Kubernetes权威指南:从Docker到Kubernetes实践全接触 笔记
Kubernetes权威指南:从Docker到Kubernetes实践全接触(第2版)
作者: 龚正 吴治辉 王伟 崔秀龙 闫健勇 崔晓宁 刘晓红
Kubernetes 入门
Kubernetes 是什么
在Kubernetes中, Service(服务)是分布式集群架构的核心,一个Service对象拥有如下关键特征。
- 拥有一个唯一指定的名字(比如MySQL-server)
- 拥有一个虚拟IP(Cluster、 Service IP或VIP)和端口号。
- 能够提供某种远程服务能力。
- 被映射到了提供这种服务能力的一组容器应用上
Service的服务进程目前都基于Socket通信方式对外提供服务,比如Redis、Memcache、MySQL、Web Server,或者是实现了某个具体业务的一个特定的TCP Server进程。虽然一个Service通常由多个相关的服务进程来提供服务,每个服务进程都有一个独立的 Endpoint(IP+Port)访问点,但Kubernetes能够让我们通过Service(虚拟Cluster IP+Service Port)连接到指定的Service上。有了 Kubernetes内建的透明负载均衡和故障恢复机制,不管后端有多少服务进程,也不管某个服务进程是否会由于发生故障而重新部署到其他机器,都不会影响到我们对服务的正常调用。更重要的是这个Service本身一旦创建就不再变化,这意味着,在Kubernetes集群中,我们再也不用为了服务的IP地址变来变去的问题而头疼了
在通常情况下,Cluster IP是在Service创建后由Kubernetes系统自动分配的,其他Pod无法预先知道某个 Service的Cluster IP地址,因此需要一个服务发现机制来找到这个服务。为此,最初的时候, Kubernetes巧妙地使用了 Linux环境变量(Environment Variable)来解决这个问题,后面会详细说明其机制。现在我们只需知道,根据 Service的唯一名字,容器可以从环境变量中获取到Service对应的Cluster IP地址和端口,从而发起TCP/IP连接请求了。
Kubernetes 基本概念与术语
Master
Kubernetes里的Master指的是集群控制节点,每个Kubernetes集群里需要有一个Master节点来负责整个集群的管理和控制,基本上Kubernetes所有的控制命令都是发给它,它来负责具体的执行过程,我们后面所有执行的命令基本都是在Master节点上运行的。Master节点通常会占据一个独立的X86服务器(或者一个虚拟机),一个主要的原因是它太重要了,它是整个集群的“首脑”,如果它宕机或者不可用,那么我们所有的控制命令都将失效。
Master节点上运行着以下一组关键进程。
- Kubernetes API Server(kube-apipserver),提供了HTTP Rest接口的关键服务进程,是Kubernetes里所有资源的增、删、改、查等操作的唯一入口,也是集群控制的入口进程。
- Kubernetes Controller Manager(kube-controller-manager), Kubernetes里所有资源对象的自动化控制中心,可以理解为资源对象的“大总管”。
- Kubernetes Scheduler(kube-scheduler),负责资源调度(Pod调度)的进程,相当于公交公司的“调度室”。
其实Master节点上往往还启动了一个etcd Server进程,因为Kubernetes里的所有资源对象的数据全部是保存在etcd中的。
Node
除了Master, Kubernetes集群中的其他机器被称为Node节点,在较早的版本中也被称为Minion。与Master一样,Node节点可以是一台物理主机,也可以是一台虚拟机。Node节点才是Kubernetes集群中的工作负载节点,每个Node都会被Master分配一些工作负载(Docker容器),当某个Node宕机时,其上的工作负载会被Master自动转移到其他节点上去。
