[转]腾讯万亿级 Elasticsearch 内存效率提升解密
本文介绍腾讯ES团队如何通过FST OffHeap优化,将堆内存使用率降低80%,单节点存储量从5TB提升至50TB。重点分析FST内存占用问题及零拷贝内存OffHeap的实现方案。
大家可以着重看下 FST 部分
FST 与 磁盘数据量成正比: 10TB 磁盘数据量,其对应的 FST 内存占用量在 10GB ~ 15GB 左右。
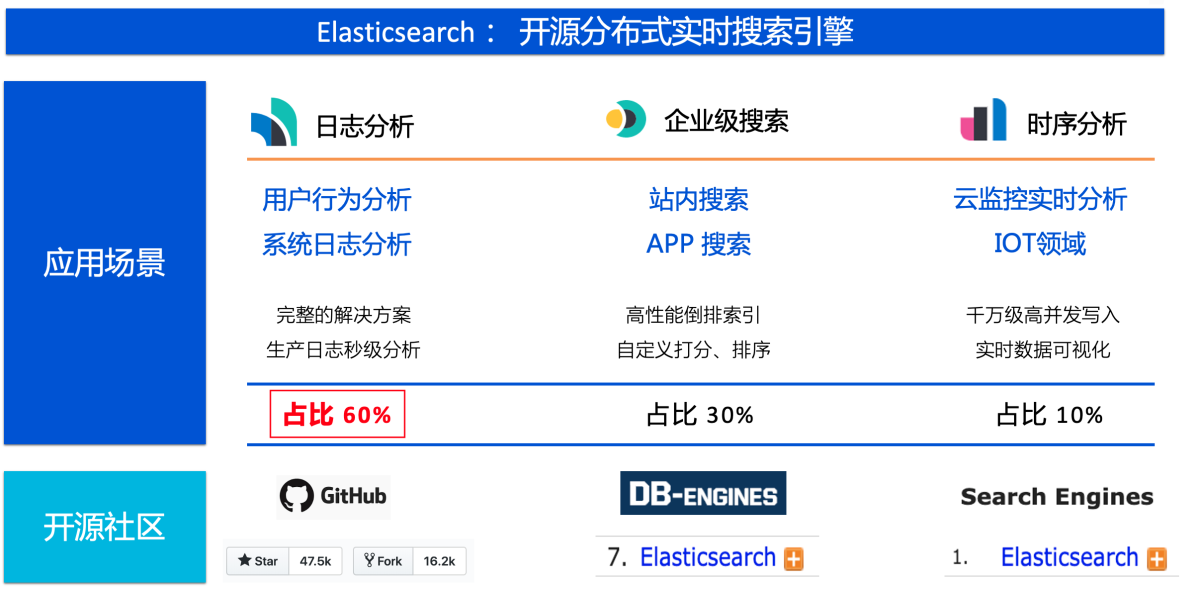
Elasticsearch( ES)是一款功能强大的开源分布式实时搜索引擎,在日志分析(主要应用场景)、企业级搜索、时序分析等领域有广泛应用,几乎是各大公司搜索分析引擎的开源首选方案。
Tencent ES 是内核级深度优化的 ES 分支,持续地进行高可用、高性能、低成本等全方位优化,已支撑的单集群规模达到千级节点、万亿级吞吐。Tencent ES 已在公司内部开源,同时也积极贡献开源社区,截止目前已向社区提交 PR 25+。
腾讯联合 Elastic 官方在腾讯云上提供了内核增强版 ES 云服务,支撑公司内部云、外部云、专有云达 60PB+ 的数据存储,服务 蘑菇街、知乎、B 站、凤凰网等业内头部客户。
本文主要介绍 Tencent ES 的主要优化点之一:零拷贝 内存 Off Heap,提升内存使用效率,降低存储成本。最终达到,在读写性能与源生逻辑一致的前提下,堆内存使用率降低 80%,单节点存储量从 5TB 提升至 50TB 的效果。
问题:日志分析场景数据量大,ES 内存瓶颈导致存储成本较高
上节提到,日志分析是 ES 的主要应用场景(占比60%),而日志数据的特点显著:
- 数据量大,成本是主要诉求:我们大批线上大客户,数据量在几百 TB 甚至 PB 级,单集群占用几百台机器。如此规模的数据量,带来了较高的成本,甚至有些客户吐槽,日志的存储成本已超越产品自身的成本。
- 数据访问冷热特性明显:如下图所示,日志访问近多远少,历史极少访问却占用大量成本。

分析:成本瓶颈在哪里:堆内存使用率过高

我们对线上售卖的集群做硬件成本分析后,发现成本主要在磁盘和内存。
