重构:改善既有代码的设计 笔记
本文整理自:《重构改善既有代码的设计》
作者:MartinFowler
出版时间:2015-08
重构,第一个案例
如果你发现自己需要为程序添加一个特性,而代码结构使你无法很方便地达成目的,那就先重构那个程序,使特性添加比较容易进行,然后再添加特性。
每当我要进行重构的时候,第一个步骤永远相同:我得为即将修改的代码建立一组可靠的测试环境。这些测试是必要的,因为尽管遵循重构手法可以使我避免绝大多数引入bug的情形,但我毕竟是人,毕竟有可能犯错。所以我需要可靠的测试。
测试过程中很重要的一部分,就是测试程序对于结果的报告方式,他们要么说”OK”,表示所有新字符串都和参考字符串一样,要么就列出失败清单,显示问题字符串的出现行号。这些测试都能够自我检验。是的,你必须让测试有能力自我检验,否则就得耗费大把时间来回比对,这会降低你的开发速度。
进行重构的时候, 我们需要依赖测试, 让它告诉我们是引入Bug。好的测试是重构的根本。花时间建立一个优良的测试机制是完全值得的,因为当你修改程序时,好测试会给你必要的安全保障。
重构原则
何谓重构
重构(名词):对软件内部结构的一种调整,目的是在不改变软件可观察行为的前提下,提高其可理解性,降低其修改成本。
首先,重构的目的是使软件更容易被理解和修改。你可以在软件内部做很多修改,但必须对软件可观察的外部行为只造成很小变化,或甚至不造成变化。与之形成对比的是性能优化。和重构一样,性能优化通常不会改变组件的行为(除了执行速度),只会改变其内部结构。但是两者出发点不同:性能优化往往使代码较难理解,但为了得到所需的性能你不得不那么做。
我要强调的第二点是:重构不会改变软件可观察的行为——重构之后软件功能一如以往。任何用户,不论最终用户或其他程序员,都不知道已经有东西发生了变化。
何时重构
三次法则
Don Roberts 给了我一条准则:第一次做某件事时只管去做;第二次做类似的事会产生反感,但无论如何还是可以去做;第三次再做类似的事,你就应该重构。
事不过三,三则重构。
复审代码时重构
如果是比较大的设计复审工作,那么在一个较大团队内保留多种观点通常会更好一些。此时直接展示代码往往不是最佳办法。我喜欢运用 UML 示意图展现设计,并以 CRC 卡展示软件情节。换句话说,我会和某个团队进行设计复审,而和单个复审者进行代码复审。
极限编程[ Beck , XP ]中的”结对编程”形式,把代码复审的积极性发挥到了极致。一旦采用这种形式,所有正式开发任务都由两名开发者在同一台机器上进行。这样便在开发过程中形成随时进行的代码复审工作,而重构也就被包含在开发过程内了。
重构的难题
修改接口
如今的问题是:该如何面对那些必须修改”已发布接口”的重构手法?
简言之,如果重构手法改变了已发布接口,你必须同时维护新旧两个接口,直到所有用户都有时间对这个变化做出反应。幸运的是,这不太困难。你通常都有办法把事情组织好,让旧接口继续工作。请尽量这么做:让旧接口调用新接口。当你要修改某个函数名称时,请留下旧函数,让它调用新函数。千万不要复制函数实现,那会让你陷入重复代码的泥悼中难以自拔。你还应该使用 Java 提供的 deprecation (不建议使用)设施,将旧接口标记为 deprecated 。这么一来你的调用者就会注意到它了。
这个过程的一个好例子就是 Java 容器类(集合类 , collection classes)。 Java 2的新容器取代了原先一些容器。当 Java 2容器发布时, JavaSoft 花了很大力气来为开发者提供一条顺利迁徙之路。
“保留旧接口”的办法通常可行,但很烦人。起码在一段时间里你必须构造并维护一些额外的函数。它们会使接口变得复杂,使接口难以使用。还好我们有另一个选择:不要发布接口。当然我不是说要完全禁止,因为很明显你总得发布一些接口。如果你正在建造供外部使用的 API (就像 Sim 公司所做的那样),就必须发布接口。之所以说尽量不要发布,是因为我常常看到一些开发团队公开了太多接口。我曾经看到一支三人团队这么工作:每个人都向另外两人公开发布接口。这使他们不得不经常来回维护接口,而其实他们原本可以直換进入程序库,径行修改自己管理的那一部分,那会轻松许多。过度强调代码所有权的团队常常会犯这种错误。发布接口很有用,但也有代价。所以除非真有必要,不要发布接口。这可能意味需要改变你的代码所有权观念,让每个人都可以修改别人的代码,以适应接口的改动。以结对编程的方式完成这一切通常是个好主意。
不要过早发布接口。请修改你的代码所有权政策,使重构更顺畅。
代码的坏味道
Duplicated Code 重复代码
LongMethod 过长方法
我们遵循这样一条原则:每当感觉需要以注释来说明点什么的时候,我们就把需要说明的东西写进一个独立函数中,并以其用途(而非实现手法)命名。
Large Class 过长类
Long Parameter List 过长参数列表
Divergent Change 发散式变化
我们希望软件能够更容易被修改——毕竟软件再怎么说本来就该是”软”的。**一旦需要修改,我们希望能够跳到系统的某一点,只在该处做修改。**如果不能做到这点,你就嗅出两种紧密相关的刺鼻味道中的一种了。
如果某个类经常因为不同的原因在不同的方向上发生变化 ,Divergent Change就出现了。当你看着一个类说:”呃,如果新加入一个数据库,我必须修改这三个函数;如果新出现一种金融工具,我必须修改这四个函数。”那么此时也许将这个对象分成两个会更好,这么一来每个对象就可以只因一种变化而需要修改。当然,往往只有在加入新数据库或新金融工具后,你才能发现这一点。针对某一外界变化的所有相应修改,都只应该发生在单一类中,而这个新类内的所有内容都应该反应此变化。为此,你应该找出某特定原因而造成的所有变化,然后运用Extract Class将它们提炼到另一个类中。
Shotgun Surgery 霰弹式修改
Shotgun Surgery 类似 Divergent Change ,但恰恰相反。如果每遇到某种变化,你都必须在许多不同的类内做出许多小修改,你所面临的坏味道就是Shotgun Surgery。如果需要修改的代码散布四处,你不但很难找到它们,也很容易忘记某个重要的修改。
这种情况下你应该使用Move Method和 Move Filed把所有需要修改的代码放进同一个类。如果眼下没有合适的类可以安置这些代码,就创造一个。通常可以运用Inline Class把一系列相关行为放进同一个类 。 这可能会造成少量Divergent Change ,但你可以轻易处理它。
Divergent Change是指”一个类受多种变化的影响”,Shotgun Surgery则是指”一种变化引发多个类相应修改”。这两种情况下你都会希望整理代码使”外界变化”与”需要修改的类”趋于一一对应。
Feature Envy 特性依恋
对象技术的全部要点在于:这是一种”将数据和对数据的操作行为包装在一起”的技术。有一种经典气味是:函数对某个类的兴趣高过对自己所处类的兴趣。这种孺慕之情最通常的焦点便是数据。无数次经验里,我们看到某个函数为了计算某个值,从另一个对象那儿调用几乎半打的取值函数。疗法显而易见:把这个函数移至另一个地点。你应该使用Move Method把它移到它该去的地方。有时候函数中只有一部分受这种依恋之苦,这时候你应该使用Extract Method把这一部分提炼到独立函数中,再使用Move Method带它去它的梦中家园。
