[译]eBay Elasticsearch性能调优实践
翻译自:Elasticsearch Performance Tuning Practice at eBay
地址:
https://tech.ebayinc.com/engineering/elasticsearch-performance-tuning-practice-at-ebay
Elasticsearch是一个基于Apache Lucene的开源搜索和分析引擎,允许用户近实时地存储、搜索和分析数据。在eBay上承载Elasticsearch集群的平台Pronto,使eBay内部客户可以轻松地部署、操作和扩展Elasticsearch,以实现全文搜索、实时分析和日志/事件监控。现在有60多个Elasticsearch集群和2000多个节点由Pronto管理。每天提取的文档达到180亿,每天的搜索请求达到35亿次。该平台提供了从供应、补救、安全性到监控、警报和诊断的全方位服务。
虽然Elasticsearch是为快速查询而设计的,但性能很大程度上取决于应用于应用程序的场景、要索引的数据量以及应用程序和用户查询数据的频率。本文总结了这些挑战,以及Pronto团队为解决这些挑战而构建的过程和工具。本文还展示了对各种配置进行基准测试的某些结果,以作说明。
挑战
迄今为止观察到的Pronto/Elasticsearch面临的挑战包括:
- 高吞吐量:某些集群每天最多提取5TB数据,而某些集群每天要接收超过4亿个搜索请求。如果Elasticsearch无法及时处理请求,则请求将在上游累积。
- 低搜索等待时间:对于性能至关重要的群集,尤其是对于面向站点(site-facing)的系统,低搜索等待时间是强制性的,否则会影响用户体验。
- 由于数据或查询是可变的,因此最佳设置始终会更改。没有适用于所有方案的最佳设置。例如,将索引拆分为更多的分片将有助于耗时的查询,但它可能会损害其他查询的性能。
解决方案
为了帮助我们的客户应对这些挑战,Pronto团队建立了性能测试、调优和监控的方式,从用户案例入手开始,一直持续到整个集群生命周期。
- 大小调整:在开始使用新用例之前,先收集客户提供的信息,例如吞吐量,文档大小,文档数和搜索类型,以估计Elasticsearch集群的初始大小。
- 优化索引设计:与客户一起审查索引设计。
- 调整索引性能:根据用户方案调整索引性能和搜索性能。
- 调整搜索性能:使用用户实际数据/查询运行性能测试,并结合使用Elasticsearch配置参数来比较和分析测试结果。
- 运行性能测试:案例启动后,将监控群集,并且只要数据更改,查询更改或流量增加,用户就可以自由地重新运行性能测试。