为了降低磁盘成本,我们采取冷热分离、Rollup、备份归档、数据裁剪等多种方式降成本。在冷热分离的集群,我们通过大容量的冷存储机型,来存储历史数据,使得磁盘成本下降 60% 左右。

问题也随之而来:如上图所示,大容量的冷机型,存在磁盘使用率过低的问题( 40 % 以下),原因是堆内存使用率过高了( 70 % 左右),制约磁盘使用率无法提升。(其中单节点磁盘使用率 40%,约 13TB 左右,这已经是 Tencent ES 优化后的效果,源生只能支持到5 TB 左右)
所以,为了提升低成本的冷机型磁盘使用率,同时也为了降低内存成本,我们需要降低 ES 的堆内存使用率。
堆内存使用率为什么会高?
ES 是通过 JAVA 语言编写的,在介绍如何降低堆内存使用率之前,先了解下 JAVA 的堆内存:

- 堆内存就是由 JVM (JAVA虚拟机)管理的内存。建立在堆内存中的对象有生命周期管理机制,由垃圾回收机时自动回收过期对象占用的内存。
- 堆外内存是由用户程序管理的内存,堆外内存中的对象过期时,需要由用户代码显示释放。1.运营侧调整装箱策略能否解决问题?了解了 JAVA 堆内存后,我们看,能否通过调整运营策略来提升堆内存容量呢?
- 堆内存分配大一点行不行?
超过32GB,指针压缩失效,内存浪费, 50GB堆内存性能与31GB接近且垃圾回收压力大,也影响性能 - 多节点部署提高堆内存总量是否可行?
多节点部署,占用机器量更大,用户成本上升
大客户节点数过多(几百个),集群元数据管理瓶颈,可用性下降
反向推动云上用户拆分集群,阻力很大
所以,简单的运营侧策略调整无法解决堆内存使用率过高的问题。那么我们就需要确认 ES 的堆内存是被什么数据占用了,能否优化。
堆内存被什么数据占用了?
我们对线上集群的堆内存分布情况做统计分析后,发现绝大部分堆内存主要被 FST( Finite State Transducer )占用了:
FST 内存占用量占分堆内存总量的 50% ~ 70%
FST 与 磁盘数据量成正比: 10TB 磁盘数据量,其对应的 FST 内存占用量在 10GB ~ 15GB 左右。
因此,我们的目标就是就是通过内核层的优化,降低 FST 的堆内存占用量。
方案:降低 FST 堆内存占用量
什么是 FST ?