当然,并非所有情况都这么简单 。一个函数往往会用到几个类的功能,那么它究竟该被置于何处呢?我们的原则是:判断哪个类拥有最多被此函数使用的数据,然后就把这个函数和那些数据摆在一起。如果先以Extract Method将这个函数分解为数个较小函数并分别置放于不同地点,上述步骤也就比较容易完成了。
有几个复杂精巧的模式破坏了这个规则。说起这个话题, GoF的Strategy和Visitor立刻跳入我的脑海,Kent Beck的Self Delegation [Beck]也在此列。使用这些模式是为了对抗坏味道Divergent Change 。最根本的原则是:将总是一起变化的东西放在一块儿。数据和引用这些数据的行为总是一起变化的,但也有例外。如果例外出现,我们就搬移那些行为,保持变化只在一地发生。Strategy和Visitor使你得以轻松修改函数行为,因为它们将少量需被扭写的行为隔离开来―当然也付出了”多一层间接性”的代价。
Data Clumps 数据泥团
数据项就像小孩子,喜欢成群结队地待在一块儿。你常常可以在很多地方看到相同的三四项数据:两个类中相同的字段、许多函数签名中相同的参数。这些总是绑在一起出现的数据真应该拥有属于它们自己的对象。首先请找出这些数据以字段形式出现的地方, 运用Extract Class将它们提炼到一个独立对象中。然后将注意力转移到函数签名上,运用Introduce Parameter Object(或Preserve Whole Object为它减肥。这么做的直接好处是可以将很多参数列缩短,简化函数调用。是的,不必在意Data Clumps只用上新对象的一部分字段,只要以新对象取代两个(或更多)字段,你就值回票价了。
一个好的评判办法是:删掉众多数据中的一项。这么做,其他数据有没有因而失去意义?如果它们不再有意义,这就是个明确信号:你应该为它们产生一个新对象。
减少字段和参数的个数,当然可以去除一些坏味道,但更重要的是:一旦拥有新对象,你就有机会让程序散发出一种芳香。得到新对象后,你就可以着手寻找Feature Envy,这可以帮你指出能够移至新类中的种种程序行为。不必太久, 所有的类都将在它们的小小社会中充分发挥价值。
Primitive Obsession 基本类型偏执
如果你有一组应该总是被放在一起的字段,可以运用Extract Class。如果你在参数列表中看到基本型数据,不妨试试Introduce Parameter Object。如果你发现自己正从数组中挑选数据,可运用Replace Array with Object。
Switch Statements switch 语句
面向对象程序的一个最明显特征就是:少用switch(或case) 语句。从本质上说,switch语句的问题在于重复。你常会发现同样的switch语句散布于不同地点。如果要为它添加一个新的case子句, 就必须找到所有switch语句并修改它们。面向对象中的多态概念可为此带来优雅的解决办法。
大多数时候,一看到switch语句,你就应该考虑以多态来替换它。问题是多态该出现在哪儿?switch语句常常根据类型码进行选择,你要的是”与该类型码相关的函数或类”,所以应该使用Extract Method将switch语句提炼到一个独立函数中,再以Move Method将它搬移到需要多态性的那个类里。此时你必须决定是否使用Replace Type Code with Subclasses或Replace Type Code with State/Strategy 。一旦这样完成继承结构之后,你就可以运用Replace Conditional with Polymorphism了。
如果你只是在单一函数中有些选择事例,且并不想改动它们,那么多态就有点杀鸡用牛刀了。这种情况下Replace Parameter with Explicit Methods是个不错的选择。如果你的选择条件之一是null,可以试试Introduce Null Object 。
ParallelInheritanceHierarchies 平行继承体系
Parallel Inheritance hierarchies其实是Shotgun Surgery的特殊情况。在这种情况下,每当你为某个类增加一个子类,必须也为另一个类相应增加一个子类。如果你发现某个继承体系的类名称前缀和另一个继承体系的类名称前缀完全相同,便是闻到了这种坏味道。
消除这种重复性的一般策略是:让一个继承体系的实例引用另一个继承体系的实例。如果再接再励运用Move method和Move Field,就可以将引用端的继承体系消弭于无形。
LazyClass 冗余类
SpeculativeGenerality 夸夸其谈未来性
这个令我们十分敏感的坏味道,命名者是 Brian Foote。当有人说”噢,我想我们总有一天需要做这事”,并因而企图以各式各样的钩子和特殊情况来处理一些非必要的事情,这种坏味道就出现了。那么做的结果往往造成系统更难理解和维护。如果所有装置都会被用到,那就值得那么做;如果用不到,就不值得。用不上的装置只会挡你的路,所以,把它搬开吧。
如果你的某个抽象类其实没有太大作用,请运用Collapse Hierarchy。不必要的委托可运用Inline class除掉。如果函数的某些参数未被用上,可对它实施Remove Parameter。如果函数名称带有多余的抽象意味,应该对它实施Rename Method,让它现实一些。
Temporary Field 令人迷惑的临时字段
Message Chains (过度耦合的消息链)
如果你看到用户向一个对象请求另一个对象,然后再向后者请求另一个对象,然后再请求另一个对象……这就是消息链。实际代码中你看到的可能是一长串getThis()或一长串临时变量。采取这种方式,意味客户代码将与查找过程中的导航结构紧密耦合。一旦对象间的关系发生任何变化,客户端就不得不做出相应修改。
这时候你应该使用Hide Delegate。你可以在消息链的不同位置进行这种重构手法。理论上可以重构消息链上的任何一个对象,但这么做往往会把一系列对象(intermediate object)都变成Middle Man。通常更好的选择是:先观察消息链最终得到的对象是用来干什么的,看看能否以Extract Method把使用该对象的代码提炼到一个独立函数中,再运用Move Method把这个函数推入消息链。如果这条链上的某个对象有多位客户打算航行此航线的剩余部分,就加一个函数来做这件事。
有些人把任何函数链都视为坏东西,我们不这样想。呵呵,我们的冷静镇定是出了名的,起码在这件事上是这样
Middle Man 中间人
对象的基本特征之一就是封装——对外部世界隐藏其内部细节。封装往往伴随委托。比如说你问主管是否有时间参加一个会议,他就把这个消息”委托”给他的记事簿,然后才能回答你。很好,你没必要知道这位主管到底使用传统记事簿或电子记事簿亦或秘书来记录自己的约会。
但是人们可能过度运用委托。你也许会看到某个类接口有一半的函数都委托给其他类,这样就是过度运用。这时应该使用Remove Middle Man,直接和真正负责的对象打交道。如果这样”不干实事”的函数只有少数几个,可以运用Inline Method把它们放进调用端。如果这些Middle Man还有其他行为,可以运用Replace Delegation with Inheritance把它变成实责对象的子类,这样你既可以扩展原对象的行为,又不必负担那么多的委托动作。
Inappropriate Intimacy 过度亲密