大小
Pronto团队针对每种机器和每种受支持的Elasticsearch版本运行基准测试以收集性能数据,然后将其与客户提供的信息一起用于估计集群的初始大小,包括:
- 索引吞吐量
- 文档大小
- 搜索量
- 查询类型
- 热索引文档数量
- 保留策略
- 响应时间要求
- SLA级别
优化索引设计
在开始提取数据并运行查询之前,请三思而后行。索引代表什么? Elastic官方的回答是”具有一些相似特征的文档集合。” 因此,下一个问题是”我应该使用哪些特征对数据进行分组? 我应该将所有文档放入一个索引还是多个索引?” 答案是,这取决于您使用的查询。以下是有关如何根据最常用的查询来组织索引的一些建议。
例如,Elasticsearch接收了大量全局产品信息,大多数查询都有一个过滤子句”region”,并且很少有机会运行跨区域的查询。可以优化查询主体:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16{
"query": {
"bool": {
"must": {
"match": {
"title": "${title}"
}
},
"filter": {
"term": {
"region": "US"
}
}
}
}
}在这种情况下,如果将该索引按地区划分为几个较小的索引,如美国、欧洲和其他国家,我们可以获得更好的性能。然后可以从查询中删除filter子句。如果需要运行跨区域查询,可以将多个索引或通配符传递给Elasticsearch。
如果查询具有过滤器字段且其值不可枚举,请使用路由。通过使用过滤器字段值作为路由键并删除过滤器,我们可以将索引分为多个分片。
例如,Elasticsearch接收了数百万个订单,并且大多数查询都需要按买家ID查询订单。无法为每个买家创建索引,因此我们无法通过买家ID将数据分成多个索引。一个合适的解决方案是通过路由将相同买家ID的所有订单路由到同一个分片。这样,几乎所有的查询都可以在匹配routing key的分片中完成。
如果查询具有日期范围过滤器,则按日期组织数据。这适用于大多数日志记录或监控方案。我们可以按每天,每周或每月组织索引,然后可以按指定的日期范围获取索引列表。Elasticsearch仅需要查询较小的数据集,而不是整个数据集。另外,当数据过期时,很容易收缩/删除旧索引。
显式设置映射。Elasticsearch可以动态创建映射,但是可能并不适合所有情况。例如,Elasticsearch 5.x中的默认字符串字段映射都是”keyword”和”text”类型。在许多情况下都是不必要的。
