【Elasticsearch源码】 检索分析
带着疑问学源码,第二篇:Elasticsearch 搜索
代码分析基于:https://github.com/jiankunking/elasticsearch
Elasticsearch 8.0.0-SNAPSHOT
目的
在看源码之前先梳理一下,自己对于检索流程疑惑的点:
- 当索引是按照日期拆分之后,在使用-* 检索,会不会通过索引层面的时间配置直接跳过无关索引?使用*会对性能造成多大的影响?
- 增加shard的副本数,能不能优化检索,比如:让副本数与节点数相同?也就是想知道,正确的副本数应该如何确定?
- 聚合是如何实现的?先在shard层面调用Lucene来聚合,然后汇聚到协调节点再进行全局聚合?类似全局排序:https://jiankunking.com/elasticsearch-scroll-and-search-after.html
完整流程
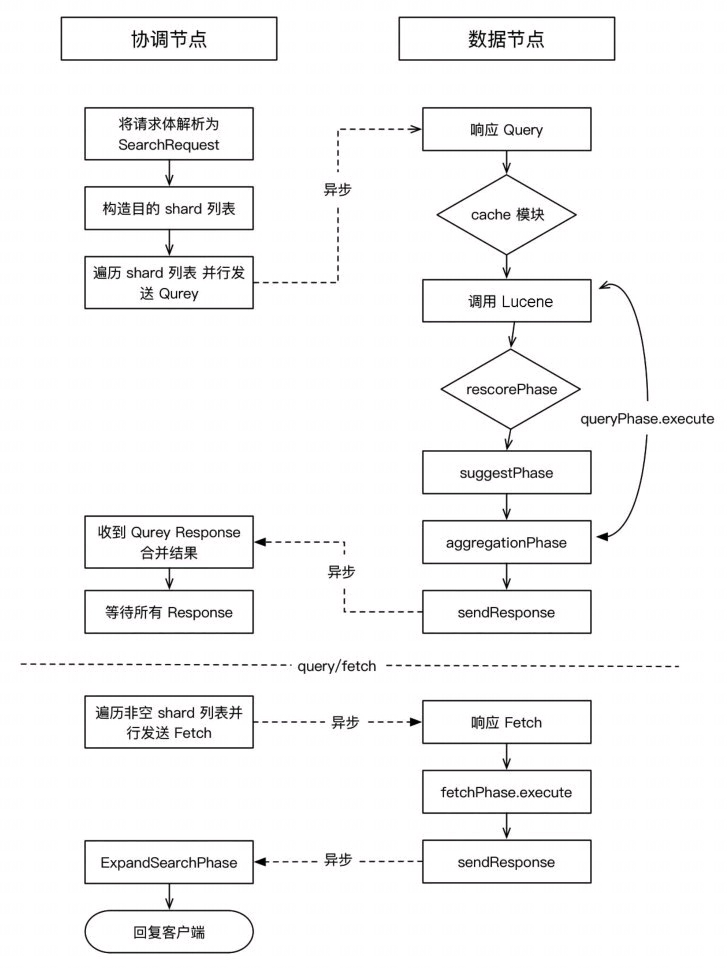
图片截取自:Elasticsearch源码解析与优化实战
源码分析
第二部分是代码分析的过程,不想看的朋友可以跳过直接看第三部分总结。
分析的话,咱们就以_search操作为主线。
在RestSearchAction可以看到:
- 路由注册
- 请求参数转换
真正执行的是TransportSearchAction,类图如下:
![]()
1 | TransportSearchAction doExecute => |
下面先看一下:
1 | private void executeRequest(Task task, SearchRequest searchRequest, |
下面再看一下executeSearch:
1 | private void executeSearch(SearchTask task, SearchTimeProvider timeProvider, SearchRequest searchRequest, |
在看searchAsyncAction之前先看一下AbstractSearchAsyncAction的继承及实现类: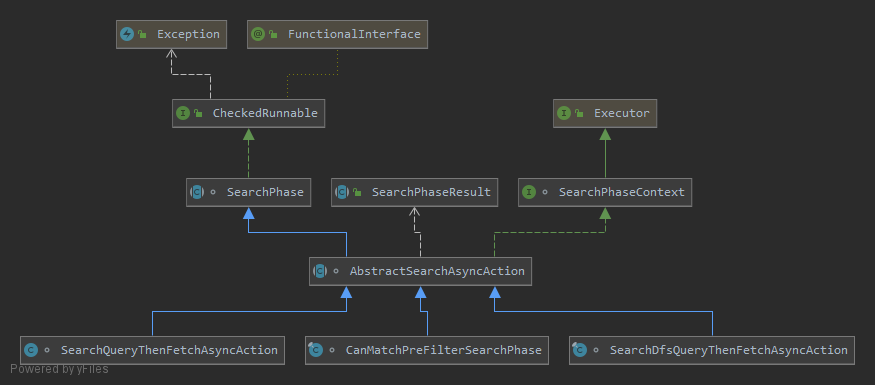
searchAsyncAction主要是生成查询的请求,也就是AbstractSearchAsyncAction的实例:
1 | private AbstractSearchAsyncAction<? extends SearchPhaseResult> searchAsyncAction( |
获取到具体的SearchAsyncAction之后具体的执行是通过run()来调用各个实现类具体的执行了:
1 | /** |
因为默认的搜索类型是QUERY_THEN_FETCH,那么下面看一下SearchQueryThenFetchAsyncAction,在SearchQueryThenFetchAsyncAction中没有重写run(),所以真正执行的还是父类AbstractSearchAsyncAction中的run(),下面看下:
1 | @Override |
通过performPhaseOnShard,来进行具体某个shard的搜索:
1 | protected void performPhaseOnShard(final int shardIndex, final SearchShardIterator shardIt, final SearchShardTarget shard) { |
每个分片在执行完毕Query子任务后,通过节点间通信,回调AbstractSearchAsyncAction类中的onShardResult方法,把查询结果记录在协调节点保存的数组结构results中,并增加计数:
1 | /** |
当返回结果的分片数等于预期的总分片数时,协调节点会进入当前Phase的结束处理,启动下一个阶段Fetch Phase的执行。注意,ES中只需要一个分片执行成功,就会进行后续Phase处理得到部分结果,当然它会在结果中提示用户实际有多少分片执行成功。
onPhaseDone会调用executeNextPhase方法进入下一个阶段,从而开始进入Fetch 阶段。
1 | /** |
下面看一下FetchSearchPhase中的run():
1 | @Override |
从代码在哪个可以看到Fetch后的结果保存到了counter中,而counter是定义在innerRun内:
1 | final CountedCollector<FetchSearchResult> counter = new CountedCollector<>(fetchResults, |
fetchResults用于存储从某个shard收集的结果,每收到一个shard数据就执行一次counter.countDown()。当所有shard收集完成之后,countDown会触发执行finishPhase:
1 | // FetchSearchPhase类中 |
获取查询结果之后,进入ExpandSearchPhase类中的run():
1 | // 主要判断是否启用字段折叠(field collapsing),根据需要实现字段折叠, |
看到这里还是没有发现针对-*有什么特殊的优化,还是会根据检索条件遍历符合条件的所有索引及其shard。那下面看那一下具体获取数据的时候有没有什么特殊处理,也就是data node 在Query、Fetch阶段有没有什么特殊的优化?