过分狎昵的类必须拆散。你可以采用Move Method和Move Field帮它们划清界线,从而减少狎昵行径。你也可以看看是否可以运用Change Bidirectional Association to Unidirectional让其中一个类对另一个斩断情丝。如果两个类实在是情投意合,可以运用Extract Class把两者共同点提炼到一个安全地点,让它们坦荡地使用这个新类。或者也可以尝试运用Hide Delegate让另一个类来为它们传递相思情。
继承往往造成过度亲密,因为子类对父类的了解总是超过后者的主观愿望。如果你觉得该让这个孩子独自生活了,请运用Replace Inheritance with Delegation让它离开继承体系。
Alternative Classes with Different Interfaces 异曲同工的类
如果两个函数做同一件事,却有着不同的签名,请运用Rename Method根据它们的用途重新命名。但这往往不够,请反复运用Move Method将某些行为移入类,直到两者的协议一致为止。如果你必须重复而赘余地移入代码才能完成这些,或许可运用Extract Superclass为自己赎点罪。
Incomplete Library Class 不完整的库类
如果你只想修改库类的一两个函数,可以运用Introduce Foreign Method;如果想要添加一大堆额外行为,就得运用Introduce Local Extension。
Data Class 数据类
所谓Data Class是指:它们拥有一些字段,以及用于访问(读写)这些字段的函数,除此之外一无长物。这样的类只是一种不会说话的数据容器,它们几乎一定被其他类过分细琐地操控着。这些类早期可能拥有public字段,果真如此你应该在别人注意到它们之前,立刻运用Encapsulate Field将它们封装起来。如果这些类内含容器类的字段,你应该检查它们是不是得到了恰当的封装:如果没有,就运用Encapsulate Collection把它们封装起来。对于那些不该被其他类修改的字段,请运用Remove Setting Method。
然后,找出这些取值设值函数被其他类运用的地点。尝试以Move Method把那些调用行为搬移到Data Class。如果无法搬移整个函数,就运用Extract Method产生一个可被搬移的函数。不久之后你就可以运用Hide Method把这些取值/设值函数隐藏起来了。
Refused Bequest 拒绝继承
子类应该继承父类的函数和数据。但如果它们不想或不需要继承,又该怎么办呢?它们得到所有礼物,却只从中挑选几样来玩!
按传统说法,这就意味着继承体系设计错误。你需要为这个子类新建一个兄弟类,再运用Push Down Method和Push Down Field把所有用不到的函数下推给那个兄弟。这样一来,父类就只持有所有子类共享的东西。你常常会听到这样的建议:所有父类都应该是抽象(abstract)的。
既然使用”传统说法”这个略带贬义的词,你就可以猜到,我们不建议你这么做,起码不建议你每次都这么做。我们经常利用继承来复用一些行为,并发现这可以很好地应用于日常工作。这也是一种坏味道,我们不否认,但气味通常并不强烈。所以我们说:如果Refused Bequest引起困惑和问题,请遵循传统忠告。但不必认为你每次都得那么做。十有八九这种坏味道很淡,不值得理睬。
如果子类复用了父类的行为(实现),却又不愿意支持父类的接口, Refused Bequest的坏味道就会变得浓烈。拒绝继承父类的实现,这一点我们不介意;但如果拒绝继承父类的接口,我们不以为然。不过即使你不愿意继承接口,也不要胡乱修改继承体系,应该运用Replace Inheritance with Delegation来达到目的
Comments 注释过多
别担心,我们并不是说你不该写注释。从嗅觉上说, Comments不是一种坏味道,事实上它们还是一种香味呢。我们之所以要在这里提到 Comments,是因为人们常把它当作除臭剂来使用。常常会有这样的情况:你看到一段代码有着长长的注释,然后发现,这些注释之所以存在乃是因为代码很糟糕。这种情况的发生次数之多,实在令人吃惊。
Comments可以带我们找到本章先前提到的各种坏味道。找到坏味道后,我们首先应该以各种重构手法把坏味道去除。完成之后我们常常会发现:注释已经变得多余了,因为代码已经清楚说明了一切。
如果你需要注释来解释一块代码做了什么,试试Extract Method;如果函数已经提炼出来,但还是需要注释来解释其行为,试试Rename Method;如果你需要注释说明某些系统的需求规格,试试Introduce Assertion。
当你感觉需要撰写注释时,请先尝试重构,试着让所有注释都变得多余。
如果你不知道该做什么,这才是注释的良好运用时机。除了用来记述将来的打算之外,注释还可以用来标记你并无十足把握的区域。你可以在注释里写下自己”为什么做某某事”。这类信息可以帮助将来的修改者,尤其是那些健忘的家伙。
重构列表
重构的记录格式
介绍重构时,我采用一种标准格式。每个重构手法都有如下五个部分。
- 首先是名称(name)。建造一个重构词汇表,名称是很重要的。这个名称也就是我将在本书其他地方使用的名称。
- 名称之后是一个简短概要(summary)。简单介绍此一重构手法的适用情景以及它所做的事情。这部分可以帮助你更快找到你所需要的重构手法。
- 动机(motivation)为你介绍”为什么需要这个重构”和”什么情况下不该使用这个重构”。
- 做法(mechanics)简明扼要地一步一步介绍如何进行此一重构。
- 范例(examples)以一个十分简单的例子说明此重构手法如何运作。
概要”包括三个部分:(1)一句话,介绍这个重构能够帮助解决的问题;(2)段简短陈述,介绍你应该做的事:(3)一幅速写图,简单展现重构前后示例:有时候我展示代码,有时候我展示UML图。总之,哪种形式能更好呈现该重构的本质,我就使用哪种形式(本书所有UML图都根据实现观点而画[Fowler,,UML]。)如果你以前见过这一重构手法,那么速写图能够让你迅速了解这一重构的概况;如果你不曾见过这个重构,可能就需要浏览整个范例,才能得到较好的认识。
“做法”出自我自己的笔记。这些笔记是为了让我在一段时间不做某项重构之后还能记得怎么做。它们也颇为简洁,通常不会解释”为什么要这么做那么做”。我会在”范例”中给出更多解释。这么一来,”做法”就成了简短的笔记。如果你知道该使用哪个重构,但记不清具体步骤,可以参考”做法”部分(至少我是这么使用它们的);如果你初次使用某个重构,可能只参考”做法”还不够,你还需要阅读”范例”。
撰写”做法”的时候,我尽量将重构的每个步骤都写得简短。我强调安全的重构方式,所以应该采用非常小的步骤,并且在每个步骤之后进行测试。真正工作时,我通常会采用比这里介绍的”婴儿学步”稍大些的步骤,然而一旦出问题,我就会撤销上一步,换用比较小的步骤。这些步骤还包含一些特定状况的参考,所以它们也有检验表的作用。我自己经常忘掉这些该做的事情。
“范例”像是简单而有趣的教科书。我使用这些范例是为了帮助解释重构的基本要素,最大限度地避免其他枝节,所以我希望你能原谅其中的简化工作(它们当然不是优秀商用对象设计的适当例子)。不过我敢肯定,你一定能在你手上那些更复杂的情况中使用它们。某些十分简单的重构干脆没有范例,因为我觉得为它们加上个范例不会有多大意义。
更明确地说,加上范例仅仅是为了阐释当时讨论的重构手法。通常那些代码最终仍有其他问题,但修正那些问题需要用到其他重构手法。某些情况下数个重构经常被一并运用,这时候我会把某些范例拿到另一个重构中继续使用。大部分时候,个范例只为一项重构而设计,这么做是为了让每一项重构手法自成一体,因为这份重构列表的首要目的还是作为参考工具。
这些重构的成熟度如何?