每个Node节点上都运行着以下一组关键进程。
- kubelet:负责Pod对应的容器的创建、启停等任务,同时与Master节点密切协作,实现集群管理的基本功能。
- kube-proxy:实现Kubernetes service的通信与负载均衡机制的重要组件。
- Docker Engine(docker): Docker引擎,负责本机的容器创建和管理工作。
Node节点可以在运行期间动态增加到Kubernetes集群中,前提是这个节点上已经正确安装、配置和启动了上述关键进程,在默认情况下kubelet会向Master注册自己,这也是Kubernetes推荐的Node管理方式。一旦Node被纳入集群管理范围,kubelet进程就会定时向 Master节点汇报自身的情报,例如操作系统、Docker版本、机器的CPU和内存情况,以及之前有哪些Pod在运行等,这样 Master可以获知每个Node的资源使用情况,并实现高效均衡的资源调度策略。而某个Node超过指定时间不上报信息时,会被 Master判定为“失联”,Noe的状态被标记为不可用(Not Ready),随后 Master会触发“工作负载大转移”的自动流程。
Pod
Pod是Kubernetes的最重要也最基本的概念,如图1.6所示是Pod的组成示意图,我们看到每个Pod都有一个特殊的被称为“根容器”的Pause容器。Pause容器对应的镜像属于Kubernetes平台的一部分,除了Pause容器,每个Pod还包含一个或多个紧密相关的用户业务容器。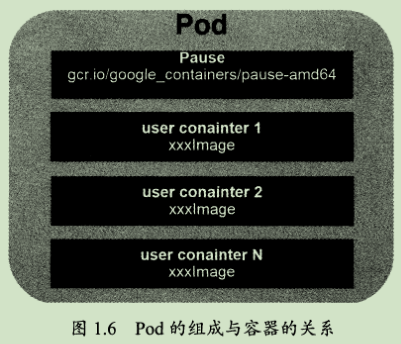
为什么Kubernetes会设计出一个全新的Pod的概念并且Pod有这样特殊的组成结构?
原因之一:在一组容器作为一个单元的情况下,我们难以对“整体”简单地进行判断及有效地进行行动。比如,一个容器死亡了,此时算是整体死亡么?是N/M的死亡率么?引入业务无关并且不易死亡的Pause容器作为Pod的根容器,以它的状态代表整个容器组的状态,就简单、巧妙地解决了这个难题。
原因之二:Pod里的多个业务容器共享Pause容器的IP,共享Pause容器挂接的Volume,这样既简化了密切关联的业务容器之间的通信问题,也很好地解决了它们之间的文件共享问题。
Kubernetes为每个Pod都分配了唯一的IP地址,称之为Pod IP,一个Pod里的多个容器共享Pod IP地址。Kubernetes要求底层网络支持集群内任意两个Pod之间的TCP/IP直接通信,这通常采用虚拟二层网络技术来实现,例如Flannel、Openvswitch等,因此我们需要牢记一点:在Kubernetes里,一个Pod里的容器与另外主机上的Pod容器能够直接通信。
Pod其实有两种类型:普通的Pod及静态Pod(static Pod),后者比较特殊,它并不存放在Kubernetes的etcd存储里,而是存放在某个具体的Node上的一个具体文件中,并且只在此Node上启动运行。而普通的Pod一旦被创建,就会被放入到etcd中存储,随后会被Kubernetes master调度到某个具体的Node上并进行绑定(Binding),随后该Pod被对应的Node上的kubelet进程实例化成一组相关的 Docker容器并启动起来。在默认情况下,当Pod里的某个容器停止时Kubernetes会自动检测到这个问题并且重新启动这个Pod(重启Pod里的所有容器),如果Pod所在的Node宕机,则会将这个Node上的所有Pod重新调度到其他节点上。
每个Pod都可以对其能使用的服务器上的计算资源设置限额,当前可以设置限额的计算资源有CPU与 Memory两种,其中CPU的资源单位为CPU(Core)的数量,是一个绝对值而非相对值。
一个CPU的配额对于绝大多数容器来说是相当大的一个资源配额了,所以,在Kubernetes里,通常以千分之一的CPU配额为最小单位,用m来表示。通常一个容器的CPU配额被定义为100~300m,即占用0.1~0.3个CPU。由于CPU配额是一个绝对值,所以无论在拥有一个Core的机器上,还是在拥有48个Core的机器上,100m这个配额所代表的CPU的使用量都是样的。与CPU配额类似,Memory配额也是一个绝对值,它的单位是内存字节数。