在介绍具体的方案前,先来了解下 FST 到底是什么。
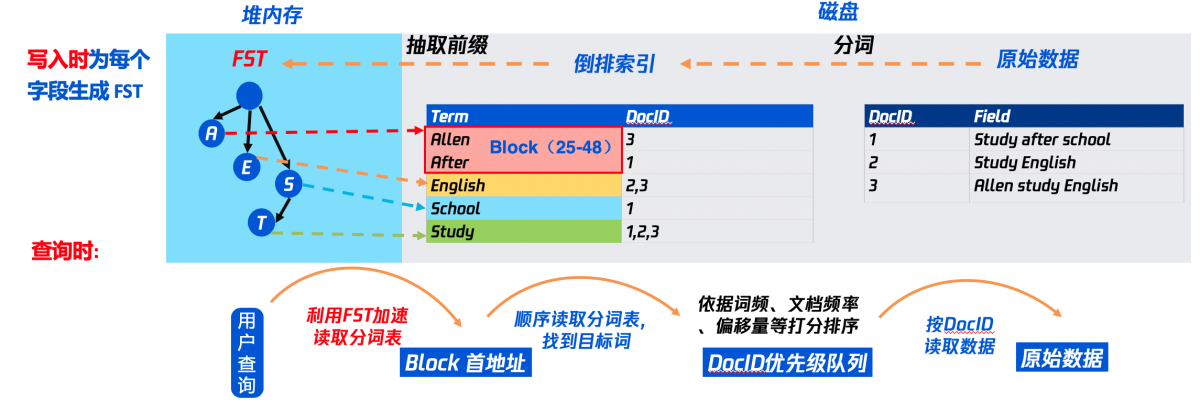
如上图所示,ES 底层存储采用 Lucene(搜索引擎),写入时会根据原始数据的内容,分词,然后生成倒排索引。
查询时,先通过查询倒排索引找到数据地址(DocID)),再读取原始数据(行存数据、列存数据)。
但由于 Lucene 会为原始数据中的每个词都生成倒排索引,数据量较大。所以倒排索引对应的倒排表被存放在磁盘上。这样如果每次查询都直接读取磁盘上的倒排表,再查询目标关键词,会有很多次磁盘 IO,严重影响查询性能。
为了解磁盘 IO 问题,Lucene 引入排索引的二级索引 FST Finite State Transducer 。原理上可以理解为前缀树,加速查询。
其原理如下:
- 将原本的分词表,拆分成多个 Block ,每个 Block 会包含 25 ~ 48 个词(Term)。图中做了简单示意,Allen 和 After组成一个 Block 。
- 将每个 Block 中所有词的公共前缀抽取出来,如 Allen 和 After 的公共前缀是 A 。
- 将各个 Block 的公共前缀,按照类似前缀树的逻辑组合成 FST,其叶子节点携带对应 Block 的首地址 。(实际 FST 结构更为复杂,前缀后缀都有压缩,来降低内存占用量)
- 为了加速查询,FST 永驻堆内内存,无法被 GC 回收。
- 用户查询时,先通过关键词(Term)查询内存中的 FST ,找到该 Term 对应的 Block 首地址。再读磁盘上的分词表,将该 Block 加载到内存,遍历该 Block ,查找到目标 Term 对应的DocID。再按照一定的排序规则,生成DocID的优先级队列,再按该队列的顺序读取磁盘中的原始数据(行存或列存)。