如果使用用户定义的ID或路由为文档建立索引,要注意避免分片不平衡。Elasticsearch使用随机ID生成器和哈希算法来确保将文档平均分配给分片。当使用用户定义的ID或路由时,ID或路由key可能不够随机,会导致某些分片可能明显大于其他分片。在这种情况下,对该分片的读/写操作将比其他分片慢得多。我们可以优化ID/路由键或使用index.routing_partition_size(在5.3及更高版本中可用)。
使分片均匀分布在节点上。如果一个节点的分片比其他节点多,那么它将比其他节点承担更多的负载,可能成为整个系统的瓶颈。
调优索引性能
对于日志和监控等需要大量索引的场景,索引性能是关键指标。以下是一些建议。
使用批量(bulk)请求。
使用多个线程发送请求。
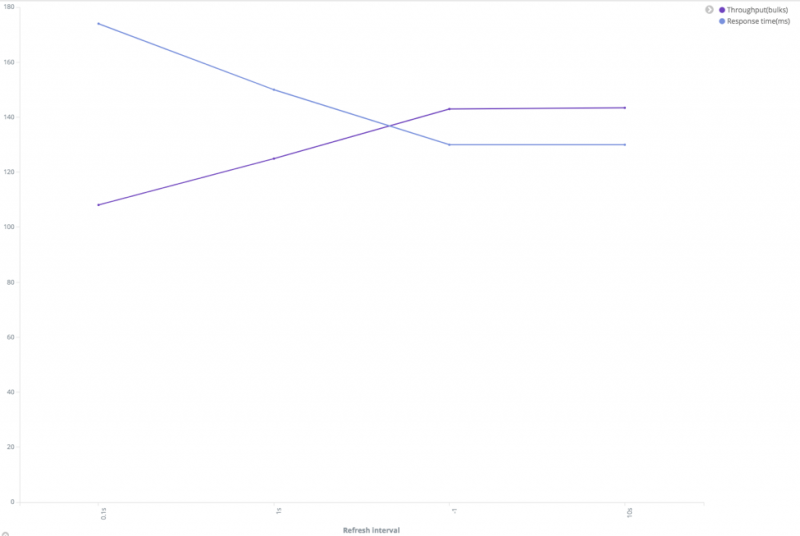
增加刷新(refresh)间隔。每次刷新事件发生时,Elasticsearch都会创建一个新的Lucene段,然后合并它们。增加刷新间隔可以降低创建/合并的成本。请注意,只有在刷新后才可以搜索文档。
![Relationship between performance and refresh interval]()
从上图中可以看出,随着刷新间隔的增加,吞吐量增加,响应时间减少。我们可以使用下面的请求来检查我们有多少段,以及在刷新和合并上花费了多少时间。1
GET index_name/_stats?filter_path= indices.**.refresh,indices.**.segments,indices.**.merges
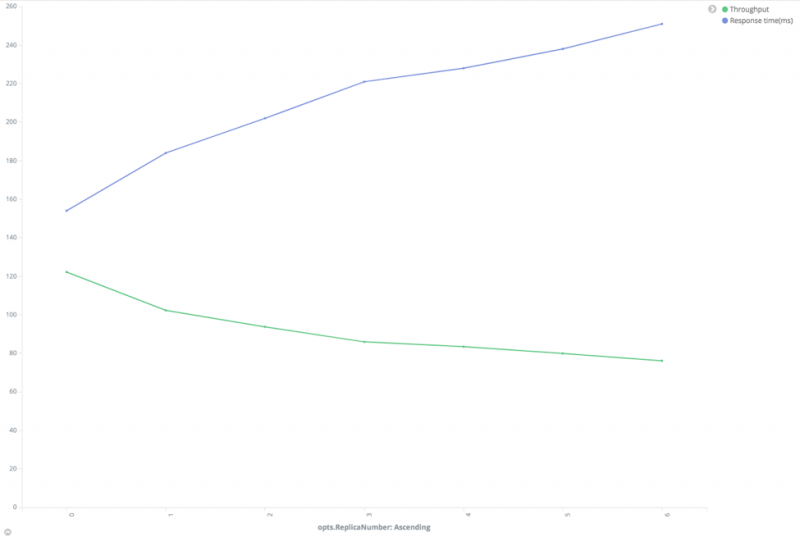
减少副本数量。Elasticsearch需要为每个索引请求将文档写入主分片和所有副本分片。显然,大的副本数会降低索引速度,但另一方面,它会提高搜索性能。我们将在本文后面讨论它。
![Relationship between performance and replica number]()
从上图中,我们可以看到随着副本数的增加,吞吐量降低,响应时间增加。尽可能使用自动生成的ID。Elasticsearch可以确保自动生成的ID是唯一的,以避免版本查找。如果客户确实需要使用自定义ID,我们的建议是选择一个对Lucene友好的ID,例如零填充顺序ID,UUID-1或Nano time。这些ID具有一致的顺序模式,可以很好地压缩。相比之下,诸如UUID-4之类的ID本质上是随机的,这提供了较差的压缩并降低了Lucene的运行速度。
调优搜索性能
使用Elasticsearch的主要原因是为了支持对数据的搜索。用户应该能够快速找到所需的信息。搜索性能取决于很多因素。