重构的基本技巧—小步前进、频繁测试——已经得到多年的实践检验。所以,我敢保证,重构的这些基础思想是非常可靠的。
重新组织方法
Extract Method 提炼函数
动机
有几个原因造成我喜欢简短而命名良好的函数。首先,如果每个函数的粒度都很小,那么函数被复用的机会就更大;其次,这会使高层函数读起来就像一系列注释:再次,如果函数都是细粒度,那么函数的覆写也会更容易些。
人们有时会问我,一个函数多长才算合适?在我看来,长度不是问题,关键在于函数名称和函数本体之间的语义距离。如果提炼可以强化代码的清晰度,那就去做,就算函数名称比提炼出来的代码还长也无所谓。
做法
创造一个新函数,根据这个函数的意图来对它命名(以它”做什么”来命名,而不是以它”怎样做”命名)
- →即使你想要提炼的代码非常简单,例如只是一条消息或一个函数调用,只要新函数的名称能够以更好的方式昭示代码意图,你也应该提炼它。但如果你想不出一个更有意义的名称,就别动。
将提炼出的代码从源函数复制到新建的目标函数中。
仔细检查提炼出的代码,看看其中是否引用了”作用域限于源函数”的变量(包括局部变量和源函数参数)。
检查是否有”仅用于被提炼代码段”的临时变量。如果有,在目标函数中将它们声明为临时变量。
检査被提炼代码段,看看是否有任何局部变量的值被它改变。如果一个临时变量值被修改了,看看是否可以将被提炼代码段处理为一个查询,并将结果赋值给相关变量。如果很难这样做,或如果被修改的变量不止一个,你就不能仅仅将这段代码原封不动地提炼出来。你可能需要先使用Split Temporary Ariable,然后再尝试提炼。也可以使用Replace Temp with Query将临时变量消灭掉。
将被提炼代码段中需要读取的局部变量,当作参数传给目标函数。
处理完所有局部变量之后,进行编译。
在源函数中,将被提炼代码段替换为对目标函数的调用。
- 如果你将任何临时变量移到目标函数中,请检查它们原本的声明式是否在被提炼代码段的外围。如果是,现在你可以删除这些声明式了
编译,测试。
临时变量往往为数众多,甚至会使提炼工作举步维艰。这种情况下,我会尝试先运用Replace Temp with Query(减少临时变量。如果即使这么做了提炼依旧困难重重,我就会动用Replace Method with Method Object,这个重构手法不在乎 代码中有多少临时变量,也不在乎你如何使用它们。
Inline Method 内联方法
一个函数的本体与名称同样清楚易懂。
在函数调用点插入函数本体,然后移除该函数。
1 | int getRating(){ |
Inline Temp 内联临时变量
你有一个临时变量,只被一个简单表达式赋值一次,而它妨碍了其他重构手法。
将所有对该变量的引用动作,替换为对它赋值的那个表达式自身。
1 | double basePrice= anorder.basePrice(); |
Replace Temp with Query 用查询方法代替临时变量
你的程序以一个临时变量保存某一表达式的运算结果。
将这个表达式提炼到一个独立函数中。将这个临时变量的所有引用点替换为对新函数的调用。此后,新函数就可被其他函数使用。
1 | double basePrice =quantity *_itemPrice: |
替换为:
1 | if(basePrice())> 1000 |
动机
临时变量的问题在于:它们是暂时的,而且只能在所属函数内使用。由于临时变量只在所属函数内可见,所以它们会驱使你写出更长的函数,因为只有这样你才能访问到需要的临时变量。如果把临时变量替换为一个查询,那么同一个类中的所有函数都将可以获得这份信息。这将带给你极大帮助,使你能够为这个类编写更清晰的代码。
Replace Temp with Query往往是你运用Extract Method之前必不可少的个步骤。局部变量会使代码难以被提炼,所以你应该尽可能把它们替换为查询式。
这个重构手法较为简单的情况是:临时变量只被赋值一次,或者赋值给临时变量的表达式不受其他条件影响。其他情况比较棘手,但也有可能发生。你可能需要先运用Split Temporary Variable或Separate Query from Modifier使情况变得简单一些,然后再替换临时变量。如果你想替换的临时变量是用来收集结果的,就需要将某些程序逻辑(例如循环)复制到查询函数去。
做法
首先是简单情况:
- 找出只被赋值一次的临时变量。
- →如果某个临时变量被赋值超过一次,考虑使用Split Temporary Variable将它分割成多个变量。
- 将该临时变量声明为final。
- 编译。
- 这可确保该临时变量的确只被赋值一次。
- 将”对该临时变量赋值”之语句的等号右侧部分提炼到一个独立函数中。
- →首先将函数声明为private.日后你可能会发现有更多类需要使用它,那时放松对它的保护也很容易
- →确保提炼出来的函数无任何副作用,也就是说该函数并不修改任何对象内容。如果它有副作用,就对它进行Separate Query from Modifler
- 编译,测试。
- 在该临时变量身上实施Inline Temp。
我们常常使用临时变量保存循环中的累加信息。在这种情况下,整个循环都可以被提炼为一个独立函数,这也使原本的函数可以少掉几行扰人的循环逻辑。有时候,你可能会在一个循环中累加好几个值。这种情况下你应该针对每个累加值重复一遍循环,这样就可以将所有临时变量都替换为查询。当然,循环应该很简单,复制这些代码时才不会带来危险。
运用此手法,你可能会担心性能问题。和其他性能问题一样,我们现在不管它,因为它十有八九根本不会造成任何影响。若是性能真的出了问题,你也可以在优化时期解决它。代码组织良好,你往往能够发现更有效的优化方案:如果没有进行重构,好的优化方案就可能与你失之交臂。如果性能实在太糟糕,要把临时变量放回去也是很容易的。
Introduce Explaining Variable 引入解释性变量
你有一个复杂的表达式,将该复杂表达式(或其中一部分)的结果放进一个临时变量,以此变量名称来解释表达式用途。