由此可知,FST常驻堆内内存,无法被 GC 回收 , 长期占用 50% ~ 70% 的堆内存 !
解决方案
既然 FST 是常驻堆内内存,导致堆内存使用率过高,那么解决问题的思路有两种:
- 降低 FST 在堆内的内存使用量
- 将 FST 从堆内存(OnHeap,有32GB容量限制)移到堆外内存(OffHeap)。因为堆外内存无容量上限,可通过扩充机器内存来提升容量。 (堆外内存容量限制近似为 物理内存 - JAVA堆内存)
自然也就有了相应方案:
解决方案一:降低 FST 在堆内的内存使用量
在 Tencent ES 成立前期,我们采用过这种方案。具体的做法是,将 FST 对应的 Block 大小,从 25 ~ 48,放大一倍至 49 ~ 96 。这样,在 关键词 Term 数相同的情况下,Block 数量降低了一倍,对应的 FST 内存理论上也会下降一倍。
- 优点:我们实测发现,这种方案下,FST 的堆内存占用量下降了 40% 左右。
- 缺点:
- 由于 Block内的 Term 数变多了,那么每次遍历 Block 查找目标 Term 时,需要从磁盘读取的数据量更大了,因此也带来了明显的查询性能损耗,约 20% 。
- 该方案只是让 FST 占用的内存下降了一半,仍无法控制 FST 占用的内存总量。不同场景下,FST 数据量大小差异也很大,在全文检索的字段较多时,仍然存在 FST 内存过高的问题。
由此我们可以看出,简单的降低 FST 的堆内存使用量,并不是一个普适性的方案,需要更为通用、彻底限制住 FST 总大小的方案。
解决方案二: 将 FST 从堆内存(OnHeap)移到堆外内存(OffHeap)
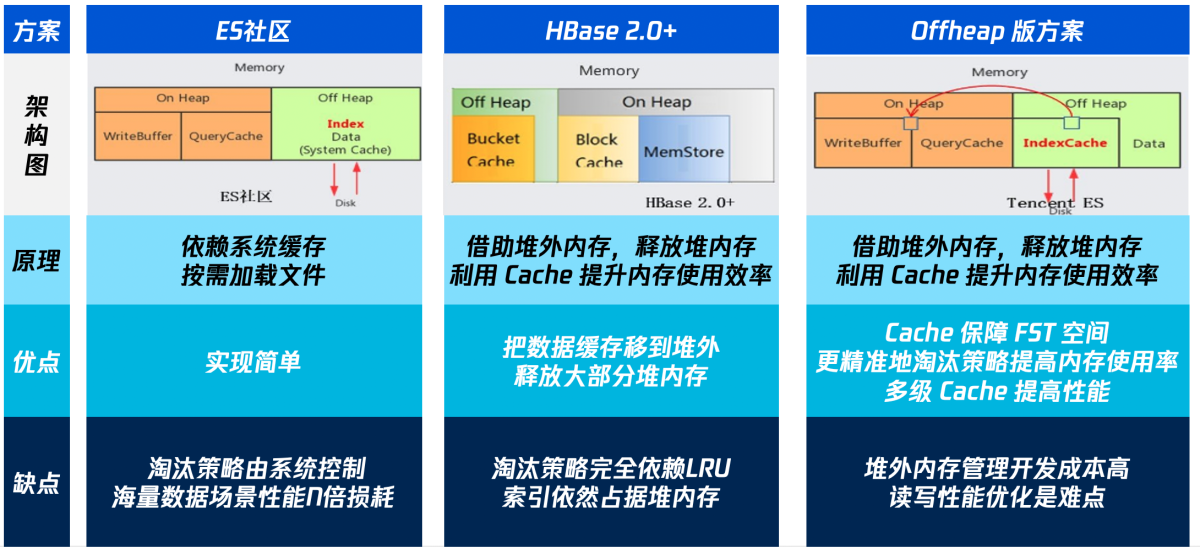
