Java 伪共享
伪共享(False Sharing)是多处理器系统中的性能杀手,当多个线程修改同一缓存行中的不同变量时,会导致缓存行频繁失效,严重影响性能。本文详解伪共享的原理、影响及解决方案。
伪共享
先看一下wiki中对于伪共享的解释:
In computer science, false sharing is a performance-degrading usage pattern that can arise in systems with distributed, coherent caches at the size of the smallest resource block managed by the caching mechanism. When a system participant attempts to periodically access data that will never be altered by another party, but those data share a cache block with data that are altered, the caching protocol may force the first participant to reload the whole unit despite a lack of logical necessity. The caching system is unaware of activity within this block and forces the first participant to bear the caching system overhead required by true shared access of a resource.
By far the most common usage of this term is in modern multiprocessor CPU caches, where memory is cached in lines of some small power of two word size (e.g., 64 aligned, contiguous bytes). If two processors operate on independent data in the same memory address region storable in a single line, the cache coherency mechanisms in the system may force the whole line across the bus or interconnect with every data write, forcing memory stalls in addition to wasting system bandwidth. False sharing is an inherent artifact of automatically synchronized cache protocols and can also exist in environments such as distributed file systems or databases, but current prevalence is limited to RAM caches.
在计算机科学中,错误共享是会导致性能下降,它可能出现在使用由缓存机制管理的分布式、一致的缓存的系统中,系统中最小粒度是一个缓存块。当系统参与者试图周期性地访问部分数据,这部分数据只会被自己修改,但是这些数据可能与别的数据存储在同一个缓存块,当别的数据被修改的时候,缓存协议可能会强制第一个参与者重新加载整个单元,尽管缺乏逻辑上的必要性。
到目前为止,该术语最常见的用法是在现代多处理器CPU高速缓存中,在该高速缓存中,内存以两个字长(例如64个对齐的连续字节)的行高速缓存。如果两个处理器在同一内存地址区域中的独立数据上操作,而该内存地址区域可存储在一行中,则系统中的缓存一致性机制可能会强制每次数据写入都通过总线刷新整个行,除了浪费系统带宽外,还会导致内存暂停。错误共享是自动同步的缓存协议的固有产物,也可以存在于诸如分布式文件系统或数据库之类的环境中,但是当前的流行仅限于RAM缓存。
多份数据共同存储于一个缓存行(缓存的最小单位),当其中一份数据发生更改的时候,内存系统强制更新整个缓存行。这么做的目的就是避免内存中同一地址的数据在不同缓存中的副本出现不一致。
更多信息可以参见:《垃圾回收算法手册:自动内存管理的艺术 笔记》中的 【高速缓存一致性】
Java中的伪共享
Hotspot为了优化内存占用会将字段自由地重新安排,以满足对齐要求,从而使间隙更小。也正是这种优化,导致出现了在同一缓存行上,有可能有多个数据,从而导致伪共享。
伪共享说的是缓存,而缓存的目的就是加快读取速度,也就意味了被缓存的数据不应该频繁更改。
换个角度考虑伪共享就是硬件层面高速缓存的失效,导致性能的下降。
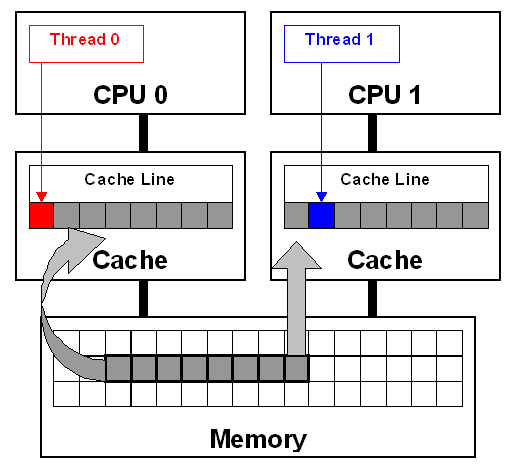
以下图为例,当不同处理器上的线程修改驻留在同一高速缓存行上的变量时,会发生错误共享。这将使高速缓存行失效,并强制进行内存更新以保持高速缓存的一致性。
Java中的解决方案
使用@Contended注解,使用该注解,我们可以将热的频繁写入的共享字段与其他主要为只读或冷的字段隔离开来。简单的规则是读共享很便宜,写共享很昂贵。我们还可以将经常由同一线程同时写入的字段打包。
更一般地说,我们试图影响相关字段的位置,以最小化一致性缺失。在一个简单的单线程环境中,在时间上紧密地一起访问的字段应该放在相邻的空间,以促进缓存局部性。也就是说,时间局部性应该制约空间局部性。在时间上一起访问的字段应该在空间上相邻。也就是说,当线程同时访问我们的字段时,我们必须小心避免错误共享和一致性通信的过度失效。因此,我们试图集群或以其他方式隔离在同一线程上大约在同一时间写入相同缓存行的字段。请注意,这里有一个竞争的因素:如果我们过于努力地将单线程容量丢失最小化,那么我们最终可能会在并行环境中运行过多的一致性丢失。在本机C/C++代码中,程序员通常使用通知并发的结构布局。@Contended应该在Java中提供相同的功能,尽管在本地代码中,字段与偏移量的绑定在编译时发生,而在Java的加载时发生。值得指出的是,在一般情况下,对于单线程和多线程环境都没有单一的最佳布局。而理想的布局问题本身就是NP-hard。
理想情况下,JVM将使用硬件监控设施来检测共享行为并动态更改布局。这有点困难,因为我们还没有合适的方式来向JVM提供高效和方便的信息。提示:我们需要取消OS和hypervisor的中间层。另一个挑战是,在不安全的设施中使用原始字段偏移,因此我们需要解决这个问题,可能需要额外的间接级别。
最后,我也希望能够将最终字段打包在一起,因为这些字段是只读的。
小结
伪共享本质是就是在缓存中最小的颗粒度仍然大于某个对象的属性的内存占用,导致该缓存最小单元中存储了多个不相关的对象属性,多个不相关属性的(各自)修改会导致缓存状态的频繁变化。由于硬件一般支持高速缓存一致性协议,缓存状态的变化会导致多核CPU频繁更新缓存状态,导致性能下降。
图片来自:
https://software.intel.com/en-us/articles/avoiding-and-identifying-false-sharing-among-threads
参考资料:
https://en.wikipedia.org/wiki/False_sharing
http://mail.openjdk.java.net/pipermail/hotspot-dev/2012-November/007309.html
https://blogs.oracle.com/dave/java-contended-annotation-to-help-reduce-false-sharing
拓展阅读:
https://software.intel.com/en-us/articles/avoiding-and-identifying-false-sharing-among-threads
https://software.intel.com/en-us/articles/intel-guide-for-developing-multithreaded-applications