1 | if ((platform.toUppercase().indexof("MAC")>-1)&& |
替换为:
1 | final boolean isMacos=platform.toUppercase() indexof("MAC")>-1: |
动机
表达式有可能非常复杂而难以阅读。这种情况下,临时变量可以帮助你将表达式分解为比较容易管理的形式。
在条件逻辑中,Introduce Explaining Variable特别有价值:你可以用这项重构将每个条件子句提炼出来,以一个良好命名的临时变量来解释对应条件子句的意义。使用这项重构的另一种情况是,在较长算法中,可以运用临时变量来解释每步运算的意义。
Introduce Explaining Variable是一个很常见的重构手法,但我得承认,我并不常用它。我几乎总是尽量使用Extract Method(来解释一段代码的意义。毕竟临时变量只在它所处的那个函数中才有意义,局限性较大,函数则可以在对象的整个生命中都有用,并且可被其他对象使用。但有时候,当局部变量使Extract Method难以进行时,我就使用Introduce Explaining Variable。
Split Temporary Variable 分解临时变量
你的程序有某个临时变量被赋值超过一次,它既不是循环变量,也不被用于收集计算结果针对每次赋值,创造一个独立、对应的临时变量。
1 | double temp = 2*(_height +_width); |
替换为:
1 | final double perimeter = 2*(_height+_width); |
动机
临时变量有各种不同用途,其中某些用途会很自然地导致临时变量被多次赋值。”循环变量”和”结果收集变量”就是两个典型例子:循环变量(loop variable)[Beck]会随循环的每次运行而改变(例如for(inti=0;i<10;i++)语句中的i);结果收集变量(collecting temporary variable)[Beck]负责将”通过整个函数的运算”而构成的某个值收集起来。
除了这两种情况,还有很多临时变量用于保存一段冗长代码的运算结果,以便稍后使用。这种临时变量应该只被赋值一次。如果它们被赋值超过一次,就意味它们在函数中承担了一个以上的责任。如果临时变量承担多个责任,它就应该被替换(分解)为多个临时变量,每个变量只承担一个责任。同一个临时变量承担两件不同的事情,会令代码阅读者糊涂。
Remove Assignments to Parameters 移除对参数的赋值
代码对一个参数进行赋值。以一个临时变量取代该参数的位置。
1 | int discount (int inputval, int quantity, int yearToDate){ |
替换为:
1 | int discount (int inputval, int quantity, int yearToDate){ |
Replace Method with Method Object 以函数对象取代函数
你有一个大型函数,其中对局部变量的使用使你无法采用Extract Method。将这个函数放进一个单独对象中,如此一来局部变量就成了对象内的字段。然后你可以在同一个对象中将这个大型函数分解为多个小型函数。
1 | class Order... |
替换为: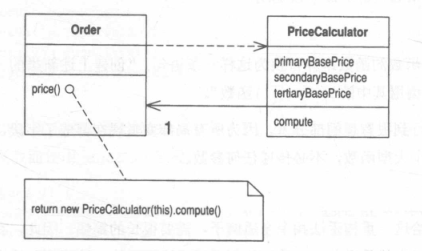
做法
我厚着脸皮从Kent Beck[Beck]那里偷来了下列做法。
- 建立一个新类,根据待处理函数的用途,为这个类命名。
- 在新类中建立一个final字段,用以保存原先大型函数所在的对象。我们将这个字段称为”源对象”。同时,针对原函数的每个临时变量和每个参数在新类中建立一个对应的字段保存之。
- 在新类中建立一个构造函数,接收源对象及原函数的所有参数作为参数。
- 在新类中建立一个compute()函数。
- 将原函数的代码复制到compute()函数中。如果需要调用源对象的任何函数,请通过源对象字段调用。
- 编译。
- 将旧函数的函数本体替换为这样一条语句:”创建上述新类的一个新对象而后调用其中的compute()函数”
- 现在进行到很有趣的部分了。因为所有局部变量现在都成了字段,所以你可以任意分解这个大型函数,不必传递任何参数。
在对象之间移动特性
类往往会因为承担过多责任而变得臃肿不堪。这种情况下,我会使用Extract Class将一部分责任分离出去。如果一个类变得太”不负责任”,我就会使用Inline Class将它融入另一个类。如果一个类使用了另一个类,运用Hide Delegate将这种关系隐藏起来通常是有帮助的。有时候隐藏委托类会导致拥有者的接口经常变化,此时需要使用Remove Middle Man。
本章的最后两项重构—Introduce Foreign Method和Introduce Local Extension比较特殊。只有当我不能访问某个类的源码,却又想把其他责任移进这个不可修改的类时,我才会使用这两个重构手法。如果我想加入的只是一或两个函数,就会使用Introduce Foreign Method;如果不止一两个函数,就使用Introduce Local Extension。
Move Method 搬移函数
你的程序中,有个函数与其所驻类之外的另一个类进行更多交流:调用后者,或被后者调用。
在该函数最常引用的类中建立一个有着类似行为的新函数。将旧函数变成一个单纯的委托函数,或是将旧函数完全移除。
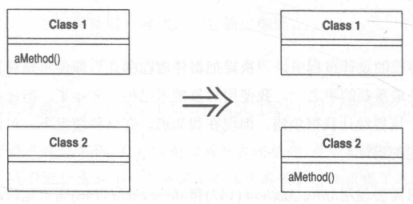
Move Field 搬移字段
在你的程序中,某个字段被其所驻类之外的另一个类更多地用到。
在目标类新建一个字段,修改源字段的所有用户,令它们改用新字段。
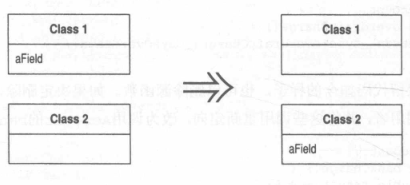
Extract Class 提炼类
某个类做了应该由两个类做的事。
建立一个新类,将相关的字段和函数从旧类搬移到新类。

做法