在Kubernetes里,一个计算资源进行配额限定需要设定以下两个参数:
- Requests:该资源的最小申请量,系统必须满足要求。
- Limits:该资源最大允许使用的量,不能被突破,当容器试图使用超过这个量的资源时可能会被Kubernetes kill并重启。
通常我们会把Request设置为一个比较小的数值,符合容器平时的工作负载情况下的资源需求,而把 Limit设置为峰值负载情况下资源占用的最大量。
Label(标签)
Label是Kubernetes系统中另外一个核心概念。一个Label是一个key=value的键值对,其中key与 value由用户自己指定。 Label可以附加到各种资源对象上,例如Node、Pod、Service、RC等,一个资源对象可以定义任意数量的Label,同一个Label也可以被添加到任意数量的资源对象上去,Label通常在资源对象定义时确定,也可以在对象创建后动态添加或者删除。
我们可以通过给指定的资源对象捆绑一个或多个不同的Label来实现多维度的资源分组管理功能,以便于灵活、方便地进行资源分配、调度、配置、部署等管理工作。例如:部署不同版本的应用到不同的环境中;或者监控和分析应用(日志记录、监控、告警)等。一些常用的Label示例如下。
- 版本标签:”release”:”stable”,”release”:”canary
- 环境标签:”environment”:”dev”,”environment”:”qa”,”environment”:”production”
- 架构标签:”tier”:”frontend”,”tier”:”backend”,”tier”:”middleware”
- 质量管控标签:”rack”:”daily”,”rack”:”week”
Label相当于我们熟悉的“标签”,给某个资源对象定义一个Label,就相当于给它打了一个标签,随后可以通过Label Selector(标签选择器)查询和筛选拥有某些 Label的资源对象,Kubernetes通过这种方式实现了类似SQL的简单又通用的对象查询机制Label Selector可以被类比为SQL语句中的where查询条件,例如,name=redis-slave这个Label selector作用于Pod时,可以被类比为’select* from pod where pods name= redis-slave’这样的语句。当前有两种Label Selector的表达式:基于等式的(Equality-based)和基于集合的(Set-based),前者采用“等式类”的表达式匹配标签,下面是一些具体的例子。
- name=redis-slave:匹配所有具有标签name=redis-slave的资源对象。
- env!= production:匹配所有不具有标签env= production的资源对象,比如env=test就是满足此条件的标签之一。
而后者则使用集合操作的表达式匹配标签,下面是一些具体的例子。
- name in(redis-master, redis-save):匹配所有具有标签name=redis-master或者name=redis-slave的资源对象。
- name not in(php-frontend):匹配所有不具有标签name=php-frontend的资源对象。
可以通过多个Label Selector表达式的组合实现复杂的条件选择,多个表达式之间用”,”进行分隔即可,几个条件之间是“AND”的关系,即同时满足多个条件,比如下面的例子:
- name=redis-slave, env!=production
- name not in (php-frontend), env!=production
Label Selector在Kubernetes中的重要使用场景有以下几处。
- kube-controller进程通过资源对象RC上定义的Label Selector来筛选要监控的Pod副本的数量,从而实现Pod副本的数量始终符合预期设定的全自动控制流程。
