Linux性能优化实战 笔记
《Linux性能优化实战》学习笔记,涵盖平均负载、CPU使用率、内存管理、I/O性能、网络性能等核心知识点。
Linux性能优化实战
作者: 倪朋飞
平均负载
概念
简单来说,平均负载是指单位时间内,系统处于可运行状态和不可中断状态的平均进程数,也就是平均活跃进程数,它和CPU使用率并没有直接关系。这里我先解释下,可运行状态和不可中断状态这俩词儿。
所谓可运行状态的进程,是指正在使用CPU或者正在等待CPU的进程,也就是我们常用ps命令看到的,处于R状态(Running或Runnable)的进程。
不可中断状态的进程则是正处于内核态关键流程中的进程,并且这些流程是不可打断的,比如最常见的是等待硬件设备的I/O响应,也就是我们在ps命令中看到的D状态(Uninterruptible Sleep,也称为 Disk leep)的进程。
比如,当一个进程向磁盘读写数据时,为了保证数据的一致性,在得到磁盘回复前,它是不能被其他进程或者中断打断的,这个时候的进程就处于不可中断状态。如果此时的进程被打断了,就容易出现磁盘数据与进程数据不一致的问题。
所以,不可中断状态实际上是系统对进程和硬件设备的一种保护机制。因此,你可以简单理解为,平均负载其实就是平均活跃进程数。平均活跃进程数,直观上的理解就是单位时间内的活跃进程数,但它实际上是活跃进程数的指数衰减平均值。
获取CPU核数
1 | grep 'model name' /proc/cpuinfo | wc -l |
小结
平均负载提供了一个快速查看系统整体性能的手段,反映了整体的负载情况。但只看平均负载本身,我们并不能直接发现,到底是哪里出现了瓶颈。所以,在理解平均负载时,也要注意:
- 平均负载高有可能是CPU密集型进程导致的;
- 平均负载高并不一定代表CPU使用率高,还有可能是I/O更繁忙了;
- 当发现负载高的时候,你可以使用mpstat、pidstat等工具,辅助分析负载的来源。
CPU上下文切换
线程与进程最大的区别在于,线程是调度的基本单位,而进程则是资源拥有的基本单位。说白了,所谓内核中的任务调度,实际上的调度对象是线程;而进程只是给线程提供了虚拟内存、全局变量等资源。
根据 Tsuna 的测试报告,每次上下文切换都需要几十纳秒到数微秒的 CPU 时间。这个时间还是相当可观的,特别是在进程上下文切换次数较多的情况下,很容易导致 CPU 将大量时间耗费在寄存器、内核栈以及虚拟内存等资源的保存和恢复上,进而大大缩短了真正运行进程的时间。
实践
CPU 使用率
GDB 并不适合在性能分析的早期应用。
为什么呢?因为 GDB 调试程序的过程会中断程序运行,这在线上环境往往是不允许的。所以,GDB 只适合用在性能分析的后期,当你找到了出问题的大致函数后,线下再借助它来进一步调试函数内部的问题。
那么哪种工具适合在第一时间分析进程的 CPU 问题呢?我的推荐是 perf。perf 是 Linux 2.6.31 以后内置的性能分析工具。它以性能事件采样为基础,不仅可以分析系统的各种事件和内核性能,还可以用来分析指定应用程序的性能问题。
使用 perf 分析 CPU 性能问题,我来说两种最常见、也是我最喜欢的用法。
第一种常见用法是 perf top,类似于 top,它能够实时显示占用 CPU 时钟最多的函数或者指令,因此可以用来查找热点函数,使用界面如下所示:
1 | $ perf top |
输出结果中,第一行包含三个数据,分别是采样数(Samples)、事件类型(event)和事件总数量(Event count)。比如这个例子中,perf 总共采集了 833 个 CPU 时钟事件,而总事件数则为 97742399。
另外,采样数需要我们特别注意。如果采样数过少(比如只有十几个),那下面的排序和百分比就没什么实际参考价值了。
再往下看是一个表格式样的数据,每一行包含四列,分别是:
第一列 Overhead ,是该符号的性能事件在所有采样中的比例,用百分比来表示。
第二列 Shared ,是该函数或指令所在的动态共享对象(Dynamic Shared Object),如内核、进程名、动态链接库名、内核模块名等。
第三列 Object ,是动态共享对象的类型。比如 [.] 表示用户空间的可执行程序、或者动态链接库,而 [k] 则表示内核空间。
最后一列 Symbol 是符号名,也就是函数名。当函数名未知时,用十六进制的地址来表示。
还是以上面的输出为例,我们可以看到,占用 CPU 时钟最多的是 perf 工具自身,不过它的比例也只有 7.28%,说明系统并没有 CPU 性能问题。 perf top 的使用你应该很清楚了吧。
接着再来看第二种常见用法,也就是 perf record 和 perf report。 perf top 虽然实时展示了系统的性能信息,但它的缺点是并不保存数据,也就无法用于离线或者后续的分析。而 perf record 则提供了保存数据的功能,保存后的数据,需要你用 perf report 解析展示。
1 | $ perf record # 按 Ctrl+C 终止采样 |
在实际使用中,我们还经常为 perf top 和 perf record 加上 -g 参数,开启调用关系的采样,方便我们根据调用链来分析性能问题。
小结
- 用户 CPU 和 Nice CPU 高,说明用户态进程占用了较多的 CPU,所以应该着重排查进程的性能问题。
- 系统 CPU 高,说明内核态占用了较多的 CPU,所以应该着重排查内核线程或者系统调用的性能问题。
- I/O 等待 CPU 高,说明等待 I/O 的时间比较长,所以应该着重排查系统存储是不是出现了 I/O 问题。
- 软中断和硬中断高,说明软中断或硬中断的处理程序占用了较多的 CPU,所以应该着重排查内核中的中断服务程序。
碰到 CPU 使用率升高的问题,你可以借助 top、pidstat 等工具,确认引发 CPU 性能问题的来源;再使用 perf 等工具,排查出引起性能问题的具体函数。
短时应用的运行时间比较短,很难在 top 或者 ps 这类展示系统概要和进程快照的工具中发现,你需要使用记录事件的工具来配合诊断,比如 execsnoop 或者 perf top。
实践
系统中出现大量不可中断进程和僵尸进程怎么办?
Top 输出分析
下面是一个 top 命令输出的示例,S 列(也就是 Status 列)表示进程的状态。从这个示例里,你可以看到
R、D、Z、S、I 等几个状态,它们分别是什么意思呢?