- 决定如何分解类所负的责任。
- 建立一个新类,用以表现从旧类中分离出来的责任。
- →如果旧类剩下的责任与旧类名称不符,为旧类更名
- 建立”从旧类访问新类”的连接关系。
- →有可能需要一个双向连接。但是在真正需要它之前,不要建立”从新类通往旧类”的连接。
- 对于你想搬移的每一个字段,运用Move Field搬移之。
- 每次搬移后,编译、测试
- 使用Move Method将必要函数搬移到新类。先搬移较低层函数(也就是被其他函数调用”多于”调用其他函数”者),再搬移较高层函数。
- 每次搬移之后,编译、测试。
- 检查,精简每个类的接口。
- →如果你建立起双向连接,检查是否可以将它改为单向连接。
- 决定是否公开新类。如果你的确需要公开它,就要决定让它成为引用对象还是不可变的值对象。
Inline Class 将类内联化
某个类没有做太多事情。
将这个类的所有特性搬移到另一个类中,然后移除原类。

Hide Delegate 隐藏”委托关系”
客户通过一个委托类来调用另一个对象。
在服务类上建立客户所需的所有函数,用以隐藏委托关系。
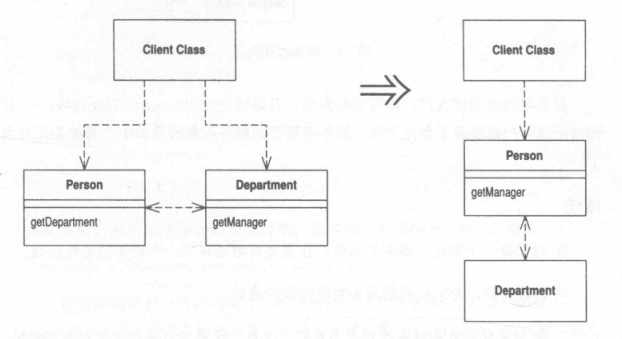
Remove Middle Man 移除中间人
某个类做了过多的简单委托动作。
让客户直接调用受托类。
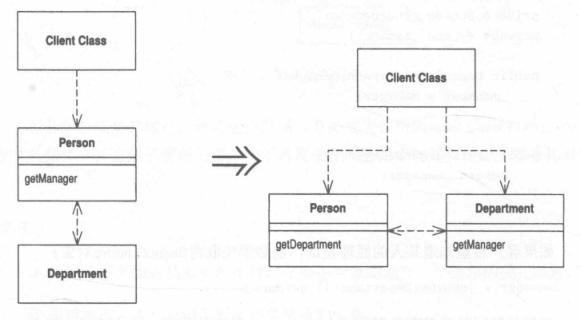
Introduce Foreign Method 引入外加函数
你需要为提供服务的类增加一个函数,但你无法修改这个类。
在客户类中建立一个函数,并以第一参数形式传入一个服务类实例。
1 | Date newstart= new Date (previousEnd.getYear(), |
替换为:
1 | Date newstart = nextDay(previousEnd); |
动机
这种事情发生过太多次了:你正在使用一个类,它真的很好,为你提供了需要的所有服务。而后,你又需要一项新服务,这个类却无法供应。于是你开始咒骂:”为什么不能做这件事?”如果可以修改源码,你便可以自行添加一个新函数:如果不能,你就得在客户端编码,补足你要的那个函数。
如果你发现自己为一个服务类建立了大量外加函数,或者发现有许多类都需要同样的外加函数,就不应该再使用本项重构,而应该使用Introduce Local Extension。
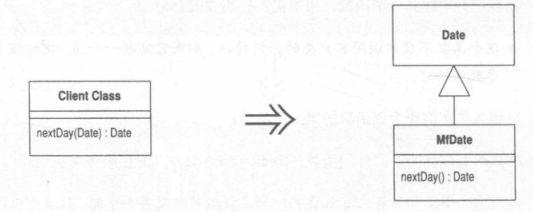
Introduce Local Extension 引入本地扩展
你需要为服务类提供一些额外函数,但你无法修改这个类。
建立一个新类,使它包含这些额外函数。让这个扩展品成为源类的子类或包装类。
动机
很遗憾,类的作者无法预知未来,他们常常没能为你预先准备一些有用的函数。如果你可以修改源码,最好的办法就是直接加入自己需要的函数。但你经常无法修改源码。如果只需要一两个函数,你可以使用Introduce Foreign Method。但如果你需要的额外函数超过两个,外加函数就很难控制它们了。所以,你需要将这些函数组织在一起,放到一个恰当地方去。要达到这一目的,两种标准对象技术子类化(subclassing)和包装(wrapping)—是显而易见的办法。这种情况下,我把子类或包装类统称为本地扩展(local extension)。
所谓本地扩展是一个独立的类,但也是被扩展类的子类型:它提供源类的一切特性,同时额外添加新特性。在任何使用源类的地方,你都可以使用本地扩展取而代之。
使用本地扩展使你得以坚持”函数和数据应该被统一封装”的原则。如果你直把本该放在扩展类中的代码零散地放置于其他类中,最终只会让其他这些类变得过分复杂,并使得其中函数难以被复用。
在子类和包装类之间做选择时,我通常首选子类,因为这样的工作量比较少。制作子类的最大障碍在于,它必须在对象创建期实施。如果我可以接管对象创建过程,那当然没问题;但如果你想在对象创建之后再使用本地扩展,就有问题了。此外,子类化方案还必须产生一个子类对象,这种情况下,如果有其他对象引用了旧对象,我们就同时有两个对象保存了原数据!如果原数据是不可修改的,那也没问题,我可以放心进行复制:但如果原数据允许被修改,问题就来了,因为一个修改动作无法同时改变两份副本。这时候我就必须改用包装类。使用包装类时,对本地扩展的修改会波及原对象,反之亦然。
做法
- 建立一个扩展类,将它作为原始类的子类或包装类。
- 在扩展类中加入转型构造函数。
- →所谓”转型构造函数”是指”接受原对象作为参数”的构造函数。如果采用子类化方案,那么转型构造函数应该调用适当的父类构造函数;如果采用包装类方案,那么转型构造函数应该将它得到的传入参数以实例变量的形式保存起来,用作接受委托的原对象。
- 在扩展类中加入新特性。
- 根据需要,将原对象替换为扩展对象
- 将针对原始类定义的所有外加函数搬移到扩展类中。
简化条件表达式
Replace Nested Conditional with Guard Clauses 以卫语句取代嵌套条件表达式
函数中的条件逻辑使人难以看清正常的执行路径。
使用卫语句表现所有特殊情况。

谓语句是我个人比较喜欢的一种处理方式,通俗点说就是让函数尽快结束。
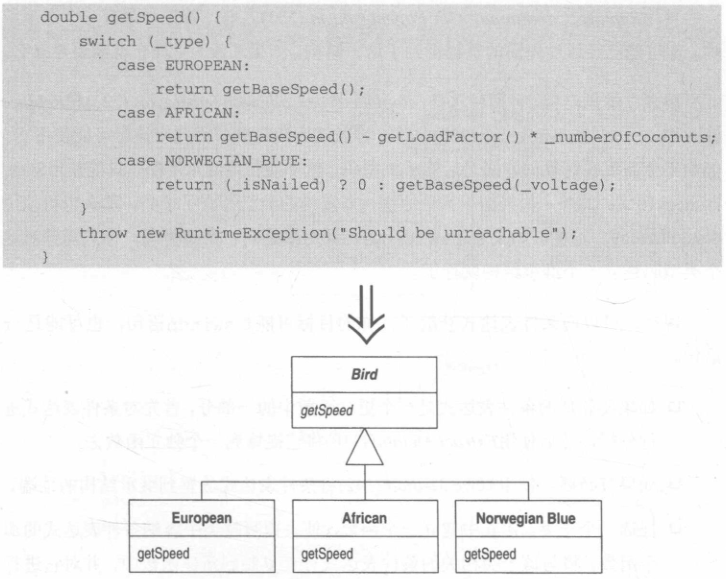
Replace Conditional with Polymorphism 以多态取代条件表达式
你手上有个条件表达式,它根据对象类型的不同而选择不同的行为。
将这个条件表达式的每个分支放进一个子类内的覆写函数中,然后将原始函数声明为抽象函数。
动机
在面向对象术语中,听上去最高贵的词非”多态”莫属。多态最根本的好处就是:如果你需要根据对象的不同类型而采取不同的行为,多态使你不必编写明显的条件表达式。
正因为有了多态,所以你会发现:”类型码的switch语句”以及”基于类型名称的if-then-else语句”在面向对象程序中很少出现。