- kube-proxy进程通过Service的Label selector来选择对应的Pod,自动建立起每个Service到对应Pod的请求转发路由表,从而实现 Service的智能负载均衡机制。
- 通过对某些Node定义特定的Label,并且在Pod定义文件中使用NodeSelector这种标签调度策略,kube-scheduler进程可以实现Pod“定向调度”的特性。
Replication Controller (RC)
RC是Kubernetes系统中的核心概念之一,简单来说,它其实是定义了一个期望的场景,即声明某种Pod的副本数量在任意时刻都符合某个预期值,所以RC的定义包括如下几个部分。
- Pod期待的副本数(replicas)。
- 用于筛选目标Pod的Label Selector
- 当Pod的副本数量小于预期数量的时候,用于创建新Pod的Pod模板(template)。
当我们定义了一个RC并提交到Kubernetes集群中以后, Master节点上的Controller Manager组件就得到通知,定期巡检系统中当前存活的目标Pod,并确保目标Pod实例的数量刚好等于此RC的期望值,如果有过多的Pod副本在运行,系统就会停掉一些Pod,否则系统就会再自动创建一些Pod。可以说,通过RC,Kubernetes实现了用户应用集群的高可用性,并且大大减少了系统管理员在传统T环境中需要完成的许多手工运维工作(如主机监控脚本、应用监控脚本、故障恢复脚本等)。
Replica Set与Deployment这两个重要资源对象逐步替换了之前的RC的作用,是Kubernetes 1.3里Pod自动扩容(伸缩)这个告警功能实现的基础,也将继续在 Kubernetes未来的版本中发挥重要的作用。
最后我们总结一下关于RC(Replica Set)的一些特性与作用。
- 在大多数情况下,我们通过定义一个RC实现Pod的创建过程及副本数量的自动控制。
- RC里包括完整的Pod定义模板。
- RC通过Label Selector机制实现对Pod副本的自动控制。
- 通过改变RC里的Pod副本数量,可以实现Pod的扩容或缩容功能。
- 通过改变RC里Pod模板中的镜像版本,可以实现Pod的滚动升级功能。
Deployment
Deployment是Kubernetes12引入的新概念,引入的目的是为了更好地解决Pod的编排问题。为此, Deployment在内部使用了 Replica Set来实现目的,无论从Deployment的作用与目的、它的YAM定义,还是从它的具体命令行操作来看,我们都可以把它看作RC的一次升级两者的相似度超过90%。
Deployment相对于RC的一个最大升级是我们可以随时知道当前Pod“部署”的进度。实际上由于一个Pod的创建、调度、绑定节点及在目标Node上启动对应的容器这一完整过程需要一定的时间,所以我们期待系统启动N个Pod副本的目标状态,实际上是一个连续变化的“部署过程”导致的最终状态。
Deployment的典型使用场景有以下几个。
- 创建一个Deployment对象来生成对应的Replica Set并完成Pod副本的创建过程。
- 检查Deployment的状态来看部署动作是否完成(Pod副本的数量是否达到预期的值)。
- 更新Deployment以创建新的Pod(比如镜像升级)。
- 如果当前Deployment不稳定,则回滚到一个早先的Deployment版本。
- 挂起或者恢复一个Deployment。
Horizontal Pod Autoscaler(HPA)
Horizontal Pod Autoscaling简称HPA,意思是Pod横向自动扩容,与之前的RC、Deployment样,也属于一种Kubernetes资源对象。通过追踪分析RC控制的所有目标Pod的负载变化情况,来确定是否需要针对性地调整目标Pod的副本数,这是HPA的实现原理。当前,HPA可以有以下两种方式作为Pod负载的度量指标。
- CPUUtilization Percentage
- 应用程序自定义的度量指标,比如服务在每秒内的相应的请求数(TPS或QPS)。