1 | $ top |
我们挨个来看一下:
- R 是 Running 或 Runnable 的缩写,表示进程在 CPU 的就绪队列中,正在运行或者正在等待运行。
- D 是 Disk Sleep 的缩写,也就是不可中断状态睡眠(Uninterruptible Sleep),一般表示进程正在跟硬件交互,并且交互过程不允许被其他进程或中断打断。
- Z 是 Zombie 的缩写,如果你玩过“植物大战僵尸”这款游戏,应该知道它的意思。它表示僵尸进程,也就是进程实际上已经结束了,但是父进程还没有回收它的资源(比如进程的描述符、PID 等)。
- S 是 Interruptible Sleep 的缩写,也就是可中断状态睡眠,表示进程因为等待某个事件而被系统挂起。当进程等待的事件发生时,它会被唤醒并进入 R 状态。
- I 是 Idle 的缩写,也就是空闲状态,用在不可中断睡眠的内核线程上。前面说了,硬件交互导致的不可中断进程用 D 表示,但对某些内核线程来说,它们有可能实际上并没有任何负载,用 Idle 正是为了区分这种情况。要注意,D 状态的进程会导致平均负载升高, I 状态的进程却不会。
当然了,上面的示例并没有包括进程的所有状态。除了以上 5 个状态,进程还包括下面这2个状态。
第一个是 T 或者 t,也就是 Stopped 或 Traced 的缩写,表示进程处于暂停或者跟踪状态。
向一个进程发送 SIGSTOP 信号,它就会因响应这个信号变成暂停状态(Stopped);再向它发送 SIGCONT 信号,进程又会恢复运行(如果进程是终端里直接启动的,则需要你用 fg 命令,恢复到前台运行)。
而当你用调试器(如 gdb)调试一个进程时,在使用断点中断进程后,进程就会变成跟踪状态,这其实也是一种特殊的暂停状态,只不过你可以用调试器来跟踪并按需要控制进程的运行。
另一个是 X,也就是 Dead 的缩写,表示进程已经消亡,所以你不会在 top 或者 ps 命令中看到它。
僵尸进程,这是多进程应用很容易碰到的问题。正常情况下,当一个进程创建了子进程后,它应该通过系统调用 wait() 或者 waitpid() 等待子进程结束,回收子进程的资源而子进程在结束时,会向它的父进程发送 SIGCHLD 信号,所以,父进程还可以注册SIGCHLD 信号的处理函数,异步回收资源。
如果父进程没这么做,或是子进程执行太快,父进程还没来得及处理子进程状态,子进程就已经提前退出,那这时的子进程就会变成僵尸进程。换句话说,父亲应该一直对儿子负责,善始善终,如果不作为或者跟不上,都会导致“问题少年”的出现。
通常,僵尸进程持续的时间都比较短,在父进程回收它的资源后就会消亡;或者在父进程退出后,由 init 进程回收后也会消亡。
一旦父进程没有处理子进程的终止,还一直保持运行状态,那么子进程就会一直处于僵尸状态。大量的僵尸进程会用尽 PID 进程号,导致新进程不能创建,所以这种情况一定要避免。
不可中断状态,表示进程正在跟硬件交互,为了保护进程数据和硬件的一致性,系统不允许其他进程或中断打断这个进程。进程长时间处于不可中断状态,通常表示系统有 I/O 性能问题。
实践
dstat命令 是一个用来替换vmstat、iostat、netstat、nfsstat和ifstat这些命令的工具,是一个全能系统信息统计工具。与sysstat相比,dstat拥有一个彩色的界面,在手动观察性能状况时,数据比较显眼容易观察;而且dstat支持即时刷新,譬如输入dstat 3即每三秒收集一次,但最新的数据都会每秒刷新显示。和sysstat相同的是,dstat也可以收集指定的性能资源,譬如dstat -c即显示CPU的使用情况。
怎么理解Linux软中断?
如何迅速分析出系统CPU的瓶颈在哪里?
pidstat 中, %wait 表示进程等待 CPU 的时间百分比。
top 中 ,iowait% 则表示等待 I/O 的 CPU 时间百分比。
Linux性能优化答疑
关注一下:【问题 2:如何用 perf 工具分析 Java 程序】
像是 Java 这种通过 JVM 来运行的应用程序,运行堆栈用的都是 JVM 内置的函数和堆栈管理。所以,从系统层面你只能看到JVM的函数堆栈,而不能直接得到 Java 应用程序的堆栈。
perf_events 实际上已经支持了 JIT,但还需要一个 /tmp/perf-PID.map 文件,来进行符号翻译。当然,开源项目 perf-map-agent 可以帮你生成这个符号表。
怎么理解内存中的Buffer和Cache?
1 | # 注意不同版本的 free 输出可能会有所不同 |
这里的大部分指标都比较容易理解,但 Buffer 和 Cache 可能不太好区分。从字面上来说,Buffer 是缓冲区,而 Cache 是缓存,两者都是数据在内存中的临时存储。那么,你知道这两种“临时存储”有什么区别吗?
free 数据的来源
Buffers 是内核缓冲区用到的内存,对应的是 /proc/meminfo 中的 Buffers 值。
Cache 是内核页缓存和 Slab 用到的内存,对应的是 /proc/meminfo 中的 Cached 与 SReclaimable 之和。
proc 文件系统
/proc 是 Linux 内核提供的一种特殊文件系统,是用户跟内核交互的接口。比方说,用户可以从 /proc 中查询内核的运行状态和配置选项,查询进程的运行状态、统计数据等,当然,你也可以通过 /proc 来修改内核的配置。
proc 文件系统同时也是很多性能工具的最终数据来源。比如我们刚才看到的 free ,就是通过读取 /proc/meminfo ,得到内存的使用情况。
Buffers 是对原始磁盘块的临时存储,也就是用来缓存磁盘的数据,通常不会特别大(20MB 左右)。这样,内核就可以把分散的写集中起来,统一优化磁盘的写入,比如可以把多次小的写合并成单次大的写等等。
Cached 是从磁盘读取文件的页缓存,也就是用来缓存从文件读取的数据。这样,下次访问这些文件数据时,就可以直接从内存中快速获取,而不需要再次访问缓慢的磁盘。SReclaimable 是 Slab 的一部分。Slab 包括两部分,其中的可回收部分,用SReclaimable 记录;而不可回收部分,用 SUnreclaim 记录。
Buffer 是对磁盘数据的缓存,而 Cache 是文件数据的缓存,它们既会用在读请求中,也会用在写请求中。
磁盘与文件
磁盘是一个存储设备(确切地说是块设备),可以被划分为不同的磁盘分区。而在磁盘或者磁盘分区上,还可以再创建文件系统,并挂载到系统的某个目录中。这样,系统就可以通过这个挂载目录,来读写文件。
换句话说,磁盘是存储数据的块设备,也是文件系统的载体。所以,文件系统确实还是要通过磁盘,来保证数据的持久化存储。
你在很多地方都会看到这句话, Linux 中一切皆文件。换句话说,你可以通过相同的文件接口,来访问磁盘和文件(比如 open、read、write、close 等)。
在读写普通文件时,I/O 请求会首先经过文件系统,然后由文件系统负责,来与磁盘进行交互。而在读写块设备文件时,会跳过文件系统,直接与磁盘交互,也就是所谓的“裸I/O”。
这两种读写方式使用的缓存自然不同。文件系统管理的缓存,其实就是 Cache 的一部分。而裸磁盘的缓存,用的正是 Buffer。
cache是针对文件系统的缓存,而 buffers是对磁盘数据的缓存,是直接跟硬件那一层相关的,那一般来说, cache会比 buffers 的数量大了很多。
案例
为什么系统的Swap变高了?