将 FST 从堆内存(OnHeap)移到堆外内存(OffHeap),几乎可以完全释放 FST 在堆内存占据的使用空间,这也是 JAVA 实践方向上一个普遍使用的方案。对于 JAVA 的堆内存不足,将部分内存移到堆外内存(OffHeap)的问题,ES 社区 和 其他 JAVA 系产品都有相应的解决方案。
1.ES 社区方案:
该方案是将 FST 从堆内存中剔除, 直接交由 MMAP 管理。FST 在磁盘上也是有对应的持久化文件的,Lucene 的 .tip 文件,该方案每次查询时直接通过 MMap 读取 .tip 文件,通过文件系统缓存 FST 数据。
优点:这种方实现简单,代码改动量小
缺点:
我们早期也试用过这种方式实现,但是由于 MMAP 属于 page cache 可能被系统回收掉。而且 ES 的大查询也会使用大量的系统缓存导致 FST 占用的内存被冲掉,瞬间产生较多的读盘操作,从而带来性能的 N 倍损耗,容易产生查询毛刺。特别是在 SATA 盘上,严重时查询时延有 10 倍的毛刺。
Lucene 8.x 、ES 7.x 后才支持该功能,存量的 6.x 用户无法使用。
2.HBase 方案
HBase的方案是,在堆外搭建一个Cache,将其一部分堆内存(Bucket Cache,Data Block 缓存)移到堆外,释放堆内内存。
优点:数据缓存放在堆外,释放大量堆内内存
缺点:
淘汰策略完全依赖 LRU 策略
只是把数据缓存放置在堆外,索引的缓存还在堆内
3.Tencent ES 方案
我们的方案总体上接近HBase的方案,相比之下:
优点:
相比于 ES 社区方案,我们堆外的 Cache 保证 FST 的内存空间不受系统影响。
相比于 HBase 方案,我们实现了更精准的数据淘汰策略,提高了内存使用率。也通过多级 Cache 解决性能问题,所以我们敢于把索引放置在堆外。
实现:全链路 0 拷贝 FST OffHeap Cache
