编程高手必学的内存知识 笔记
《编程高手必学的内存知识》学习笔记,涵盖虚拟内存、页表、进程地址空间、内存映射等核心概念。
编程高手必学的内存知识
作者: 海纳
为什么可用内存会远超物理内存?
虚拟内存的出现,是为了解决直接操作物理内存的系统无法支持多进程的问题。这里的难点主要是进程的地址空间非常小,而且多个进程的地址很容易发生冲突。所以在局部性原理的基础上,CPU设计者提出虚拟内存的方案将多个进程的地址空间隔离开,并且提供了巨大的内存空间。
我们可以总结一下,虚拟内存主要有下面两个特点:
第一,由于每个进程都有自己的页表,所以每个进程的虚拟内存空间就是相互独立的。进程也没有办法访问其他进程的页表,所以这些页表是私有的。这就解决了多进程之间地址冲突的问题。
第二,PTE中除了物理地址之外,还有一些标记属性的比特,比如控制一个页的读写权限,标记该页是否存在等。在内存访问方面,操作系统提供了更好的安全性。
另外,虚拟内存可以充分使用CPU提供的机制来完成很多重要的任务。例如,fork借用写保护来实现写时复制,JVM中借用改变某一个页的读权限来实现safepoint查询等等。
由于CPU对内存提供了更多保护的能力,所以X86架构的CPU把这种工作模式称为保护模式,与可以直接访问物理内存的实模式形成了对比。
X86体系结构中的实模式和保护模式
8086是16位的CPU,我们称8086的工作模式为实模式,它的特点是直接操作物理内存,内存管理容易出错,要十分小心,代码编写和调试都很困难。
之后出现的i386,则采用了和实模式不同的保护模式。相比实模式,i386中的保护模式,采用了页式管理,但它没有彻底放弃8086的段式管理,而是将段寄存器中的值由段基址变成了段选择子。段选择子本质是GDT表的下标值,段基址都转移到GDT中去了。