NUMA 与 Swap
在内存资源紧张时,Linux 会通过 Swap ,把不常访问的匿名页换出到磁盘中,下次访问的时候再从磁盘换入到内存中来。你可以设置 /proc/sys/vm/min_free_kbytes,来调整系统定期回收内存的阈值;也可以设置 /proc/sys/vm/swappiness,来调整文件页和匿名页的回收倾向。
当 Swap 变高时,你可以用 sar、/proc/zoneinfo、/proc/pid/status 等方法,查看系统和进程的内存使用情况,进而找出 Swap 升高的根源和受影响的进程。
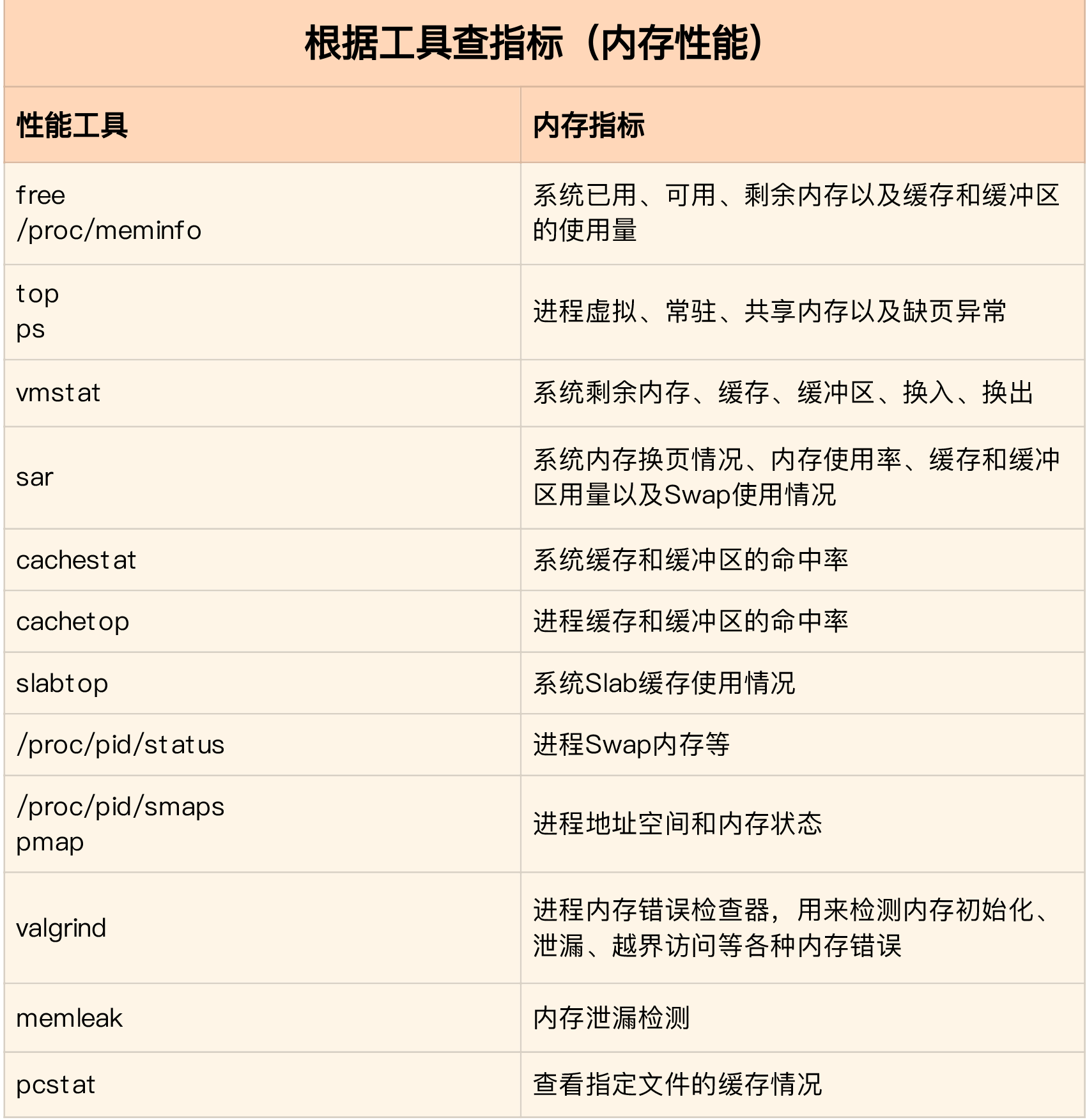
如何“快准狠”找到系统内存的问题?