CPUUtilization Percentage是一个算术平均值,即目标Pod所有副本自身的CPU利用率的平均值。一个Pod自身的CPU利用率是该Pod当前CPU的使用量除以它的Pod Request的值,比如我们定义一个Pod的Pod Request为0.4,而当前Pod的CPU使用量为0.2,则它的CPU使用率为50%,如此一来,我们就可以就算出来一个RC控制的所有Pod副本的CPU利用率的算术平均值了。如果某一时刻CPUUtilization Percentage的值超过80%,则意味着当前的Pod副本数很可能不足以支撑接下来更多的请求,需要进行动态扩容,而当请求高峰时段过去后,Pod的CPU利用率又会降下来,此时对应的Pod副本数应该自动减少到一个合理的水平。
CPUUtilization Percentage计算过程中使用到的Pod的CPU使用量通常是1分钟内的平均值,目前通过查询Heapster扩展组件来得到这个值,所以需要安装部署Heapster,这样一来便增加了系统的复杂度和实施HPA特性的复杂度,因此,未来的计划是Kubernetes自身实现一个基础性能数据采集模块,从而更好地支持HPA和其他需要用到基础性能数据的功能模块。此外,我们也看到,如果目标Pod没有定义Pod Request的值,则无法使用CPUUtilization Percentage来实现Pod横向自动扩容的能力。除了使用CPUUtiliationPercentage, Kubernetes从1.2版本开始,尝试支持应用程序自定义的度量指标,目前仍然为实验特性,不建议在生产环境中使用。
Service(服务)
概述
Service也是Kubernetes里的最核心的资源对象之一,Kubernetes里的每个Service其实就是我们经常提起的微服务架构中的一个“微服务”,之前我们所说的Pod、RC等资源对象其实都是为这节所说的“服务”—Kubernetes Service做“嫁衣”的。图1.14显示了Pod、RC与 Service的逻辑关系。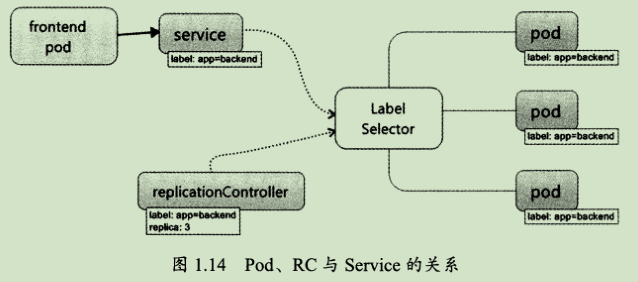
从图1.14中我们看到,Kubernetes的 Service定义了一个服务的访问入口地址,前端的应用(Pod)通过这个入口地址访问其背后的一组由Pod副本组成的集群实例,Service与其后端Pod副本集群之间则是通过Label selector来实现“无缝对接”的。而RC的作用实际上是保证Service的服务能力和服务质量始终处于预期的标准。
运行在每个Node上的kube-proxy进程其实就是一个智能的软件负载均衡器,它负责把对Service的请求转发到后端的某个Pod实例上,并在内部实现服务的负载均衡与会话保持机制。但 Kubernetes发明了一种很巧妙又影响深远的设计:Service不是共用一个负载均衡器的IP地址,而是每个Service分配了一个全局唯一的虚拟IP地址,这个虚拟IP被称为Cluster IP。这样一来,每个服务就变成了具备唯一IP地址的“通信节点”,服务调用就变成了最基础的TCP网络通信问题。
我们知道,Pod的Endpoint地址会随着Pod的销毁和重新创建而发生改变,因为新Pod的IP地址与之前旧Pod的不同。而 Service一旦创建, Kubernetes就会自动为它分配一个可用的Cluster IP,而且在Service的整个生命周期内,它的Cluster IP不会发生改变。于是,服务发现这个棘手的问题在Kubernetes的架构里也得以轻松解决:只要用Service的Name与Service的Cluster IP地址做一个DNS域名映射即可完美解决问题。现在想想,这真是一个很棒的设计。
Kubernetes的服务发现机制
任何分布式系统都会涉及“服务发现”这个基础问题,大部分分布式系统通过提供特定的API接口来实现服务发现的功能,但这样做会导致平台的侵入性比较强,也增加了开发测试的困难。Kubernetes则采用了直观朴素的思路去解决这个棘手的问题。
首先,每个Kubernetes中的Service都有一个唯一的Cluster IP以及唯一的名字,而名字是由开发者自己定义的,部署的时候也没必要改变,所以完全可以固定在配置中。接下来的问题就是如何通过Service的名字找到对应的Cluster IP?