- 如果可能,请使用过滤(filter)器上下文而不是查询(query)上下文。query子句用于回答”此文档与该子句的匹配程度如何?”filter子句用于回答”此文档是否与此子句匹配?” Elasticsearch只需回答”是”或”否”。它不需要为过滤器子句计算相关性得分,并且可以缓存过滤器结果。有关详细信息,请参见查询和过滤上下文。
增加刷新(refresh)间隔。正如我们在调优索引性能部分中提到的那样,每次刷新时,Elasticsearch都会创建新的segment。增加刷新间隔将有助于减少段数并减少搜索的IO成本。并且,一旦刷新发生并更改了数据,缓存将无效。增加刷新间隔可以使Elasticsearch更有效地利用缓存。
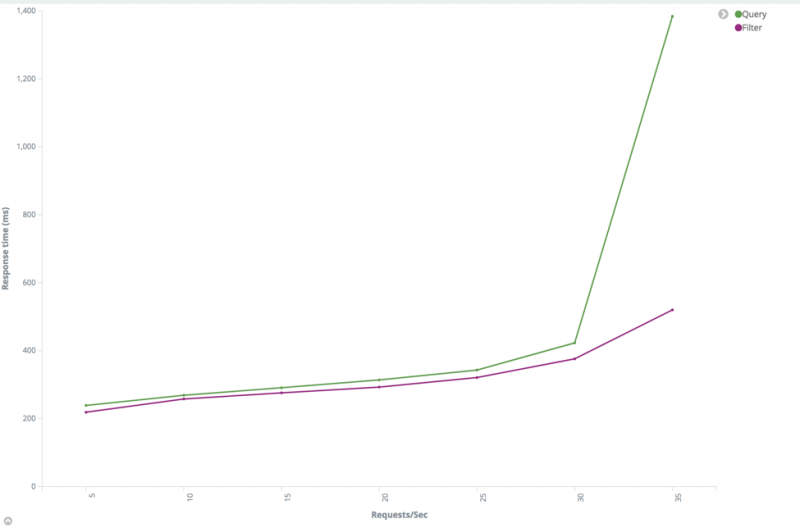
增加副本数。Elasticsearch可以对主分片或副本分片执行搜索。您拥有的副本越多,搜索中可以用到的节点越多。
![Relationship between performance and replica number]()
从上图可以看到,搜索吞吐量几乎与副本数成线性关系。请注意,在此测试中,测试群集具有足够的数据节点,以确保每个分片都具有排他节点。如果不能满足此条件,则搜索吞吐量将不那么理想。尝试不同的分片数。”我应该为索引设置多少个碎片?”这可能是我们最常看到的问题。不幸的是,没有适用于所有情况的正确数字。这完全取决于您的情况。
分片数太小将使搜索无法扩展。例如,如果分片数设置为1,则索引中的所有文档都将存储在一个分片中。对于每次搜索,只能涉及一个节点。如果您有很多文档,那会很费时间。从另一方面说,创建具有太多分片的索引也对性能有害,因为Elasticsearch需要对所有分片运行查询,除非在请求中指定了路由key,然后才将所有返回的结果提取并合并在一起。根据我们的经验,如果索引小于1G,可以将分片数设置为1。对于大多数情况,我们可以将分片数保留为默认值5,但是如果分片大小超过30GB,则应增加分片数以将索引拆分为更多分片。创建索引后就无法更改分片数,但是我们可以创建一个新索引并使用reindex API来移动数据。
我们测试了一个索引,该索引包含1亿个文档,约为150GB。我们使用了100个线程来发送搜索请求。
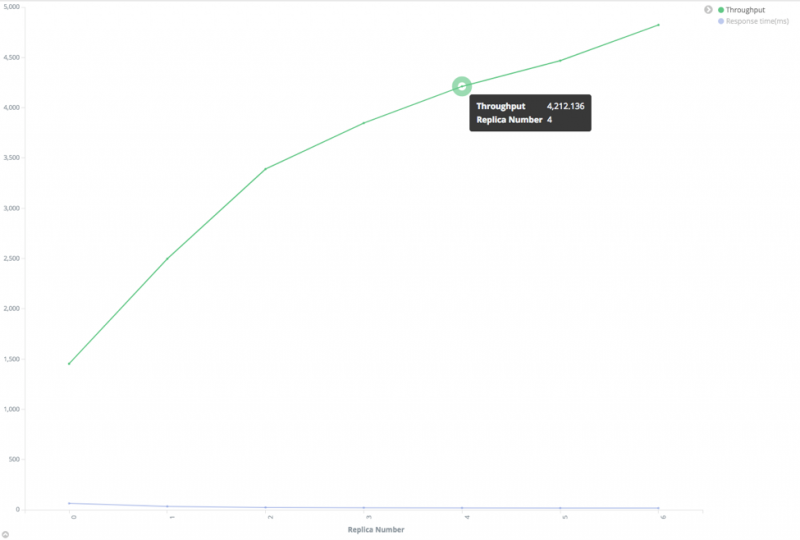
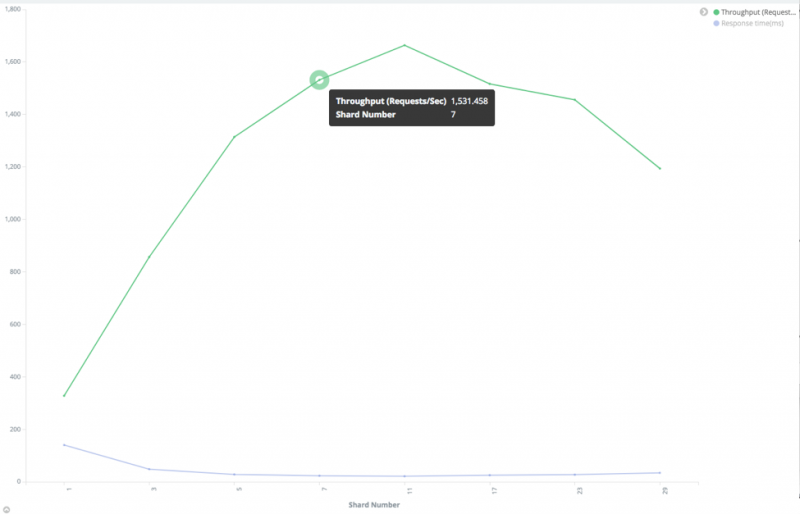
从上图可以看出,最优的分片数量为11。搜索吞吐量在开始时增加(响应时间减少),但随着分片数量的增加而减少(响应时间增加)。