为了迅速定位内存问题,我通常会先运行几个覆盖面比较大的性能工具,比如free、top、vmstat、pidstat 等。
具体的分析思路主要有这几步。
- 先用 free 和 top,查看系统整体的内存使用情况。
- 再用 vmstat 和 pidstat,查看一段时间的趋势,从而判断出内存问题的类型。
- 最后进行详细分析,比如内存分配分析、缓存 / 缓冲区分析、具体进程的内存使用分析等。
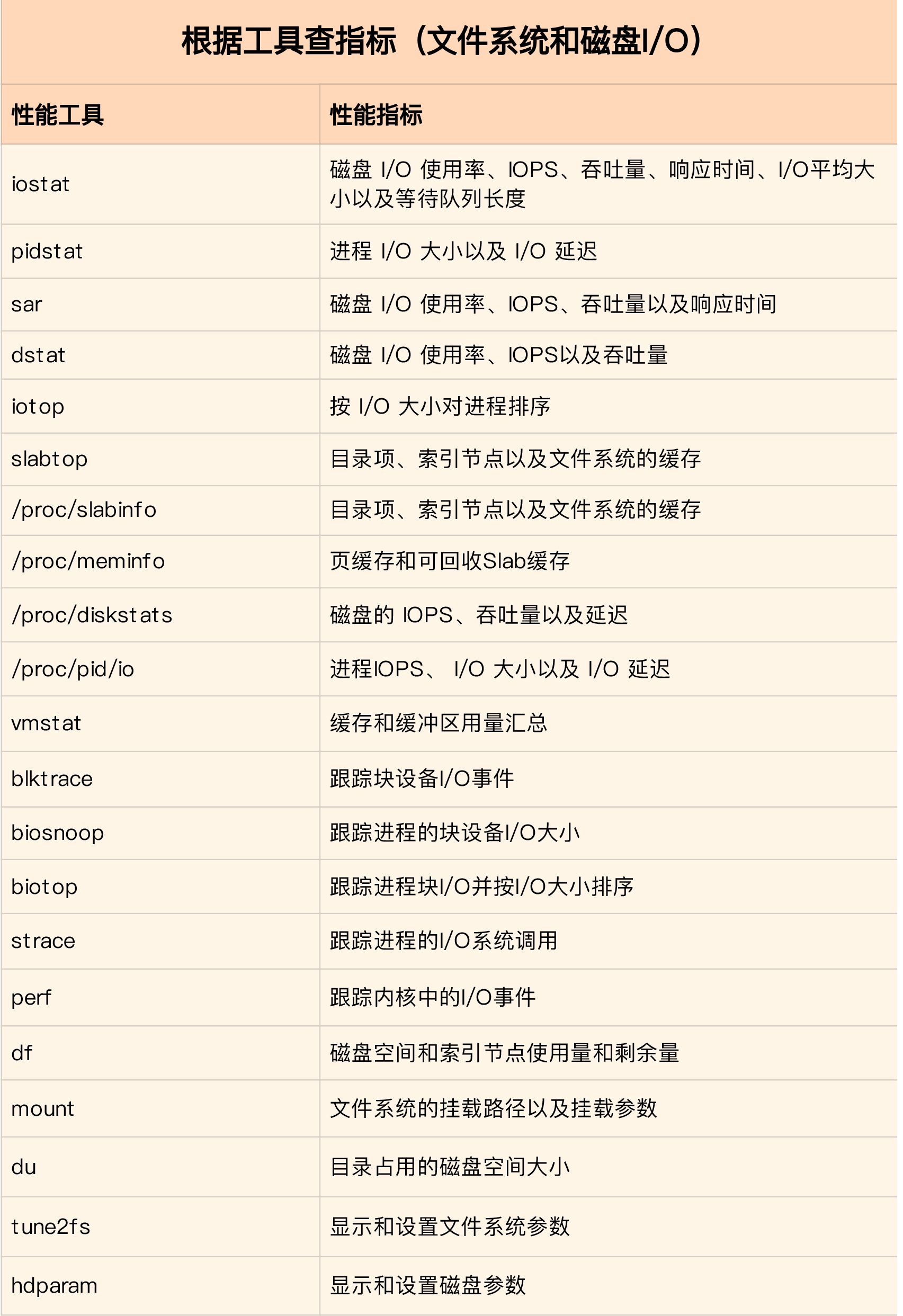
根据指标查找工具
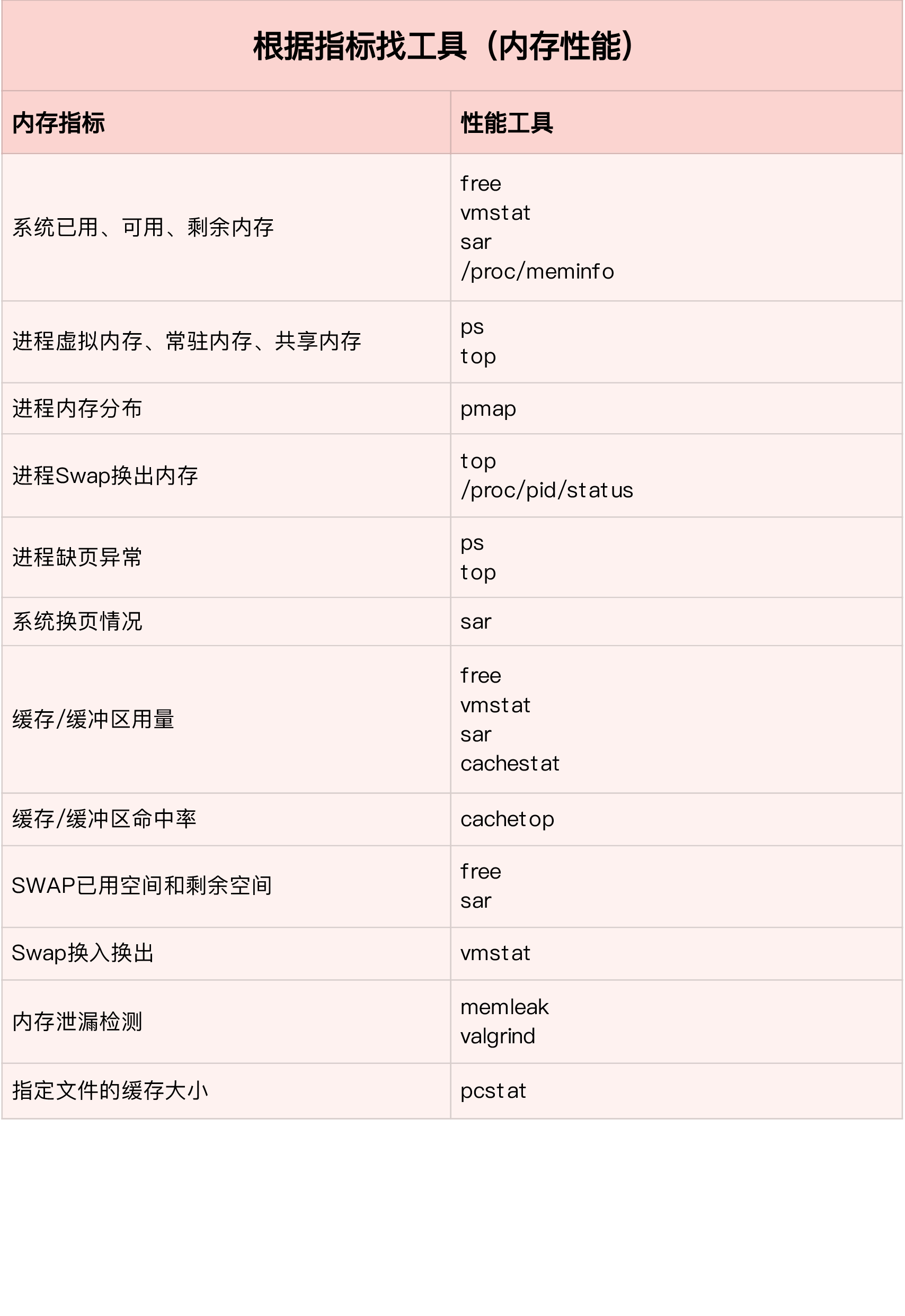
根据工具查找指标
Linux 磁盘I/O是怎么工作的?
