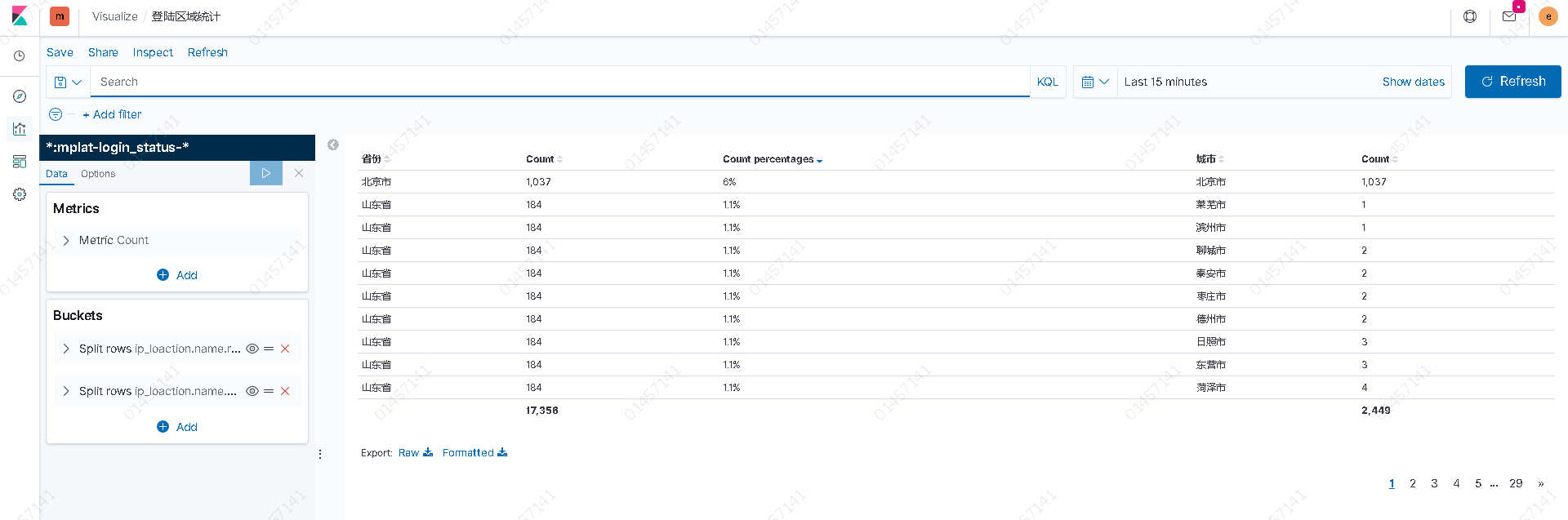
- 整合kibana将提取后的数据以图表展示
日志与Trace
如果应用在输出日志中整合了trace跟踪系统,后续分析时可以方便的查询相关trace上下文的日志集合并且支持日志与trace两都双向关联。