下面看一下SearchTransportService下的sendExecuteQuery
1 | public void sendExecuteQuery(Transport.Connection connection, final ShardSearchRequest request, SearchTask task, |
通过请求路径QUERY_ACTION_NAME可以在SearchTransportService中找到对应的处理函数searchService.executeQueryPhase:
1 | transportService.registerRequestHandler(QUERY_ACTION_NAME, ThreadPool.Names.SAME, ShardSearchRequest::new, |
下面具体看一下执行:
1 | public void executeQueryPhase(ShardSearchRequest request, boolean keepStatesInContext, |
先略过cache部分,重点看一下QueryPhase类中的execute:
queryPhase.execute(SearchContext searchContext)是核心查询,其中调用Lucene实现检索,同时实现聚合。
=> 先在shard层面调用Lucene来聚合,然后汇聚到协调节点再进行全局聚合,类似全局排序:https://jiankunking.com/elasticsearch-scroll-and-search-after.html
1 | public void execute(SearchContext searchContext) throws QueryPhaseExecutionException { |
searchWithCollectorManager与searchWithCollector都是调用ContextIndexSearcher类中的search调用Lucene接口进行查询。
到目前为止都没发现,针对-*查询都没有任何优化。
唯一有希望进行优化的地方就是通过lucene检索shard的时候,会进行优化,事实上会进行一定的优化,比如借助Lucene的PointValues来优化IntField,LongField,FloatField,DoubleField。
但不管怎么优化,对于搜索而言,还是能缩小范围就缩小,不管怎么优化,都不是一点成本没有的。
总结
问题1
elasticsearch针对-*检索不会在索引、shard层面优化,但会在检索具体shard的时候,通过lucene的特性来快速调过一些不符合条件的shard。但这些特性不能保证一定会快速检索某些shard,因为很有可能你的检索条件位于shard的上下限之间。
所以说,还是在数据入es时,拆分到合适的索引,效果最好。
问题2
搜索从shard主副本列表中挑选shard的是随机的=>副本数跟节点数相同并不能让一次搜索都请求本机的shard。
但增加副本数量,的确会增加请求本机shard的概率,也就是说副本增加的确会加速检索,但副本增加对于内存消耗、写入数据会有负向影响。所以具体副本数的选择,有可能需要在实际场景中压测。
- 7.X及之后默认情况下preference是Adaptive replica selection,=>
- 副本数跟节点数相同并不能让一次搜索都请求本机的shard,=>
- 如果想强制从本机中shard中获取数据,可以指定preference=_local,=>
- ARS原理讲解
- https://www.elastic.co/cn/blog/improving-response-latency-in-elasticsearch-with-adaptive-replica-selection
- ARS内部会自动均衡,不会只请求某一个shard(如果不自动均衡会导致一些节点一直没有请求,从而导致集群加节点对于查询负载没有影响;其实,咱们反过来想一下,也应该知道es内部肯定会做这个事情,要不然是不是太傻了😂😂😂😂😂😂 )
举个简单的例子:
如果有个重要业务场景,数据不大也就10G左右,机器配置:32Core 64G,这时候增加副本对于检索速度就有帮助。如果是日志写入的场景,瓶颈更有更可能数写入的速度,如果这时候增加副本数,就会导致写入延迟大幅提高。
=>
那么正确的副本数量是多少?
如果您的集群总共有 num_nodes 个节点、num_primaries 个主分片,并且您希望能够一次最多处理 max_failures 个节点故障,那么适合您的副本数量是 max(max_failures, ceil(num_nodes / num_primaries) - 1).
比如现在有9个节点,索引A有3个shard,也就是num_primaries=3,最大容忍2个节点同时故障,那么副本数应该是:
1 | max(max_failures, ceil(num_nodes/num_primaries) - 1) |
ceil向上取整,比如ceil(2.3) =>3
这里副本数的选择更像是一种权衡,具体场景还是要根据业务场景、机器资源能权衡选择。
问题3
与猜想的一样
先在shard层面调用Lucene来聚合,然后汇聚到协调节点再进行全局聚合,类似全局排序:https://jiankunking.com/elasticsearch-scroll-and-search-after.html