请注意,在此测试中,就像在副本数测试中一样,每个分片都有一个独占节点。如果不能满足此条件,则搜索吞吐量将不如该图所示。
在这种情况下,我们建议您尝试使用小于最优值的分片数,因为如果使用大的分片数,它将需要很多节点,并且使每个分片都具有专用的数据节点。
节点查询缓存。节点查询缓存仅缓存在过滤器(filter)上下文中使用的查询。与查询(query)子句不同,过滤器子句是”是”或”否”的问题。Elasticsearch使用位集(bit set)机制来缓存过滤器结果,以便以后使用相同过滤器的查询将得到加速。请注意,只有包含超过10,000个文档(或总文档的3%,以较大者为准)的段(segments)将启用查询缓存。有关更多详细信息,请参阅缓存。
我们可以使用以下请求来检查节点查询缓存是否有效。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29GET index_name/_stats?filter_path=indices.**.query_cache
{
"indices": {
"index_name": {
"primaries": {
"query_cache": {
"memory_size_in_bytes": 46004616,
"total_count": 1588886,
"hit_count": 515001,
"miss_count": 1073885,
"cache_size": 630,
"cache_count": 630,
"evictions": 0
}
},
"total": {
"query_cache": {
"memory_size_in_bytes": 46004616,
"total_count": 1588886,
"hit_count": 515001,
"miss_count": 1073885,
"cache_size": 630,
"cache_count": 630,
"evictions": 0
}
}
}
}
}分片查询缓存。如果大多数查询是聚合查询,则应查看分片查询缓存,该缓存可以缓存聚合结果,以便Elasticsearch以很少的成本直接为请求提供服务。有几件事要注意:
- 设置”size”:0。分片查询缓存仅缓存汇总结果和建议(suggestion)。它不会缓存命中,因此如果将size设置为非零,就不能从缓存中受益。
- 有效负载JSON必须相同。分片查询缓存使用JSON主体作为缓存键,因此您需要确保JSON主体不变,并确保JSON主体中的键顺序相同。