多态能够给你带来很多好处。如果同一组条件表达式在程序许多地点出现,那么使用多态的收益是最大的。使用条件表达式时,如果你想添加一种新类型,就必须查找并更新所有条件表达式。但如果改用多态,只需建立一个新的子类,并在其中提供适当的函数就行了。类的用户不需要了解这个子类,这就大大降低了系统各部分之间的依赖,使系统升级更加容易。
Introduce Assertion 引入断言
某一段代码需要对程序状态做出某种假设。以断言明确表现这种假设。

动机
常常会有这样一段代码:只有当某个条件为真时,该段代码才能正常运行。例如平方根计算只对正值才能进行,又例如某个对象可能假设其字段至少有一个不等于null。
这样的假设通常并没有在代码中明确表现出来,你必须阅读整个算法才能看出。有时程序员会以注释写出这样的假设。而我要介绍的是一种更好的技术:使用断言明确标明这些假设。
断言是一个条件表达式,应该总是为真。如果它失败,表示程序员犯了错误。因此断言的失败应该导致一个非受控异常(unchecked exception)。断言绝对不能被系统的其他部分使用。实际上,程序最后的成品往往将断言统统删除。因此,标记”某些东西是个断言”是很重要的。
断言可以作为交流与调试的辅助。在交流的角度上,断言可以帮助程序阅读者理解代码所做的假设;在调试的角度上,断言可以在距离bug最近的地方抓住它们。当我编写自我测试代码的时候发现,断言在调试方面的帮助变得不那么重要了,但我仍然非常看重它们在交流方面的价值。
注意,不要滥用断言。请不要使用它来检査”你认为应该为真”的条件,请只使用它来检査”一定必须为真”的条件。滥用断言可能会造成难以维护的重复逻辑。在一段逻辑中加入断言是有好处的,因为它迫使你重新考虑这段代码的约束条件。如果不满足这些约束条件,程序也可以正常运行,断言就不会带给你任何帮助,只会把代码变得混乱,并且有可能妨碍以后的修改。
你应该常常问自己:如果断言所指示的约束条件不能满足,代码是否仍能正常运行?如果可以,就把断言拿掉。
另外,还需要注意断言中的重复代码。它们和其他任何地方的重复代码一样不好闻。你可以大胆使用Extract Method去掉那些重复代码。
简化函数调用
关于缩减参数列的重构手法, Doug Lea对我提出了一个警告:并发编程往往需要使用较长的参数列,因为这样你可以保证传递给函数的参数都是不可被修改的, 例如内置型对象和值对象一定是不可变的。通常,你可以使用不可变对象取代这样的长参数列,但另一方面你也必须对此类重构保持谨慎。
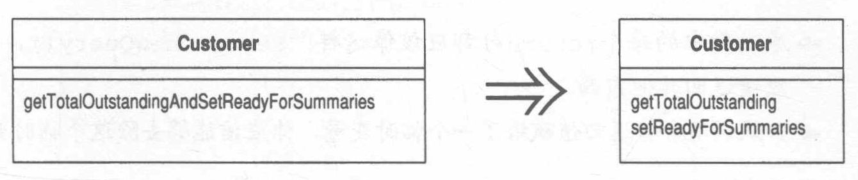
Separate Query from Modifier 将查询函数和修改函数分离
某个函数既返回对象状态值,又修改对象状态。
建立两个不同的函数,其中一个负责查询,另一个负责修改。
动机
如果某个函数只是向你提供一个值,没有任何看得到的副作用,那么这是个很有价值的东西。你可以任意调用这个函数,也可以把调用动作搬到函数的其他地方。
简而言之,需要操心的事情少多了。明确表现出”有副作用”与”无副作用”两种函数之间的差异,是个很好的想法。下面是一条好规则:任何有返回值的函数,都不应该有看得到的副作用。有些程序员甚至将此作为一条必须遵守的规则。就像对待任何东西一样,我并不绝对遵守它,不过我总是尽量遵守,而它也回报我很好的效果。
如果你遇到一个”既有返回值又有副作用”的函数,就应该试着将查询动作从修改动作中分割出来。
并发问题
如果你在一个多线程系统中工作,肯定知道这样一个重要的惯用手法:在同一个动作中完成检查和赋值。这是否和Separate Query from Modifier互相矛盾呢?我曾经和Doug Lea讨论过这个问题,并得出结论:两者并不矛盾,但你需要做一些额外工作。将查询动作和修改动作分开来仍然是很有价值的。但你需要保留第三个函数来同时做这两件事。这个”查询一修改”函数将调用各自独立的查询函数和修改函数,并被声明为synchronized。如果查询函数和修改函数未被声明为synchronized,那么你还应该将它们的可见范围限制在包级别或private级别。这样,你就可以拥有一个安全、同步的操作,它由两个较易理解的函数组成。这两个较低层函数也可以用于其他场合。
Replace Constructor with Factory Method 以工厂函数取代构造函数
你希望在创建对象时不仅仅是做简单的建构动作。
将构造函数替换为工厂函数。

动机
使用Replace Constructor with Factory Method的最显而易见的动机,就是在派生子类的过程中以工厂函数取代类型码。你可能常常需要根据类型码创建相应的对象,现在,创建名单中还得加上子类,那些子类也是根据类型码来创建。然而由于构造函数只能返回单一类型的对象,因此你需要将构造函数替换为工厂函数。此外,如果构造函数的功能不能满足你的需要,也可以使用工厂函数来代替它。工厂函数也是Change Value to Reference的基础。你也可以令你的工厂函数根据参数的个数和类型,选择不同的创建行为。
Replace Error Code with Exception 以异常取代错误码
某个函数返回一个特定的代码,用以表示某种错误情况。
改用异常。

做法
- 决定应该抛出受控(checked)异常还是非受控(unchecked)异常。
- →如果调用者有责任在调用前检查必要状态,就抛出非受控异常。
- →如果想拋出受控异常,你可以新建一个异常类,也可以使用现有的异常类。
- 找到该函数的所有调用者,对它们进行相应调整,让它们使用异常。
- →如果函数抛出非受控异常,那么就调整调用者,使其在调用函数前做适当检查。每次修改后,编译并测试。
- →如果函数拋出受控异常,那么就调整调用者,使其在try区段中调用该函数。
- 修改该函数的签名,令它反映出新用法。
处理概括关系
有一批重构手法专门用来处理类的概括关系(generalization,即继承关系),其中主要是将函数上下移动于继承体系之中。Pull Up Field和Pull Up Method都用于将特性向继承体系的上端移动,Push Down Method和Push Down Field则将特性向继承体系的下端移动。构造函数比较难以向上拉动,因此专门有一个Pull Up Constructor Body处理它。我们不会将构造函数往下推,因为Replace Constructor with Factory Method通常更管用。