磁盘性能指标
说到磁盘性能的衡量标准,必须要提到五个常见指标,也就是我们经常用到的,使用率、饱和度、IOPS、吞吐量以及响应时间等。这五个指标,是衡量磁盘性能的基本指标。
- 使用率,是指磁盘处理 I/O 的时间百分比。过高的使用率(比如超过 80%),通常意味着磁盘 I/O 存在性能瓶颈。
- 饱和度,是指磁盘处理 I/O 的繁忙程度。过高的饱和度,意味着磁盘存在严重的性能瓶颈。当饱和度为 100% 时,磁盘无法接受新的 I/O 请求。
- IOPS(Input/Output Per Second),是指每秒的 I/O 请求数。
- 吞吐量,是指每秒的 I/O 请求大小。
- 响应时间,是指 I/O 请求从发出到收到响应的间隔时间。
这里要注意的是,使用率只考虑有没有 I/O,而不考虑 I/O 的大小。换句话说,当使用率是 100% 的时候,磁盘依然有可能接受新的 I/O 请求。
这些指标,很可能是你经常挂在嘴边的,一讨论磁盘性能必定提起的对象。不过我还是要强调一点,不要孤立地去比较某一指标,而要结合读写比例、I/O 类型(随机还是连续)以及 I/O 的大小,综合来分析。
磁盘 I/O 观测
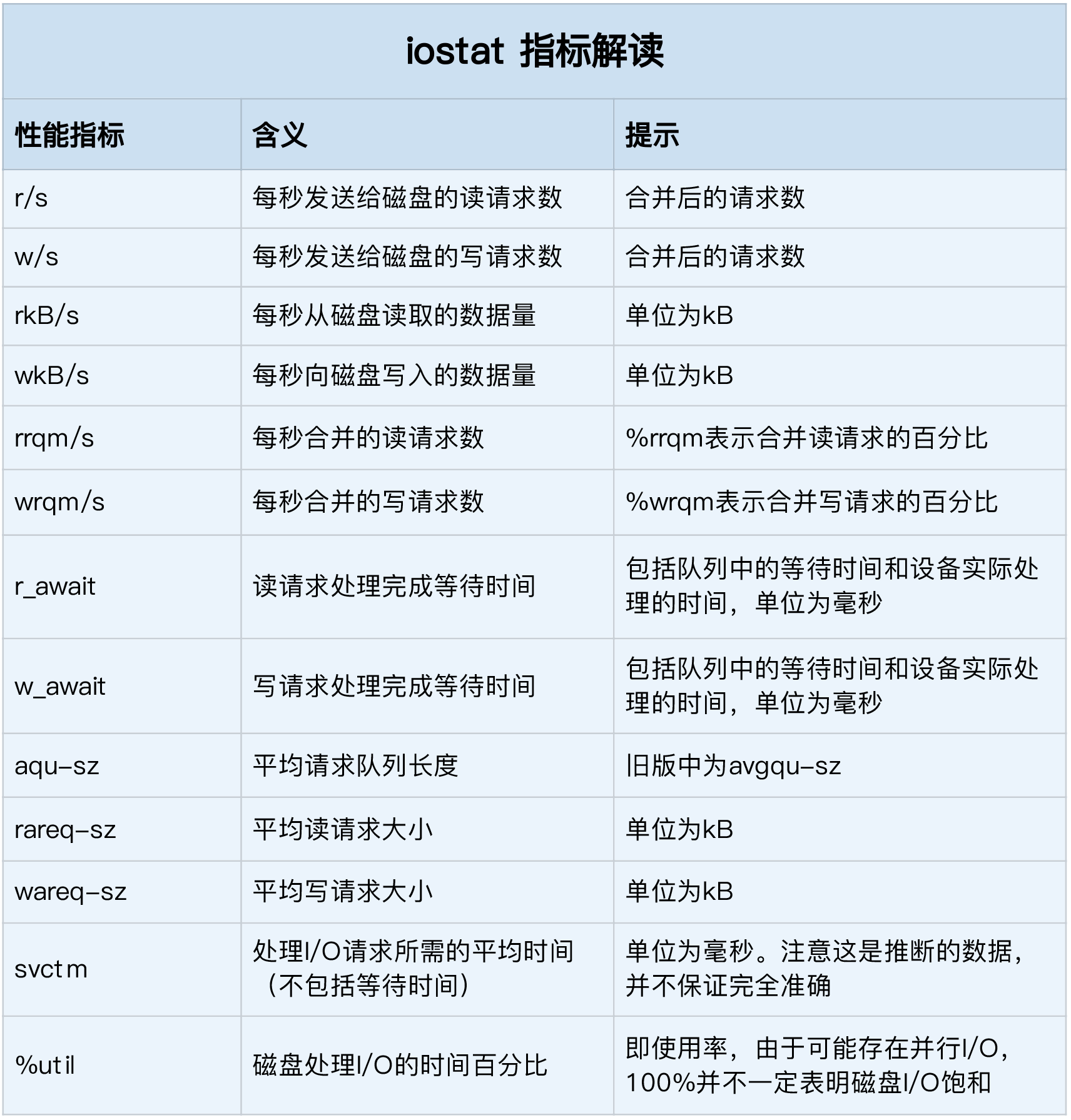
这些指标中,你要注意:
- %util ,就是我们前面提到的磁盘 I/O 使用率;
- r/s+ w/s ,就是 IOPS;
- rkB/s+wkB/s ,就是吞吐量;
- r_await+w_await ,就是响应时间。
在观测指标时,也别忘了结合请求的大小( rareq-sz 和 wareq-sz)一起分析。
进程 I/O 观测
要观察进程的 I/O 情况,你还可以使用 pidstat 和 iotop 这两个工具。
根据指标查找工具
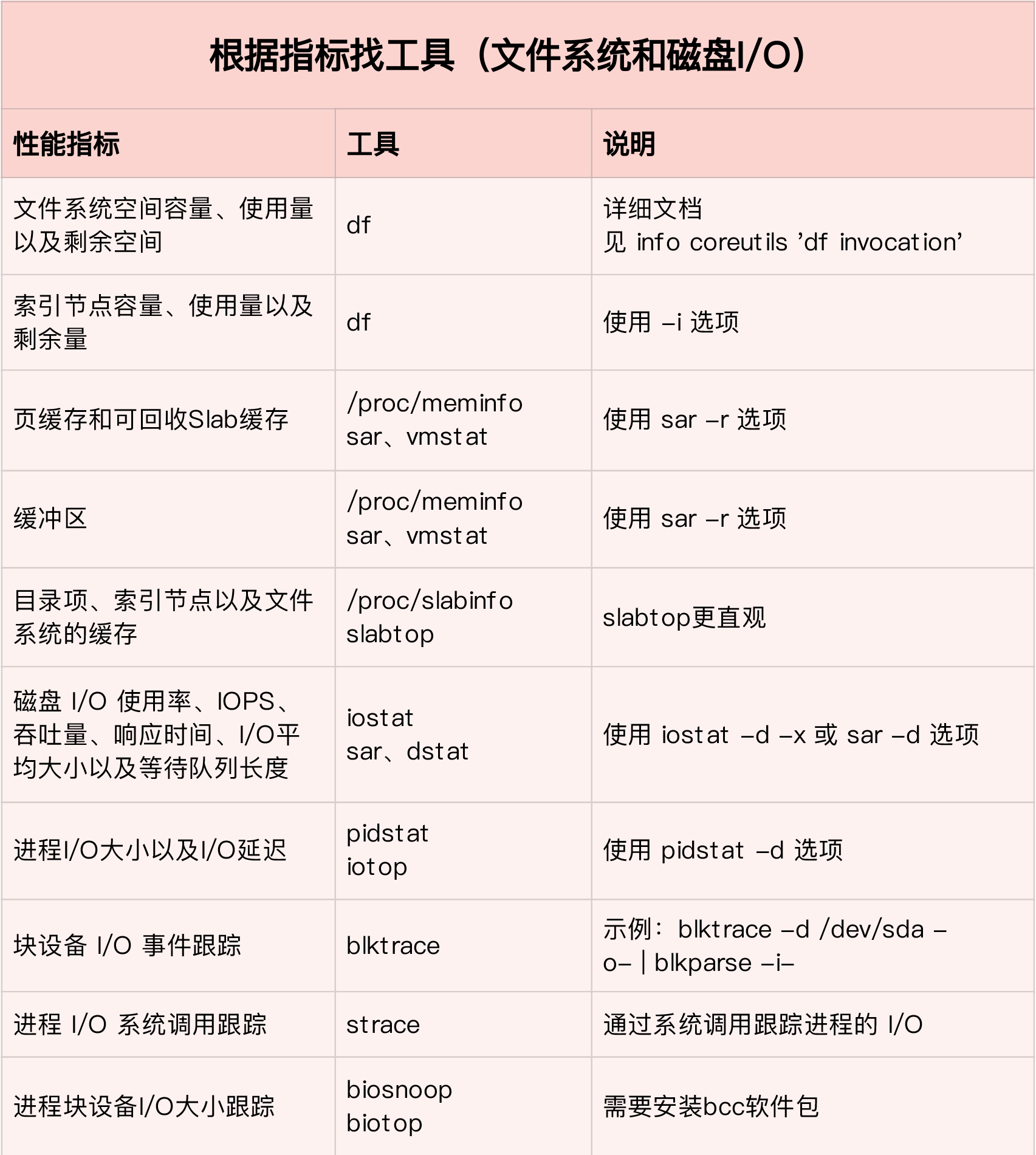
根据工具查找指标
关于 Linux 网络,你必须知道这些
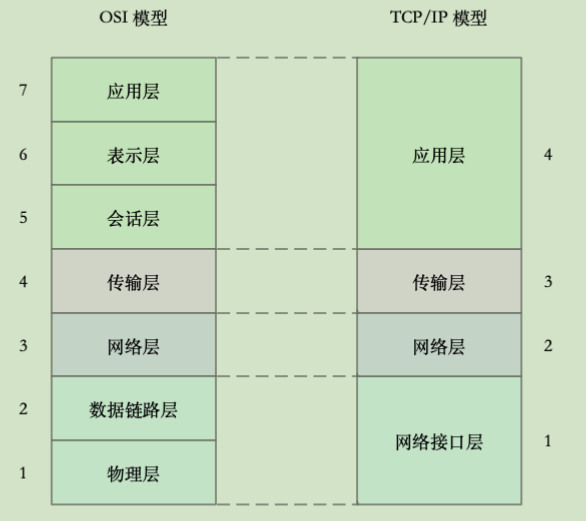
网络模型
为了解决网络互联中异构设备的兼容性问题,并解耦复杂的网络包处理流程,OSI 模型把网络互联的框架分为应用层、表示层、会话层、传输层、网络层、数据链路层以及物理层等七层,每个层负责不同的功能。其中:
- 应用层,负责为应用程序提供统一的接口。
- 表示层,负责把数据转换成兼容接收系统的格式。
- 会话层,负责维护计算机之间的通信连接。
- 传输层,负责为数据加上传输表头,形成数据包。
- 网络层,负责数据的路由和转发。
- 数据链路层,负责 MAC 寻址、错误侦测和改错。
- 物理层,负责在物理网络中传输数据帧。
但是 OSI 模型还是太复杂了,也没能提供一个可实现的方法。所以,在 Linux 中,我们实际上使用的是另一个更实用的四层模型,即 TCP/IP 网络模型。
TCP/IP 模型,把网络互联的框架分为应用层、传输层、网络层、网络接口层等四层,其中:
- 应用层,负责向用户提供一组应用程序,比如 HTTP、FTP、DNS 等。
- 传输层,负责端到端的通信,比如 TCP、UDP 等。
- 网络层,负责网络包的封装、寻址和路由,比如 IP、ICMP 等。
- 网络接口层,负责网络包在物理网络中的传输,比如 MAC 寻址、错误侦测以及通过网卡传输网络帧等。
网络配置
ifconfig 和 ip 分别属于软件包 net-tools 和 iproute2,iproute2 是 net-tools 的下一代。
我个人更推荐使用 ip 工具,因为它提供了更丰富的功能和更易用的接口。
以网络接口 ens160 为例,你可以运行下面的两个命令,查看它的配置和状态:
1 | [root@jiankunking ~]# ip -s addr show dev ens160 |
你可以看到,ifconfig 和 ip 命令输出的指标基本相同,只是显示格式略微不同。比如,它们都包括了网络接口的状态标志、MTU 大小、IP、子网、MAC 地址以及网络包收发的统计信息。
这里有几个跟网络性能密切相关的指标,需要你特别关注一下。
第一,网络接口的状态标志。ifconfig 输出中的 RUNNING ,或 ip 输出中的LOWER_UP ,都表示物理网络是连通的,即网卡已经连接到了交换机或者路由器中。如果你看不到它们,通常表示网线被拔掉了。
第二,MTU 的大小。MTU 默认大小是 1500,根据网络架构的不同(比如是否使用了VXLAN 等叠加网络),你可能需要调大或者调小 MTU 的数值。
第三,网络接口的 IP 地址、子网以及 MAC 地址。这些都是保障网络功能正常工作所必需的,你需要确保配置正确。
第四,网络收发的字节数、包数、错误数以及丢包情况,特别是 TX 和 RX 部分的errors、dropped、overruns、carrier 以及 collisions 等指标不为 0 时,通常表示出现了网络 I/O 问题。其中:
- errors 表示发生错误的数据包数,比如校验错误、帧同步错误等;
- dropped 表示丢弃的数据包数,即数据包已经收到了 Ring Buffer,但因为内存不足等原因丢包;
- overruns 表示超限数据包数,即网络 I/O 速度过快,导致 Ring Buffer 中的数据包来不及处理(队列满)而导致的丢包;
- carrier 表示发生 carrirer 错误的数据包数,比如双工模式不匹配、物理电缆出现问题等;
- collisions 表示碰撞数据包数。
套接字信息
可以用 netstat 或者 ss ,来查看套接字、网络栈、网络接口以及路由表的信息。
我个人更推荐,使用 ss 来查询网络的连接信息,因为它比 netstat 提供了更好的性能(速度更快)。
比如,你可以执行下面的命令,查询套接字信息:
1 | # head -n 3 表示只显示前面 3 行 |
netstat 和 ss 的输出也是类似的,都展示了套接字的状态、接收队列、发送队列、本地地址、远端地址、进程 PID 和进程名称等。
其中,接收队列(Recv-Q)和发送队列(Send-Q)需要你特别关注,它们通常应该是0。当你发现它们不是 0 时,说明有网络包的堆积发生。当然还要注意,在不同套接字状态下,它们的含义不同。
当套接字处于连接状态(Established)时,
- Recv-Q 表示套接字缓冲还没有被应用程序取走的字节数(即接收队列长度)。
- 而 Send-Q 表示还没有被远端主机确认的字节数(即发送队列长度)。
当套接字处于监听状态(Listening)时,
- Recv-Q 表示 syn backlog 的当前值。
- 而 Send-Q 表示最大的 syn backlog 值。
而 syn backlog 是 TCP 协议栈中的半连接队列长度,相应的也有一个全连接队列(accept queue),它们都是维护 TCP 状态的重要机制。
顾名思义,所谓半连接,就是还没有完成 TCP 三次握手的连接,连接只进行了一半,而服务器收到了客户端的 SYN 包后,就会把这个连接放到半连接队列中,然后再向客户端发送SYN+ACK 包。
而全连接,则是指服务器收到了客户端的 ACK,完成了 TCP 三次握手,然后就会把这个连接挪到全连接队列中。这些全连接中的套接字,还需要再被 accept() 系统调用取走,这样,服务器就可以开始真正处理客户端的请求了。
协议栈统计信息