下面通过将由浅入深地向大家介绍我们实现 FST OffHeap 的过程,及其中碰见的问题和解决方案。
总体架构
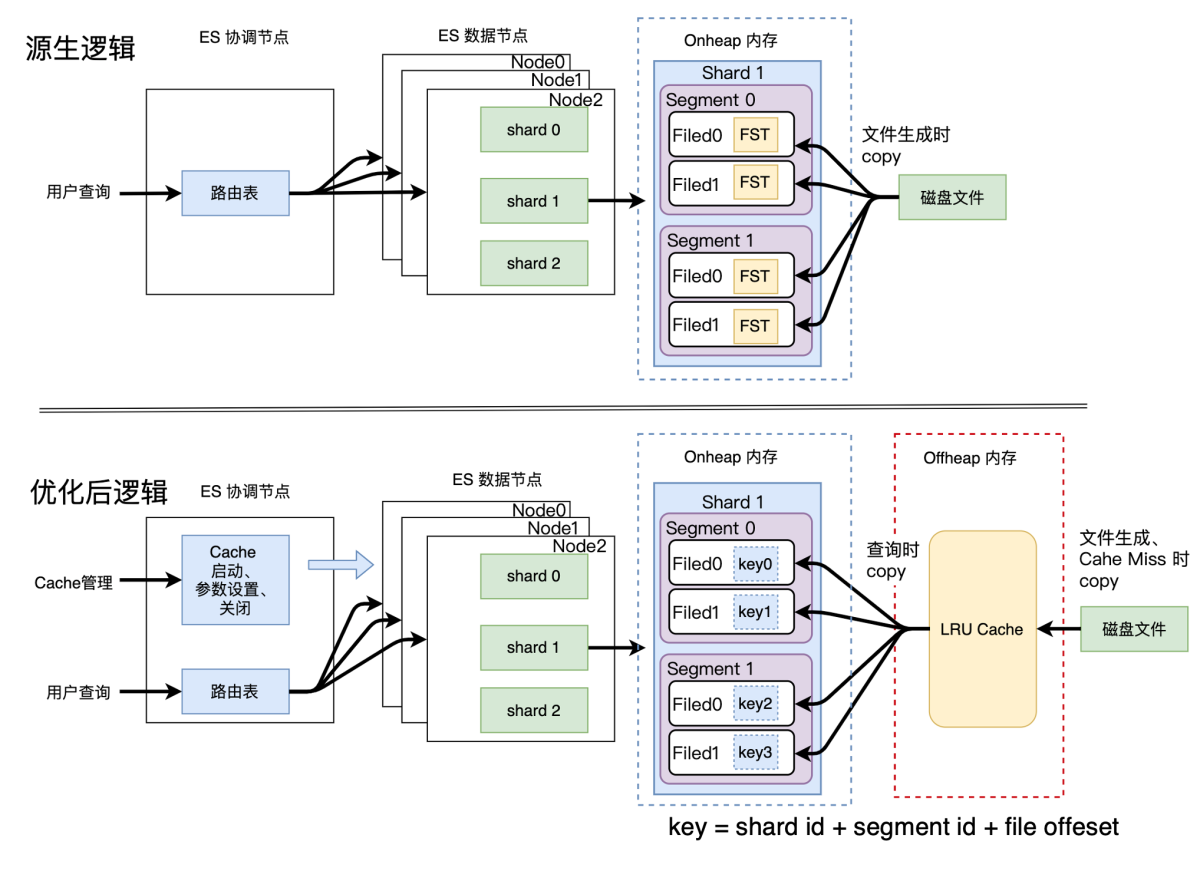
在实现 OffHeap 方案的初期,我们的架构如上图所示。
先来看下源生逻辑是怎样访问 FST 的:
数据写入:ES 的一次 Refresh / Merge 动作,会生成一个新的 Lucene Segment,相应的在磁盘上生成该 Segment 对应的各种数据文件。其中 .tip 文件里面存储的就是该 Segment 各个字段的 FST 信息。在生成 .tip 文件后,Lucene 也会将每个字段( Field )的 FST 数据解析后,拷贝至该 Field 在 OnHeap 内存中的对象里,作为一个成员变量永驻内存,直到该 Segment 被删除 ( Index被删除、Segment Merge 时 )。
数据查询:查询时,直接访问 OnHeap 的 FST 。
再来看下优化后的 Tencent ES 是怎样访问 FST 的:数据写入: 在 OffHeap 内存放置一个 LRU Cache,在生成新的 Segment 时,不再将 .tip 中的 FST 数据拷贝至 OffHeap LRU Cache。将其对应的 Key 放置在 OnHeap 的 Field 中,不再将 FST 拷贝至 OnHeap 的 Field 中。这样就把 FST 从 OnHeap 移到了 OffHeap。
数据查询:查询时,通过 OnHeap Field 中保存的 Key,去 OffHeap LRU Cache 中查询 FST 数据,将其拷贝至 OnHeap后,做查询操作。若 Cache Miss ,则从磁盘的 .tip 文件中的相应位置读取该 Field 对应的 FST 做查询,同时将其放置到 OffHeap LRU Cache 中。
将两种方案做个对比,如下表所示:

那么可以总结出 Tencent ES 优化后的 FST 访问逻辑的优势和劣势:
- 优势:在 OnHeap 我们用 100B 左右的 Key 置换 MB 级别的 FST,大大降低的内存占用量,使得单节点最大支持的磁盘数据量有了 5 倍以上的提升。
- 劣势:FST 在每次查询时都要从 OffHeap LRU Cache 拷贝至 OnHeap,相比于源生逻辑直接访问 OnHeap 的 FST ,读写都多了拷贝的动作,造成高并发读写时有 20%+ 的性能损耗。
所以,我们要对 OffHeap LRU Cache 的读写路径做优化,减少 Copy 次数,提升读写性能。
具体的实现方案是全链路零拷贝 OffHeap FST 访问逻辑。
全链路零拷贝 OffHeap FST 访问逻辑
ES 源生逻辑访问 FST 只支持堆内的操作,怎样做到让它能直接访问堆外的数据呢?
为此,我们做了两方面优化: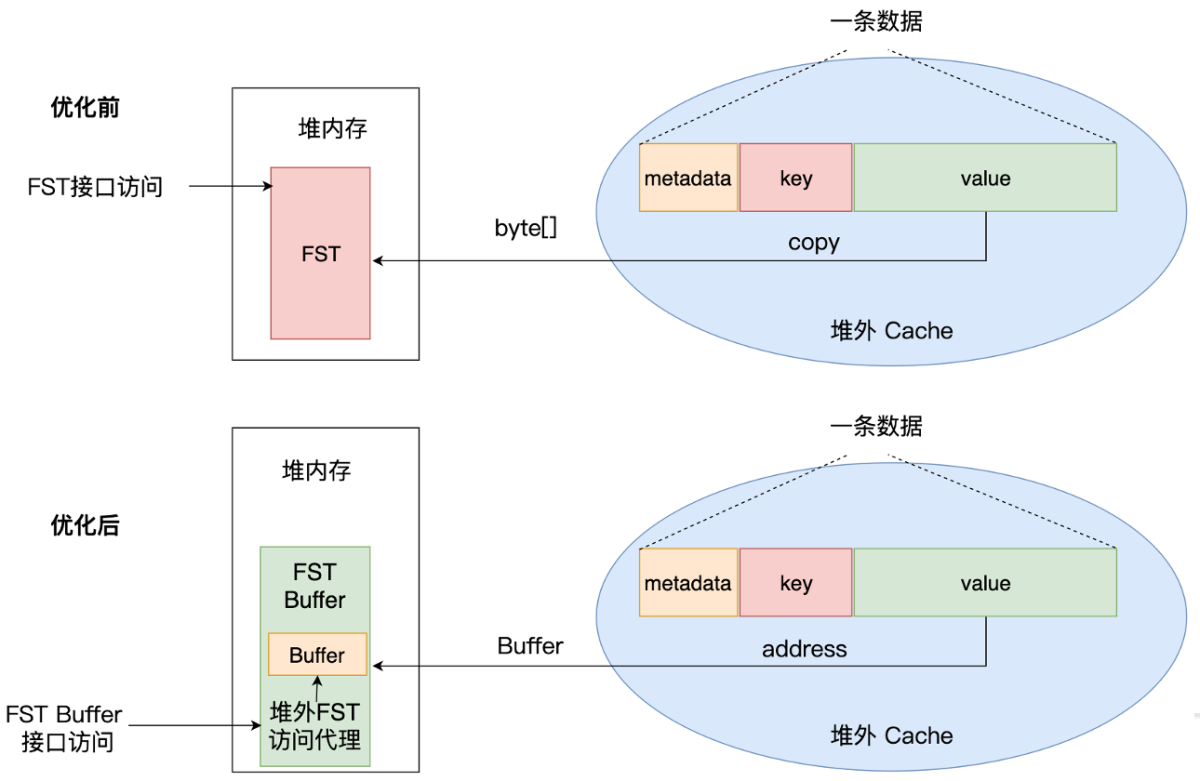
- OffHeap LRU Cache: 改造读数据逻辑,Cache 只返回数据地址,封装为一个 Buffer,堆内只存数据地址,这样就把 FST 的访问从先拷贝至 OnHeap 再访问优化为直读 OffHeap 内存。
- ES:重构 FST 读写逻辑,实现 FST 访问直读 OffHeap 内存:
- FST 抽象为一个 FST Buffer,对外提供 FST 形式的各种访问接口。内部实现按 FST 的数据结构读取 OffHeap Buffer的逻辑,作为访问 OffHeap FST 的代理。
- 将 ES 访问 FST 的所有链路全部改造为 FST Buffer 接口的形式,优化 FST 的读写路径如下所示:
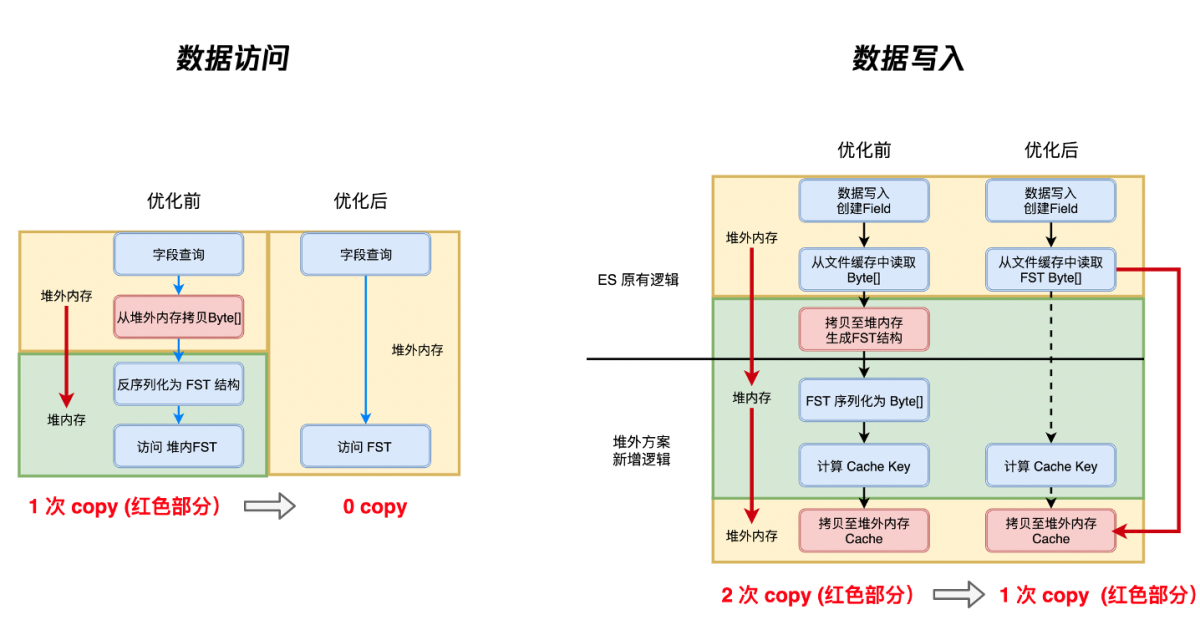
剩余部分略