1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
| /**
* Removes the mapping for the specified key from this map if present.
*
* @param key key whose mapping is to be removed from the map
* @return the previous value associated with <tt>key</tt>, or
* <tt>null</tt> if there was no mapping for <tt>key</tt>.
* (A <tt>null</tt> return can also indicate that the map
* previously associated <tt>null</tt> with <tt>key</tt>.)
*/
public V remove(Object key) {
Node<K,V> e;
return (e = removeNode(hash(key), key, null, false, true)) == null ?
null : e.value;
}
/**
* Implements Map.remove and related methods
*
* @param hash hash for key
* @param key the key
* @param value the value to match if matchValue, else ignored
* @param matchValue if true only remove if value is equal
* @param movable if false do not move other nodes while removing
* @return the node, or null if none
*/
final Node<K,V> removeNode(int hash, Object key, Object value,
boolean matchValue, boolean movable) {
Node<K,V>[] tab; Node<K,V> p; int n, index;
if ((tab = table) != null && (n = tab.length) > 0 &&
(p = tab[index = (n - 1) & hash]) != null) {
Node<K,V> node = null, e; K k; V v;
if (p.hash == hash &&
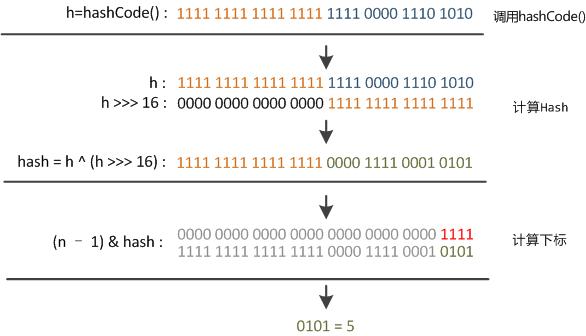
//先比较内存地址,如果地址不一致,再调用equals进行比较
((k = p.key) == key || (key != null && key.equals(k))))
node = p;
else if ((e = p.next) != null) {
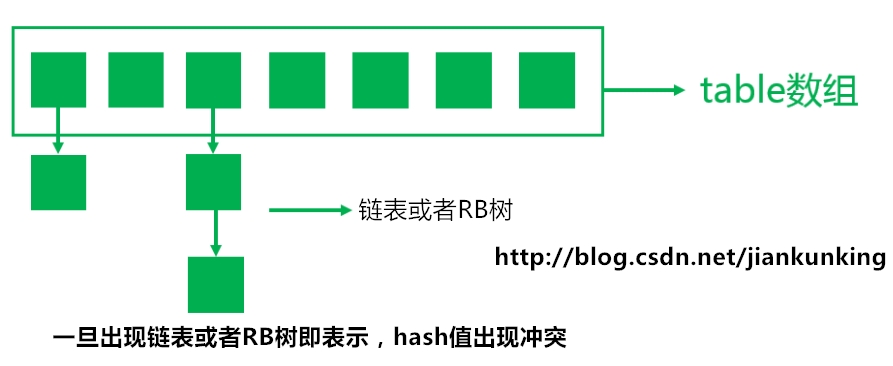
//如果是以红黑树处理冲突,则通过getTreeNode查找
if (p instanceof TreeNode)
node = ((TreeNode<K,V>)p).getTreeNode(hash, key);
else {
//如果是以链式的方式处理冲突,则通过遍历链表来寻找节点
do {
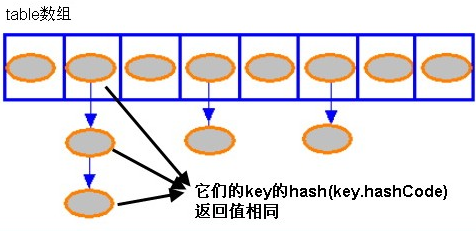
if (e.hash == hash &&
((k = e.key) == key ||
(key != null && key.equals(k)))) {
node = e;
break;
}
p = e;
} while ((e = e.next) != null);
}
}
//比对找到的key的value跟要删除的是否匹配
if (node != null && (!matchValue || (v = node.value) == value ||
(value != null && value.equals(v)))) {
if (node instanceof TreeNode)
((TreeNode<K,V>)node).removeTreeNode(this, tab, movable);
else if (node == p)
tab[index] = node.next;
else
p.next = node.next;
//已从结构上修改 此列表的次数
++modCount;
--size;
//回调
afterNodeRemoval(node);
return node;
}
}
return null;
}
/**
* Removes the given node, that must be present before this call.
* This is messier than typical red-black deletion code because we
* cannot swap the contents of an interior node with a leaf
* successor that is pinned by "next" pointers that are accessible
* independently during traversal. So instead we swap the tree
* linkages. If the current tree appears to have too few nodes,
* the bin is converted back to a plain bin. (The test triggers
* somewhere between 2 and 6 nodes, depending on tree structure).
*/
final void removeTreeNode(HashMap<K,V> map, Node<K,V>[] tab,
boolean movable) {
int n;
if (tab == null || (n = tab.length) == 0)
return;
int index = (n - 1) & hash;
TreeNode<K,V> first = (TreeNode<K,V>)tab[index], root = first, rl;
TreeNode<K,V> succ = (TreeNode<K,V>)next, pred = prev;
if (pred == null)
tab[index] = first = succ;
else
pred.next = succ;
if (succ != null)
succ.prev = pred;
if (first == null)
return;
if (root.parent != null)
root = root.root();
if (root == null || root.right == null ||
(rl = root.left) == null || rl.left == null) {
tab[index] = first.untreeify(map); // too small
return;
}
TreeNode<K,V> p = this, pl = left, pr = right, replacement;
if (pl != null && pr != null) {
TreeNode<K,V> s = pr, sl;
while ((sl = s.left) != null) // find successor
s = sl;
boolean c = s.red; s.red = p.red; p.red = c; // swap colors
TreeNode<K,V> sr = s.right;
TreeNode<K,V> pp = p.parent;
if (s == pr) { // p was s's direct parent
p.parent = s;
s.right = p;
}
else {
TreeNode<K,V> sp = s.parent;
if ((p.parent = sp) != null) {
if (s == sp.left)
sp.left = p;
else
sp.right = p;
}
if ((s.right = pr) != null)
pr.parent = s;
}
p.left = null;
if ((p.right = sr) != null)
sr.parent = p;
if ((s.left = pl) != null)
pl.parent = s;
if ((s.parent = pp) == null)
root = s;
else if (p == pp.left)
pp.left = s;
else
pp.right = s;
if (sr != null)
replacement = sr;
else
replacement = p;
}
else if (pl != null)
replacement = pl;
else if (pr != null)
replacement = pr;
else
replacement = p;
if (replacement != p) {
TreeNode<K,V> pp = replacement.parent = p.parent;
if (pp == null)
root = replacement;
else if (p == pp.left)
pp.left = replacement;
else
pp.right = replacement;
p.left = p.right = p.parent = null;
}
TreeNode<K,V> r = p.red ? root : balanceDeletion(root, replacement);
if (replacement == p) { // detach
TreeNode<K,V> pp = p.parent;
p.parent = null;
if (pp != null) {
if (p == pp.left)
pp.left = null;
else if (p == pp.right)
pp.right = null;
}
}
if (movable)
moveRootToFront(tab, r);
}
|