Kubernetes通过Add-On增值包的方式引入了DNS系统,把服务名作为DNs域名,这样一来,程序就可以直接使用服务名来建立通信连接了。
外部系统访问Service的问题
为了更加深入地理解和掌握Kubernetes,我们需要弄明白Kubernetes里的“三种IP”这个关键问题,这三种IP分别如下。
- Node IP:Node节点的IP地址。
- Pod IP:Pod的IP地址
- Cluster IP: Service的IP地址。
首先,Node IP是Kubernetes集群中每个节点的物理网卡的IP地址,这是一个真实存在的物理网络,所有属于这个网络的服务器之间都能通过这个网络直接通信,不管它们中是否有部分节点不属于这个Kubernetes集群。这也表明了Kubernetes集群之外的节点访问Kubernetes集群之内的某个节点或者TCP/IP服务的时候,必须要通过Node IP进行通信。
其次,Pod IP是每个Pod的IP地址,它是Docker Engine根据docker0网桥的IP地址段进行分配的,通常是一个虚拟的二层网络,前面我们说过,Kubernetes要求位于不同Node上的Pod能够彼此直接通信,所以Kubernetes里一个Pod里的容器访问另外一个Pod里的容器,就是通过Pod IP所在的虚拟二层网络进行通信的,而真实的TCP/IP流量则是通过Node IP所在的物理网卡流出的。
最后,我们说说Service的Cluster IP,它也是一个虚拟的IP,但更像是一个“伪造”的IP网络,原因有以下几点。
- Cluster IP仅仅作用于Kubernetes Service这个对象,并由Kubernetes管理和分配IP地址(来源于Cluster IP地址池)。
- Cluster IP无法被Ping,因为没有一个“实体网络对象”来响应。
- Cluster IP只能结合Service Port组成一个具体的通信端口,单独的Cluster IP不具备TCP/IP通信的基础,并且它们属于Kubernetes集群这样一个封闭的空间,集群之外的节点如果要访问这个通信端口,则需要做一些额外的工作。
- 在Kubernetes集群之内,Node IP网、Pod IP网与Cluster IP网之间的通信,采用的是Kubernetes自己设计的一种编程方式的特殊的路由规则,与我们所熟知的IP路由有很大的不同。
NodePort的实现方式是在Kubernetes集群里的每个Node上为需要外部访问的Service开启个对应的TCP监听端口,外部系统只要用任意一个Node的IP地址+具体的NodePort端口号即可访问此服务。
但NodePort还没有完全解决外部访问Service的所有问题,比如负载均衡问题,假如我们的集群中有10个Node,则此时最好有一个负载均衡器,外部的请求只需访问此负载均衡器的IP地址,由负载均衡器负责转发流量到后面某个Node的NodePort上。如图1.17所示。
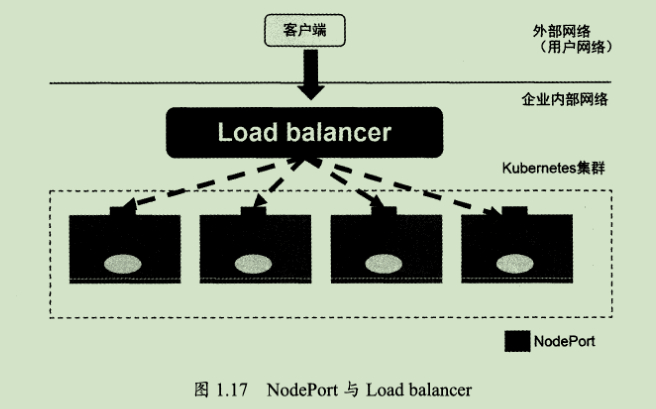
图1.17中的Load balancer组件独立于Kubernetes集群之外,通常是一个硬件的负载均衡器,或者是以软件方式实现的,例如HAProxy或者Nginx。对于每个Service,我们通常需要配置个对应的Load balancer实例来转发流量到后端的Node上,这的确增加了工作量及出错的概率。于是Kubernetes提供了自动化的解决方案,如果我们的集群运行在谷歌的GCE公有云上,那么只要我们把Service的type=Node Port改为type=LoadBalancer,此时Kubernetes会自动创建个对应的Load balancer实例并返回它的IP地址供外部客户端使用。其他公有云提供商只要实现了支持此特性的驱动,则也可以达到上述目的。此外,裸机上的类似机制(Bare Metal Service Load Balancers)也正在被开发。
Volume(存储卷)