段式管理负责将逻辑地址转换为线性地址,或者称为虚拟地址,页式管理负责将线性地址映射到物理地址。i386的保护模式采用了段页式混合管理的模式,兼具了段式管理和页式管理的优点。
除了段页式内存管理这个不同之外,保护模式和实模式的区别还体现在中断描述符表(IDT)上。IDT是保护模式的一个重要组成部分,它保存着 i386 中断服务程序的入口地址。
8086和i386对X86架构的CPU影响巨大。直到今天,X86架构的CPU在上电以后,为了与8086保持兼容,还是运行在16位实模式下,也就是说所有访存指令访问的都是物理内存地址。在启动操作系统后,才会切换到保护模式下进行工作。
内存布局:应用程序是如何安排数据的?
IA-32机器上的Linux进程内存布局
在32位机器上,每个进程都具有4GB的寻址能力。Linux系统会默认将高地址的1GB空间分配给内核,剩余的低3GB是用户可以使用的用户空间。下图是32位机器上Linux进程的一个典型的内存布局。在实践中,我们可以通过cat /proc/pid/maps来查看某个进程的实际虚拟内存布局。
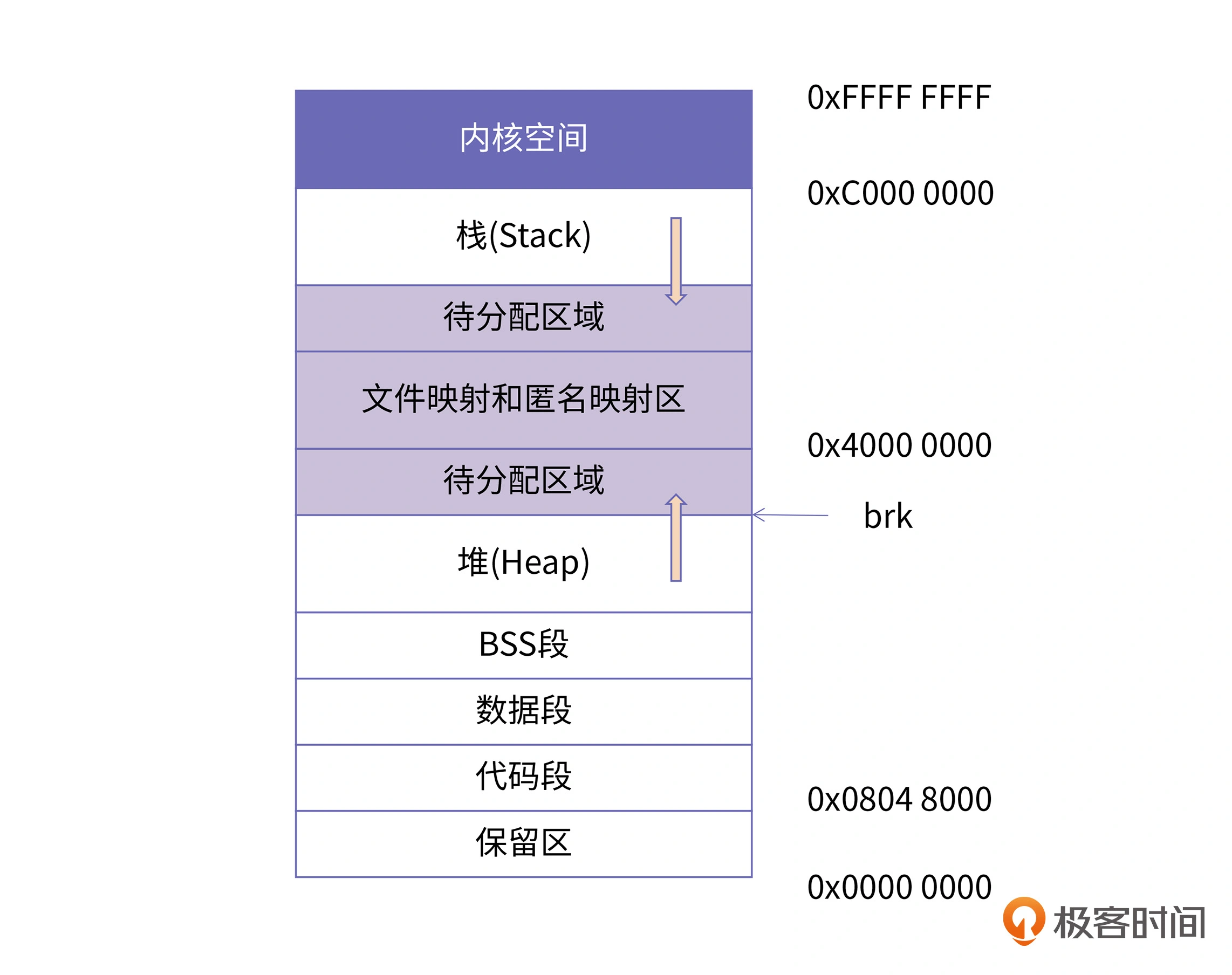
BSS 段这个缩写名字是Block Started by Symbol,但很多人可能更喜欢把它记作Better Save Space的缩写。
我们上述的布局分析都是基于Linux系统下关闭了进程地址随机化的选项。如果打开进程地址随机化的模式,其中的堆空间、栈空间和共享库映射的地址,在每次程序运行下都会不一样。这是因为内核在加载的过程中,会对这些区域的起始地址增加一些随机的偏移值,这能增加缓冲区溢出的难度。
Intel 64机器上的Linux进程内存布局