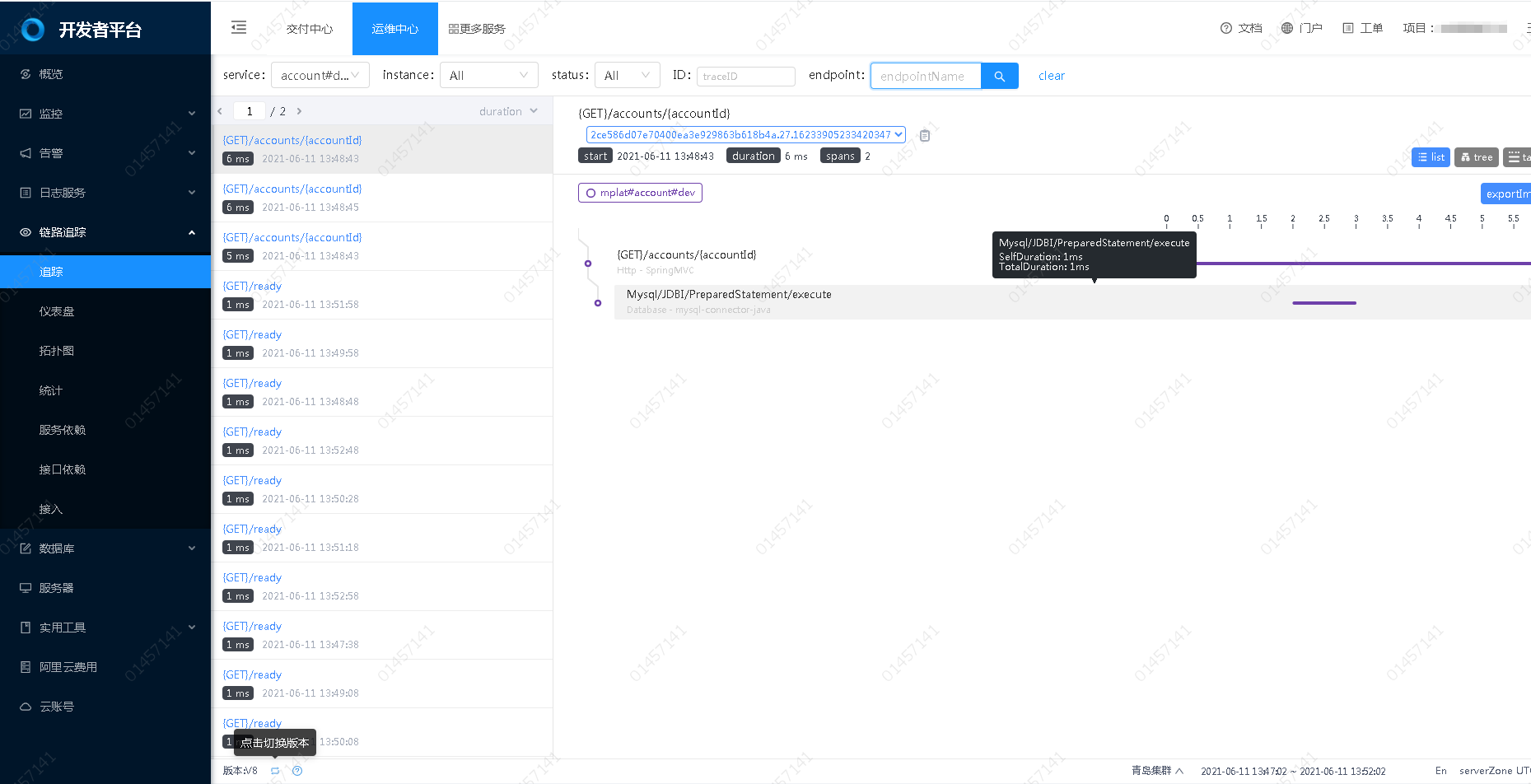
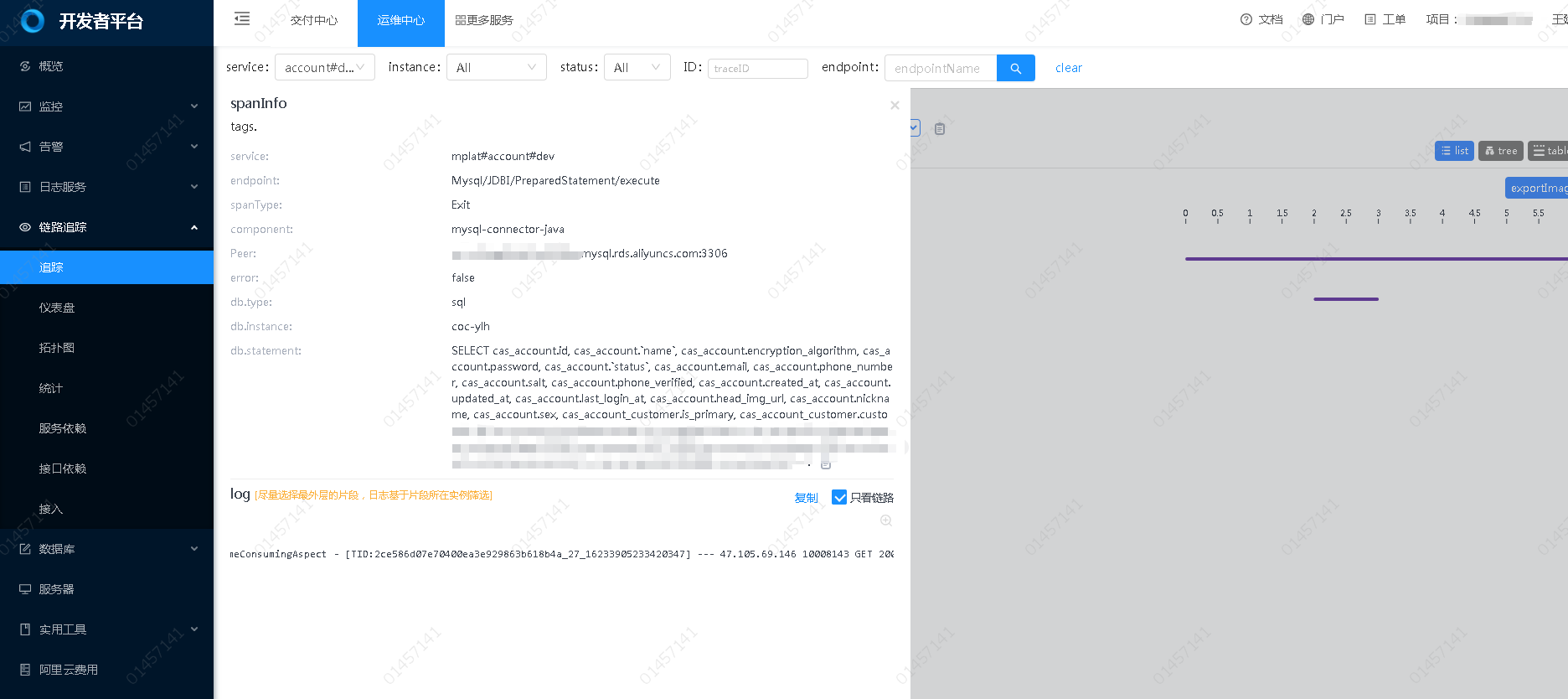
Trace到日志
- 点击某个想要查看的请求;
- 点击请求中的某一步,就可以在详情中看到日志了;