- 四舍五入查询时间。不要在查询中直接使用Date.now之类的变量。四舍五入。否则,每个请求都将具有不同的有效负载主体,这将使缓存始终无效。我们建议您将日期时间舍入为小时或天,以更有效地利用缓存。
我们可以使用下面的请求来检查分片查询缓存是否有效。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23GET index_name/_stats?filter_path=indices.**.request_cache
{
"indices": {
"index_name": {
"primaries": {
"request_cache": {
"memory_size_in_bytes": 0,
"evictions": 0,
"hit_count": 541,
"miss_count": 514098
}
},
"total": {
"request_cache": {
"memory_size_in_bytes": 0,
"evictions": 0,
"hit_count": 982,
"miss_count": 947321
}
}
}
}
}仅检索必须字段。如果文档很大,并且只需要几个字段,请使用stored_fields检索需要的字段,而不是所有字段。
避免搜索停用词。诸如”a”和”the”之类的停用词可能会导致查询匹配结果数量激增。想象一下您有一百万个文档。搜索”fox”可能会返回数十次匹配,但是搜索”the fox”可能会返回索引中的所有文档,因为”the”几乎出现在所有文档中。Elasticsearch需要对所有命中结果进行评分和排序,以使诸如”the fox”之类的查询减慢整个系统的速度。您可以使用停止令牌过滤器(stop token filter)删除停用词,或使用”and”运算符将查询从”the fox”更改为”the AND fox”,以获得更精确的匹配结果。如果索引中经常使用某些单词,但默认停用词列表中没有这些单词,则可以使用截止频率(cutoff-frequency)来动态处理它们。
如果您不关心文档的返回顺序,请按_doc排序。默认情况下,Elasticsearch使用”_score”字段按分数排序。如果您不关心顺序,则可以使用”sort”:”_ doc”让Elasticsearch按索引顺序返回匹配。
避免使用脚本查询实时计算(Avoid using a script query to calculate hits in flight)。索引时存储计算出的字段。例如,我们有一个包含大量用户信息的索引,并且我们需要查询所有以”1234”开头的用户。您可能想运行脚本查询,例如”source”:”doc[‘num’].value.startsWith(‘1234’).”。这种查询真很耗资源,并且会降低整个系统的速度。在建立索引时,请考虑添加一个名为”num_prefix”的字段。然后我们可以查询”name_prefix”:”1234”。