Volume是Pod中能够被多个容器访问的共享目录Kubernetes Volume概念、用途和目的与Docker的Volume比较类似,但两者不能等价。首先,Kubernetes中的Volume定义在Pod上,然后被一个Pod里的多个容器挂载到具体的文件目录下;其次,Kubernetes中的Volume与Pod的生命周期相同,但与容器的生命周期不相关,当容器终止或者重启时,Volume中的数据也不会丢失。最后,Kubernetes支持多种类型的 Volume,例如GlusterFS、ceph等先进的分布式文件系统。
除了可以让一个Pod里的多个容器共享文件、让容器的数据写到宿主机的磁盘上或者写文件到网络存储中, Kubernetes的Volume还扩展出了一种非常有实用价值的功能,即容器配置文件集中化定义与管理,这是通过ConfigMap这个新的资源对象来实现的,后面我们会详细说明。
Kubernetes提供了非常丰富的Volume类型,下面逐一进行说明。
empty Dir
一个empty Dir Volume是在Pod分配到Node时创建的。从它的名称就可以看出,它的初始内容为空,并且无须指定宿主机上对应的目录文件,因为这是 Kubernetes自动分配的一个目录当Pod从Node上移除时,empty Dir中的数据也会被永久删除。empty Dir的一些用途如下。
- 临时空间,例如用于某些应用程序运行时所需的临时目录,且无须永久保留。
- 长时间任务的中间过程 Check Point的临时保存目录。
- 一个容器需要从另一个容器中获取数据的目录(多容器共享目录)。
目前,用户无法控制emptyDir使用的介质种类。如果kubelet的配置是使用硬盘,那么所有empty都将创建在该硬盘上。Pod在将来可以设置empty Dir是位于硬盘、固态硬盘上还是基于内存的tmpfs上,上面的例子便采用了emptyDir类的 Volume。
hostPath
hostPath为在Pod上挂载宿主机上的文件或目录,它通常可以用于以下几方面:
- 容器应用程序生成的日志文件需要永久保存时,可以使用宿主机的高速文件系统进行存储。
- 需要访问宿主机上Docker引擎内部数据结构的容器应用时,可以通过定义hostPath为宿主机/var/lib/docker目录,使容器内部应用可以直接访问Docker的文件系统。
在使用这种类型的Volume时,需要注意以下几点。
- 在不同的Node上具有相同配置的Pod可能会因为宿主机上的目录和文件不同而导致对Volume上目录和文件的访问结果不一致。
- 如果使用了资源配额管理,则 Kubernetes无法将 hostPath在宿主机上使用的资源纳入管理。
gcePersistentDisk
使用这种类型的Volume表示使用谷歌公有云提供的永久磁盘(Persistent Disk,PD)存放Volume的数据,它与Empty Dir不同,PD上的内容会被永久保存,当Pod被删除时,PD只是被卸载(Unmount),但不会被删除。需要注意的是,你需要先创建一个永久磁盘(PD),才能使用gcePersistent Disk。
使用gcePersistent Disk有以下一些限制条件。
- Node(运行 kubelet的节点)需要是GCE虚拟机。
- 这些虚拟机需要与PD存在于相同的GCE项目和Zone中。
awsElasticBlock Store
与GCE类似,该类型的Volume使用亚马逊公有云提供的EBS Volume存储数据,需要先创建一个EBS Volume才能使用awsElasticBlockStore。
使用awsElasticBlockStore的一些限制条件如下。
- Node(运行kubelet的节点)需要是AWS EC2实例。
- 这些AWS EC2实例需要与EBS volume存在于相同的region和availability-zone中。
- EBS只支持单个EC2实例mount一个volume。
NFS