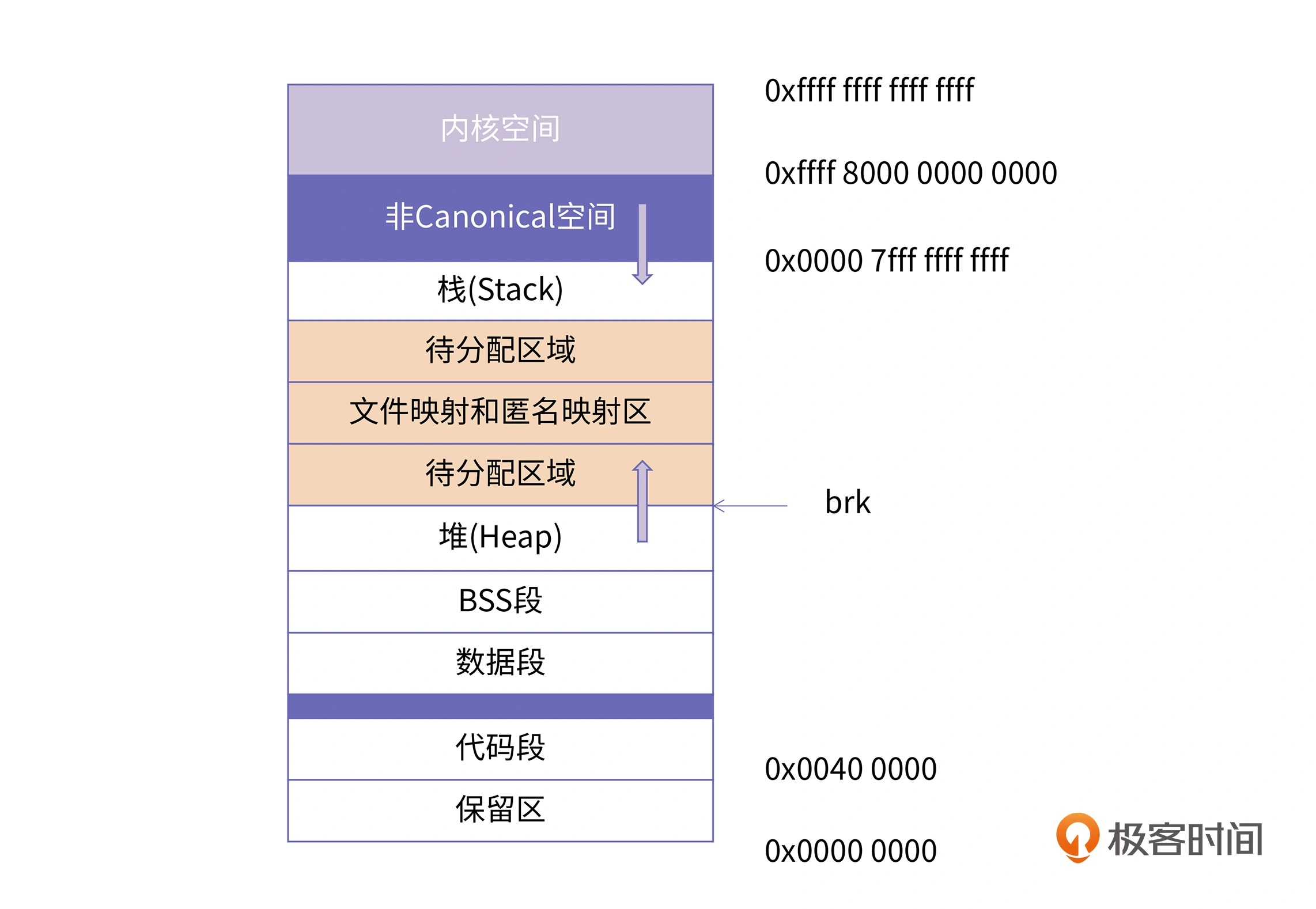
从图中你可以看到,在用户空间和内核空间之间有一个巨大的内存空洞。这块空间之所以用更深颜色来区分,是因为这块空间的不可访问是由CPU来保证的(这里的地址都不满足Intel 64的Canonical form)。
深入理解栈:从CPU和函数的视角看栈的管理
栈的魔法:从栈切换的角度理解进程和协程
栈切换的核心就是栈指针rsp寄存器的切换,只要我们想办法把rsp切换了就相当于换了执行单元的上下文环境。
静态链接:变量与内存地址是如何映射的?
在GNU/linux 下,GNU的binutils提供了一系列编程语言的工具程序,用来查看不同格式下的目标文件。今天我要给你重点介绍两个工具:readelf和objdump,这两个工具可以用来解析和读取上一节编译阶段生成的目标文件信息。
一般情况下,我在对二进制文件进行反汇编时会使用objdump工具,因为readelf工具没有提供反汇编的能力,它更多是用来解析二进制文件信息。
从源文件生成二进制可执行文件,这一过程主要包含了编译和链接两个步骤。其中,编译的作用是生成性能优越的机器码。对于编译单元内部的静态函数,可以在编译时通过相对地址的办法,生成call指令,因为无论将来调用者和被调用者被安置到什么地方,它们之间的相对距离不会发生变化。
而其他类型的变量和函数在编译时,编译器并不知道它们的最终地址,所以只能使用占位符(比如 0)来临时代替目标地址。
而链接器的任务是为所有变量和函数分配地址,并把被分配到的地址回写到调用者处。链接的过程主要分为两步,第一步是多文件合并,同时为符号分配地址,第二步则是将符号的地址回写到引用它的地方。其中,地址回写有一个专门的名字叫做重定位。重定位的过程依赖目标文件中的重定位表。