Pull Up Method过程中最麻烦的一点就是:被提升的函数可能会引用只出现于子类而不出现于父类的特性。如果被引用的是个函数,你可以将该函数也一同提升到父类,或者在父类中建立一个抽象函数。在此过程中,你可能需要修改某个函数的签名,或建立一个委托函数。
如果两个函数相似但不相同,你或许可以先借助Form Template Method构造出相同的函数,然后再提升它们。
Form Template Method 塑造模板函数
你有一些子类,其中相应的某些函数以相同顺序执行类似的操作,但各个操作的细节上有所不同。
将这些操作分别放进独立函数中,并保持它们都有相同的签名,于是原函数也就变得相同了。然后将原函数上移至父类。
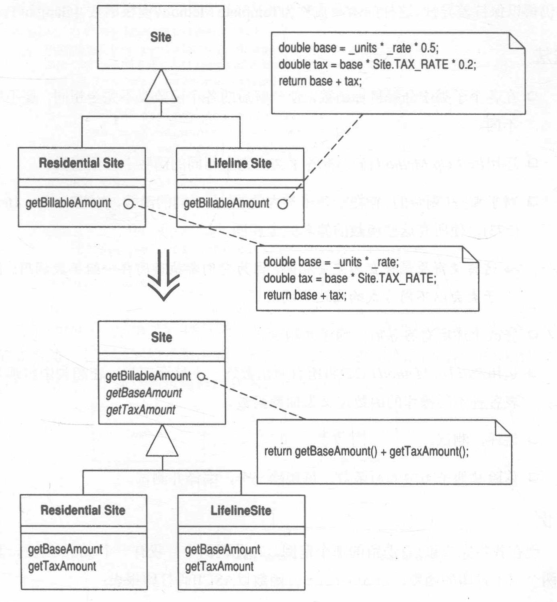
动机
继承是避免重复行为的一个强大工具。无论何时,只要你看见两个子类之中有类似的函数,就可以把它们提升到父类。但是如果这些函数并不完全相同该怎么办?我们仍有必要尽量避免重复,但又必须保持这些函数之间的实质差异。
常见的一种情况是:两个函数以相同顺序执行大致相近的操作,但是各操作不完全相同。这种情况下我们可以将执行操作的序列移至父类,并借助多态保证各操作仍得以保持差异性。这样的函数被称为Template Method(模板函数)
Replace Inheritance with Delegation 以委托取代继承
某个子类只使用父类接口中的一部分,或是根本不需要继承而来的数据。
在子类中新建一个字段用以保存父类;调整子类函数,令它改而委托父类;然后去掉两者之间的继承关系。
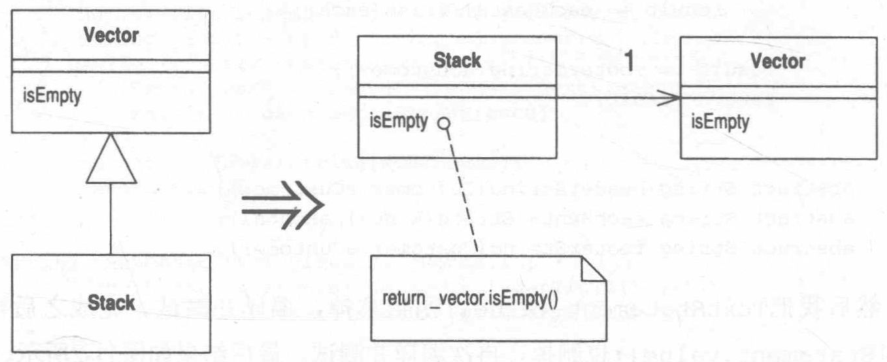
动机
继承是个好东西,但有时候它并不是你要的。你常常会遇到这样的情况:一开始继承了一个类,随后发现父类中的许多操作并不真正适用于子类。这种情况下,你所拥有的接口并未真正反映出子类的功能。或者,你可能发现你从父类中继承了大堆子类并不需要的数据,抑或你可能发现父类中的某些protected函数对子类并没有什么意义。
你可以选择容忍,并接受传统说法:子类可以只使用父类功能的一部分。但这样做的结果是:代码传达的信息与你的意图南辕北辙—这是一种混淆,你应该将它去除。
如果以委托取代继承,你可以更清楚地表明:你只需要受托类的一部分功能。接口中的哪一部分应该被使用,哪一部分应该被忽略,完全由你主导控制。这样做的成本则是需要额外写出委托函数,但这些函数都非常简单,极少可能出错。
Replace Delegation with Inheritance 以继承取代委托
你在两个类之间使用委托关系,并经常为整个接口编写许多极简单的委托函数。
让委托类继承受托类。
动机
本重构与Replace Inheritance with Delegation恰恰相反。如果你发现自己需要使用受托类中的所有函数,并且费了很大力气编写所有极简的委托函数,本重构可以帮助你轻松回头使用继承。
两条告诫需牢记于心。首先,如果你并没有使用受托类的所有函数,那么就不应该使用Replace Delegation With Inheritance,因为子类应该总是遵循父类的接口。如果过多的委托函数让你烦心,你有别的选择:你可以通过Remove Middle Man让客户端自己调用受托函数,也可以使用Extract Superclass将两个类接口相同的部分提炼到父类中,然后让两个类都继承这个新的父类;你还可以用类似的手法使用Extract Interface。
另一种需要当心的情况是:受托对象被不止一个其他对象共享,而且受托对象是可变的。在这种情况下,你就不能将委托关系替换为继承关系,因为这样就无法再共享数据了。数据共享是必须由委托关系承担的一种责任,你无法把它转给继承关系。如果受托对象是不可变的,数据共享就不成问题,因为你大可放心地复制对象,谁都不会知道。
大型重构
要指出继承体系是否承担了两项不同的责任并不困难:如果继承体系中的某一特定层级上的所有类,其子类名称都以相同的形容词开始,那么这个体系很可能就是承担着两项不同的责任。
重构,复用与现实
关于研究,Ralph Johnson给我上了重要的一课:如果有人(文章读者或是演讲会听众)说”我不懂”或者不打算接受它,那就是我们的失败。我们有责任努力发展自己的思想,并将它清楚表达出来。
总结
正如我所说,这是一种可以学习的技术。那么,应该如何学习呢?
- 随时挑一个目标。某个地方的代码开始发臭了,你就应该将问题解决掉。你应该朝目标前进,达成目标后就停止。你之所以重构,不是为了探索真善美(至少不全是),而是为了让你的系统更容易被人理解,为了防止程序变得散乱。
- 没把握就停下来。朝目标前进的过程中,可能会有这样的时候:你无法证明自己所做的一切能够保持程序原本的语义。此时你就应该停下来。如果代码已经改善了一些,就发布你的成果;如果没有,就撤销所有修改。
- 学习原路返回。重构的原则不好学,而且很容易遗失准头。就连我自己,也经常忘记这些原则。我有时会连续做两三项甚至四项重构,而没有每次执行测试用例。当然那是因为我完全相信,即使没有测试的帮助,我也不会出错。于是我就放手干了。然后,”砰”的一声,某个测试失败,我却无法找到究竟哪一次修改造成了这个问题。
- 二重奏。和别人一起重构,可以收到更好的效果。两人结对,对于任何一种软件开发都有很多好处,对于重构也不例外。重构时,小心谨慎、按部就班的态度是有好处的。如果两人结伴,你的搭档能够帮助你一步一步前进,你也能够帮助他。重构时,时刻留意远景目标是有好处的。如果两人结伴,你的搭档可能看到你没看到的东西,能想到你没想到的事情。重构时,明智结束是有好处的。如果你的搭档不知道你在干什么,那就意味你肯定也不知道自己在干什么,此时你就应该结束重构。最重要的是,重构时,拥有绝对自信是绝对有好处的。如果两人结伴,你的搭档能够给你温柔的鼓励,让你不至于灰心丧气。