避免使用通配符查询。
性能测试
对于每项更改,都必须运行性能测试以验证更改是否合适。由于Elasticsearch是restful的服务,因此您可以使用Rally,Apache Jmeter和Gatling等工具来运行性能测试。因为Pronto团队需要在每种类型的机器和Elasticsearch版本上运行大量基准测试,并且我们需要在许多Elasticsearch集群上针对Elasticsearch配置参数组合运行性能测试,所以这些工具无法满足我们的要求。
Pronto团队基于Gatling构建了在线绩效分析服务,以帮助客户和我们进行绩效测试并进行回归分析。服务提供的功能使我们能够:
- 轻松添加/编辑测试。用户可以根据自己输入的查询或文档结构生成测试,而无需Gatling或Scala知识。
- 按顺序运行多个测试,无需人工干预。它可以在每次测试之前/之后检查状态并更改Elasticsearch设置。
- 帮助用户比较和分析测试结果分析。测试期间的测试结果和群集统计信息将保留并可以通过预定义的Kibana可视化文件进行分析。
- 从命令行或Web UI运行测试。还为与其他系统的每次集成提供了Rest API。
下面是它的架构:
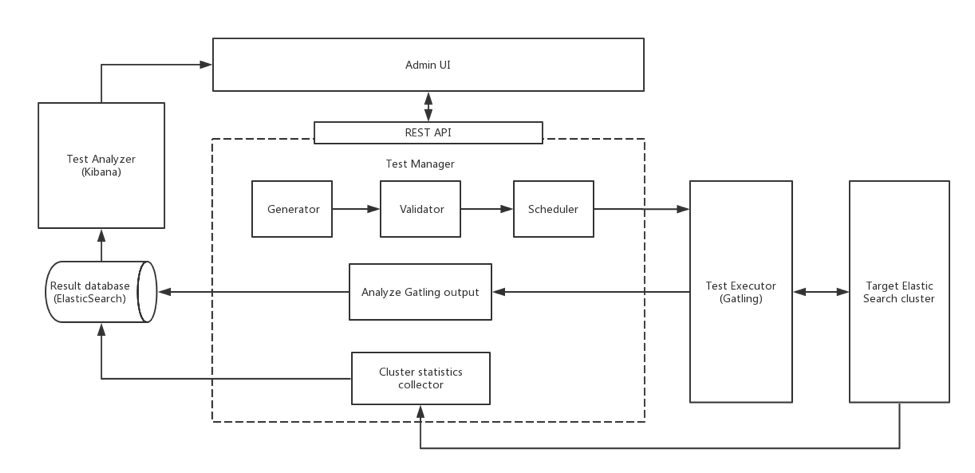
用户可以查看每项测试的Gatling报告,并查看Kibana预定义的可视化效果,以进行进一步的分析和比较,如下所示。
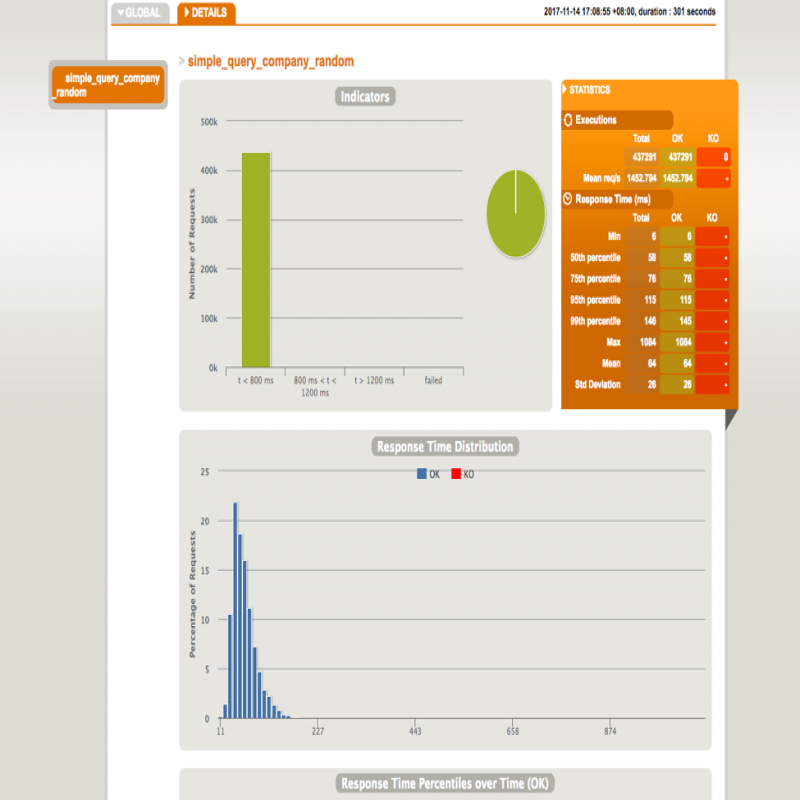
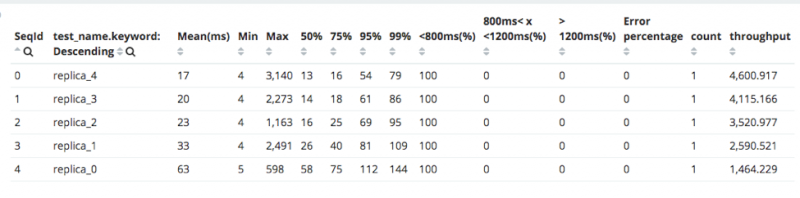
总结
本文总结了索引/分片/副本设计以及在设计Elasticsearch集群时应考虑的其他一些配置,以满足对提取和搜索性能的高期望。它还说明了Pronto如何帮助客户进行索引初始大小确定,索引设计和调优以及性能测试。截至目前,Pronto团队已帮助包括订单管理系统(OMS)和搜索引擎优化(SEO)在内的许多客户实现了苛刻的性能目标,从而为eBay的关键业务做出了贡献。
Elasticsearch的性能取决于许多因素,包括文档结构,文档大小,索引设置/映射,请求率,数据集大小,查询命中数等。针对一种情况的建议不一定适用于另一种情况。全面测试性能,收集遥测数据,根据您的工作负载调整配置并优化群集以满足性能要求非常重要。