使用NFS网络文件系统提供的共享目录存储数据时,我们需要在系统中部署一个NFS Server。
其他类型的Volume
- iscsi:使用 ISCSI存储设备上的目录挂载到Pod中。
- flocker:使用 Flocker来管理存储卷。
- glusterfs:使用开源GlusterFS网络文件系统的目录挂载到Pod中。
- rbd:使用Linux块设备共享存储(Rados block device)挂载到Pod中。
- gitRepo:通过挂载一个空目录,并从GIT库clone一个git repository以供Pod使用。
- secret:一个secret volume用于为Pod提供加密的信息,你可以将定义在Kubernetes中的secret直接挂载为文件让Pod访问。secret volume是通过tmfs(内存文件系统)实现的,所以这种类型的volume总是不会持久化的。
Persistent Volume
之前我们提到的Volume是定义在Pod上的,属于“计算资源”的一部分,而实际上,“网络存储”是相对独立于“计算资源”而存在的一种实体资源。比如在使用虚机的情况下,我们通常会先定义一个网络存储,然后从中划出一个“网盘”并挂接到虚机上。Persistent Volume(简称PV)和与之相关联的Persistent Volume Claim(简称PVC)也起到了类似的作用。
PV可以理解成Kubernetes集群中的某个网络存储中对应的一块存储,它与Volume很类似,
但有以下区别。
- PV只能是网络存储,不属于任何Node,但可以在每个Node上访问。
- PV并不是定义在Pod上的,而是独立于Pod之外定义。
- PV目前只有几种类型: GCE Persistent Disks、NFS、RBD、 ISCSI、AWS、ElasticBlock Store、 GlusterFS等。
比较重要的是PV的accessModes属性,目前有以下类型:
- Read WriteOnce:读写权限、并且只能被单个Node挂载。
- ReadOnly Many:只读权限、允许被多个Node挂载。
- Read WriteMany:读写权限、允许被多个Node挂载。
如果某个Pod想申请某种条件的PV,则首先需要定义一个Persistent Volume Claim(PVC)。
最后,我们说说PV的状态,PV是有状态的对象,它有以下几种状态。
- Available:空闲状态。
- Bound:已经绑定到某个PVC上。
- Released:对应的PVC已经删除,但资源还没有被集群收回。
- Failed:PⅤ自动回收失败。
Namespace(命名空间)
Namespace(命名空间)是Kubernetes系统中的另一个非常重要的概念,Namespace在很多情况下用于实现多租户的资源隔离。Namespace通过将集群内部的资源对象“分配”到不同的Namespace中,形成逻辑上分组的不同项目、小组或用户组,便于不同的分组在共享使用整个集群的资源的同时还能被分别管理。
Annotation(注解)
Annotation与Label类似,也使用key/value键值对的形式进行定义。不同的是Label具有严格的命名规则,它定义的是 Kubernetes对象的元数据(Metadata),并且用于Label Selector而Annotation则是用户任意定义的“附加”信息,以便于外部工具进行查找,很多时候,Kubernetes的模块自身会通过Annotation的方式标记资源对象的一些特殊信息。
通常来说,用Annotation来记录的信息如下。
- build信息、release信息、Docker镜像信息等,例如时间戳、release id号、PR号、镜像hash值、docker registry地址等。
- 日志库、监控库、分析库等资源库的地址信息
- 程序调试工具信息,例如工具名称、版本号等
- 团队的联系信息,例如电话号码、负责人名称、网址等。
只看了第一章