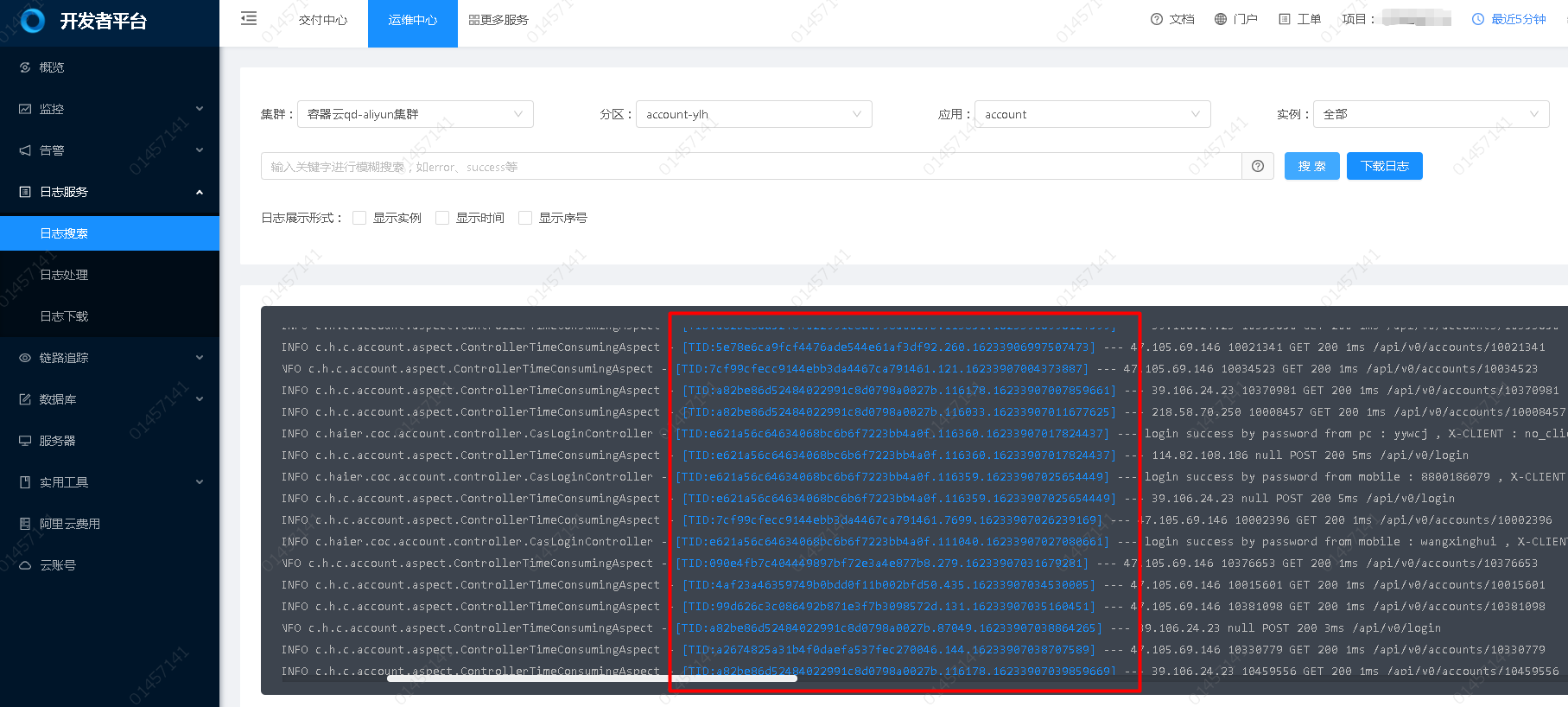
日志到Trace
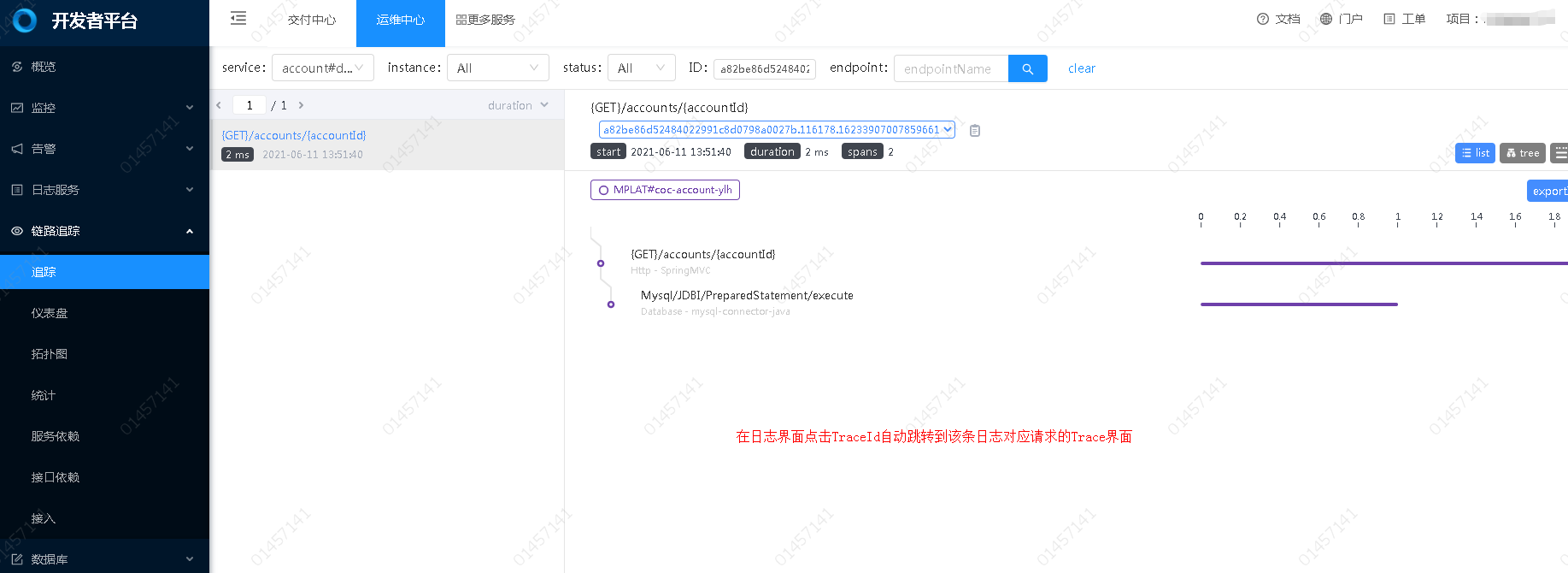
- 找到自己关注那条日志;
- 点击蓝色的TID部分,即可跳转链路追踪查看Trace信息。
总结
以上介绍了云原生开发者平台在日志部分提供主要功能,可以看到当前的核心功能既可以满足开发人员的需求又可以为业务与数据分析人员提供部分支持,但是还有一定的提升空间,例如数据存储的实时性还有待提高,数据检索的能力与关联查询的能力可以进一步提升,后续也会继续深入挖掘业务需求并结合海尔智家的特定场景为业务方赋能。