SOFAMosn 如何提高 GoLang 的转发性能
通过SOFAMosn了解goroutine只能在一定并发量级上降低并发编程的难度(goroutine内存占用2kb+)
高并发的场景还是NIO比较适合
GoLang 的转发性能比起 C++ 肯定是稍有逊色的,为了尽可能的提高 MOSN 的转发性能,我们在线程模型上进行优化,当前 MOSN 支持两种线程模型,用户可根据场景选择开启适用的模型。
模型一
如下图所示,使用 GoLang 默认的 epoll 机制,对每个连接分配独立的读写协程进行阻塞读写操作,proxy 层做转发时,使用常驻 worker 协程池负责处理 Stream Event
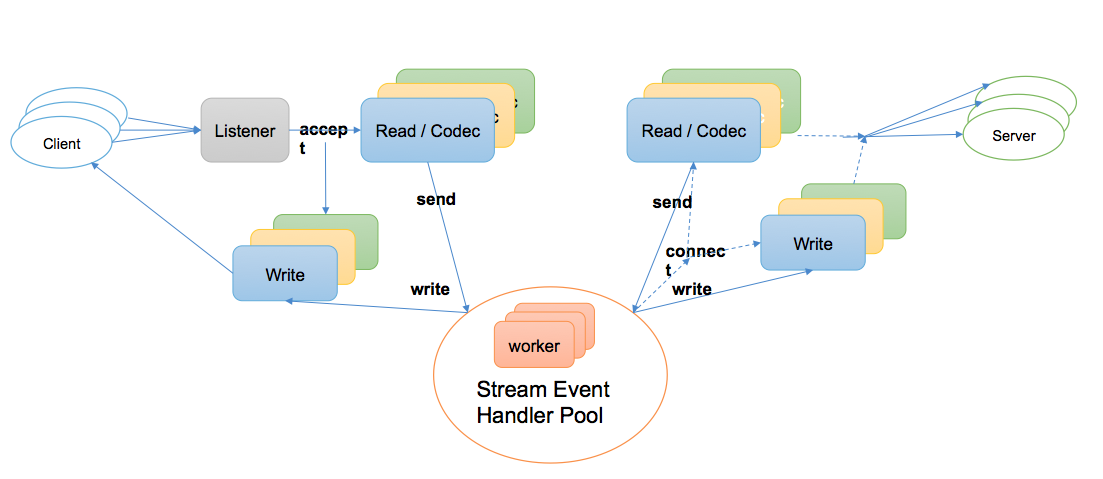
- 此模型在 IO 上使用 GoLang 的调度机制,适用于连接数较少的场景,例如:mosn 作为 sidecar、与 client 同机部署的场景
模型二
如下图所示,基于 Netpoll 重写 epoll 机制,将 IO 和 PROXY 均进行池化,downstream connection 将自身的读写事件注册到 netpoll 的 epoll/kqueue wait 协程,epoll/kqueue wait 协程接受到可读事件,触发回调,从协程池中挑选一个执行读操作。
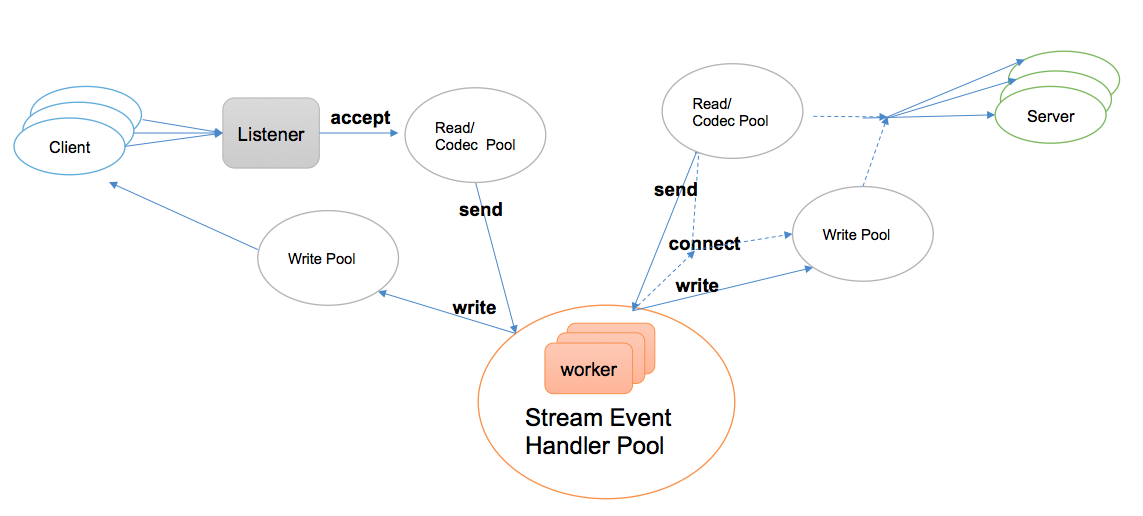
- 使用自定义 Netpoll IO 池化操作带来的好处是:
- 当可读事件触发时,从协程池中获取一个 goroutine 来执行读处理,而不是新分配一个 goroutine,以此来控制高并发下的协程数量
- 当收到链接可读事件时,才真正为其分配 read buffer 以及相应的执行协程。这样 GetBytes() 可以降低因为大量空闲链接场景导致的额外协程和 read buffer 开销
- 此模型适用于连接数较多、可读连接数量受限的情况,例如:mosn 作为 api gateway 的场景
本文整理自SOFAMosn官方文档