类似的,使用 netstat 或 ss ,也可以查看协议栈的信息:
1 | [root@jiankunking ~]# netstat -s |
这些协议栈的统计信息都很直观。ss 只显示已经连接、关闭、孤儿套接字等简要统计,而netstat 则提供的是更详细的网络协议栈信息。
网络吞吐和 PPS
接下来,我们再来看看,如何查看系统当前的网络吞吐量和 PPS。在这里,我推荐使用我们的老朋友 sar,在前面的 CPU、内存和 I/O 模块中,我们已经多次用到它。
给 sar 增加 -n 参数就可以查看网络的统计信息,比如网络接口(DEV)、网络接口错误(EDEV)、TCP、UDP、ICMP 等等。执行下面的命令,你就可以得到网络接口统计信息:
1 | # 数字 1 表示每隔 1 秒输出一组数据 |
这儿输出的指标比较多,我来简单解释下它们的含义。
- rxpck/s 和 txpck/s 分别是接收和发送的 PPS,单位为包 / 秒。
- rxkB/s 和 txkB/s 分别是接收和发送的吞吐量,单位是 KB/ 秒。
- rxcmp/s 和 txcmp/s 分别是接收和发送的压缩数据包数,单位是包 / 秒。
- %ifutil 是网络接口的使用率,即半双工模式下为 (rxkB/s+txkB/s)/Bandwidth,而全双工模式下为 max(rxkB/s, txkB/s)/Bandwidth。
其中,Bandwidth 可以用 ethtool 来查询,它的单位通常是 Gb/s 或者 Mb/s,不过注意这里小写字母 b ,表示比特而不是字节。我们通常提到的千兆网卡、万兆网卡等,单位也都是比特。如下你可以看到,我的 ens160 网卡就是一个千兆网卡:
1 | [root@jiankunking ~]# ethtool ens160 | grep Speed |
连通性和延时
我们通常使用 ping ,来测试远程主机的连通性和延时,而这基于 ICMP 协议。比如,执行下面的命令,你就可以测试本机到 114.114.114.114 这个 IP 地址的连通性和延时:
1 | # -c3 表示发送三次 ICMP 包后停止 |
ping 的输出,可以分为两部分。
第一部分,是每个 ICMP 请求的信息,包括 ICMP 序列号(icmp_seq)、TTL(生存时间,或者跳数)以及往返延时。
第二部分,则是三次 ICMP 请求的汇总。
比如上面的示例显示,发送了 3 个网络包,并且接收到 3 个响应,没有丢包发生,这说明测试主机到 114.114.114.114 是连通的;平均往返延时(RTT)是 17ms左右,也就是从发送 ICMP 开始,到接收到 114.114.114.114 回复的确认,总共经历 17ms左右。
C10K 和 C1000K
DNS 解析
域名与 DNS 解析
DNS 协议在 TCP/IP 栈中属于应用层,不过实际传输还是基于 UDP 或者 TCP 协议(UDP 居多) ,并且域名服务器一般监听在端口 53 上。
DNS 服务通过资源记录的方式,来管理所有数据,它支持 A、CNAME、MX、NS、PTR 等多种类型的记录。比如:
- A 记录,用来把域名转换成 IP 地址;
- CNAME 记录,用来创建别名;
- 而 NS 记录,则表示该域名对应的域名服务器地址。
如果没有命中缓存,DNS 查询实际上是一个递归过程,那有没有方法可以知道整个递归查询的执行呢?
其实除了 nslookup,另外一个常用的 DNS 解析工具 dig ,就提供了 trace 功能,可以展示递归查询的整个过程。比如你可以执行下面的命令,得到查询结果:
1 | [root@jiankunking ~]# dig +trace +nodnssec jiankunking.com |
dig trace 的输出,主要包括四部分:
第一部分,是从 183.60.83.19 查到的一些根域名服务器(.)的 NS 记录。
第二部分,是从 NS 记录结果中选一个(d.root-servers.net),并查询顶级域名 com.的 NS 记录。
第三部分,是从 com. 的 NS 记录中选择一个(k.gtld-servers.net),并查询二级域名 jiankunking.com. 的 NS 服务器。
最后一部分,就是从 jiankunking.com. 的 NS 服务器(f1g1ns2.dnspod.net)查询最终主机 jiankunking.com. 的 A 记录。
当然,不仅仅是发布到互联网的服务需要域名,很多时候,我们也希望能对局域网内部的主机进行域名解析(即内网域名,大多数情况下为主机名)。Linux 也支持这种行为。
所以,你可以把主机名和 IP 地址的映射关系,写入本机的 /etc/hosts 文件中。这样,指定的主机名就可以在本地直接找到目标 IP。
或者,你还可以在内网中,搭建自定义的 DNS 服务器,专门用来解析内网中的域名。而内网 DNS 服务器,一般还会设置一个或多个上游 DNS 服务器,用来解析外网的域名。
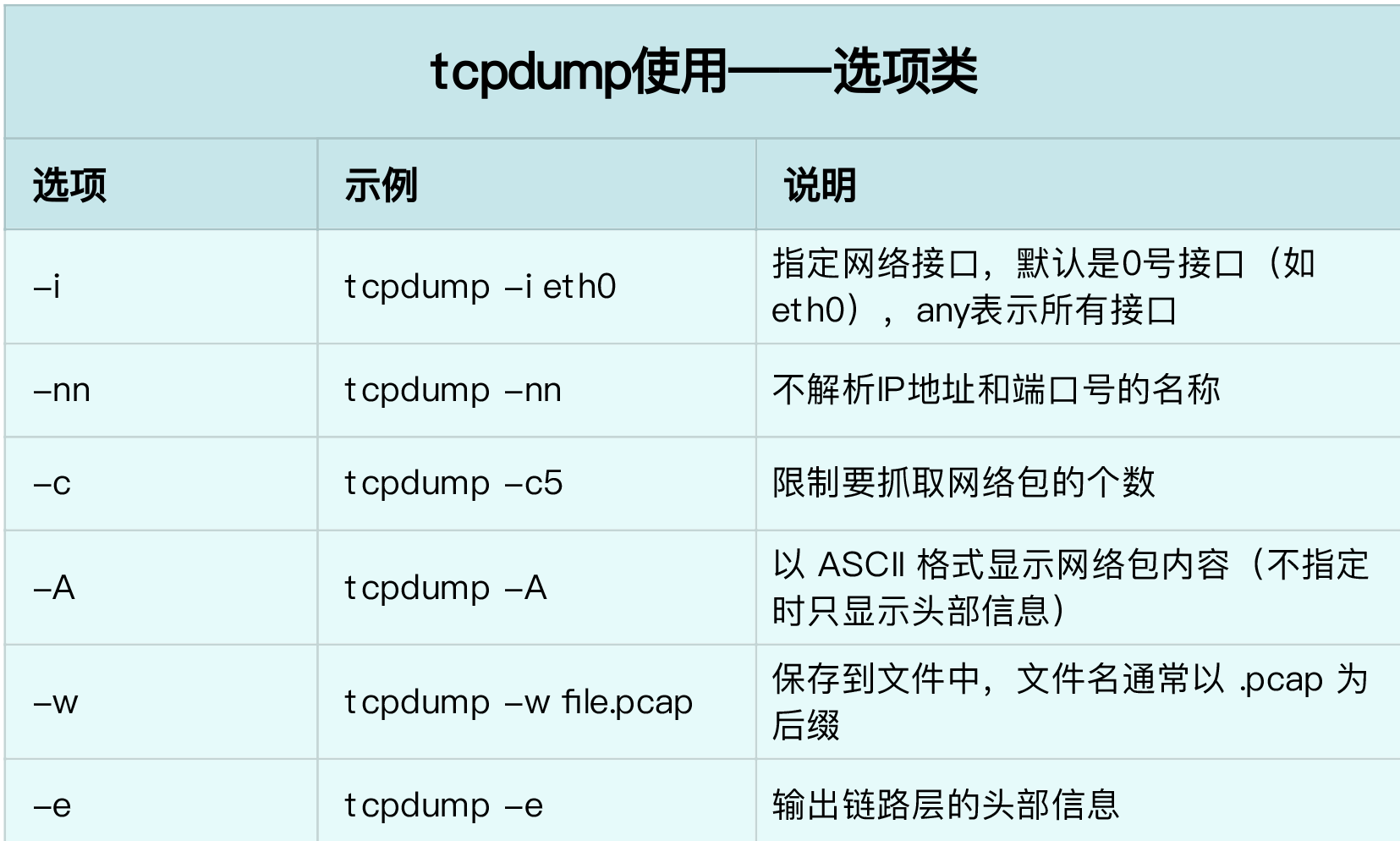
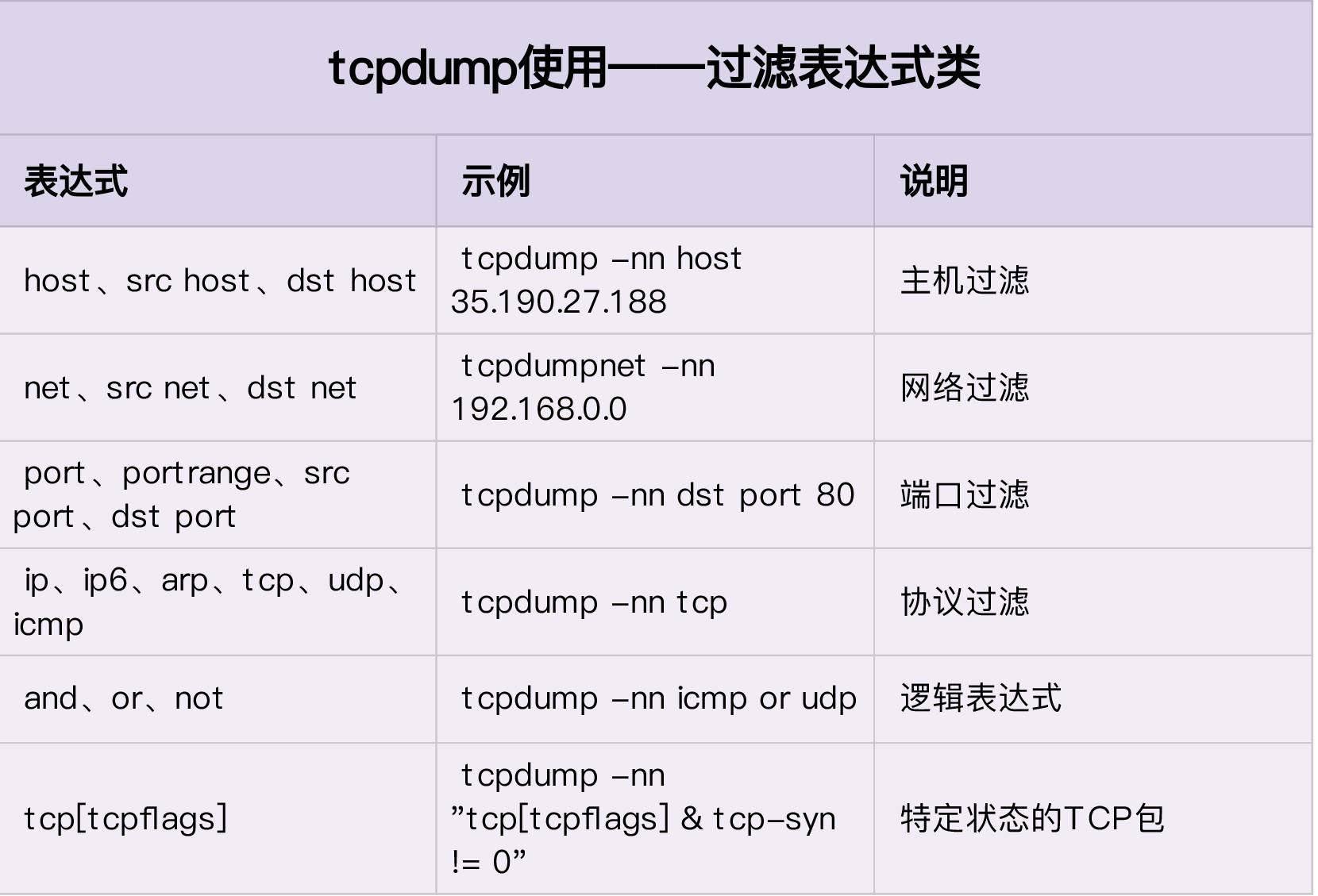
使用 tcpdump 和 Wireshark 分析网络流量
tcpdump
实例
实际上,根据 IP 地址反查域名、根据端口号反查协议名称,是很多网络工具默认的行为,而这往往会导致性能工具的工作缓慢。所以,通常,网络性能工具都会提供一个选项(比如 -n 或者 -nn),来禁止名称解析。
NAT 原理
NAT 技术可以重写 IP 数据包的源 IP 或者目的 IP,被普遍地用来解决公网 IP 地址短缺的问题。它的主要原理就是,网络中的多台主机,通过共享同一个公网 IP 地址,来访问外网资源。同时,由于 NAT 屏蔽了内网网络,自然也就为局域网中的机器提供了安全隔离。
NAT 的主要目的,是实现地址转换。根据实现方式的不同,NAT 可以分为三类:
- 静态 NAT,即内网 IP 与公网 IP 是一对一的永久映射关系;
- 动态 NAT,即内网 IP 从公网 IP 池中,动态选择一个进行映射;
- 网络地址端口转换 NAPT(Network Address and Port Translation),即把内网 IP 映射到公网 IP 的不同端口上,让多个内网 IP 可以共享同一个公网 IP 地址。
NAPT 是目前最流行的 NAT 类型,我们在 Linux 中配置的 NAT 也是这种类型。而根据转换方式的不同,我们又可以把 NAPT 分为三类。
第一类是源地址转换 SNAT,即目的地址不变,只替换源 IP 或源端口。SNAT 主要用于,多个内网 IP 共享同一个公网 IP ,来访问外网资源的场景。
第二类是目的地址转换 DNAT,即源 IP 保持不变,只替换目的 IP 或者目的端口。DNAT主要通过公网 IP 的不同端口号,来访问内网的多种服务,同时会隐藏后端服务器的真实IP 地址。
第三类是双向地址转换,即同时使用 SNAT 和 DNAT。当接收到网络包时,执行DNAT,把目的 IP 转换为内网 IP;而在发送网络包时,执行 SNAT,把源 IP 替换为外部IP。
双向地址转换,其实就是外网 IP 与内网 IP 的一对一映射关系,所以常用在虚拟化环境中,为虚拟机分配浮动的公网 IP 地址。
网络性能优化的几个思路
根据指标查找工具
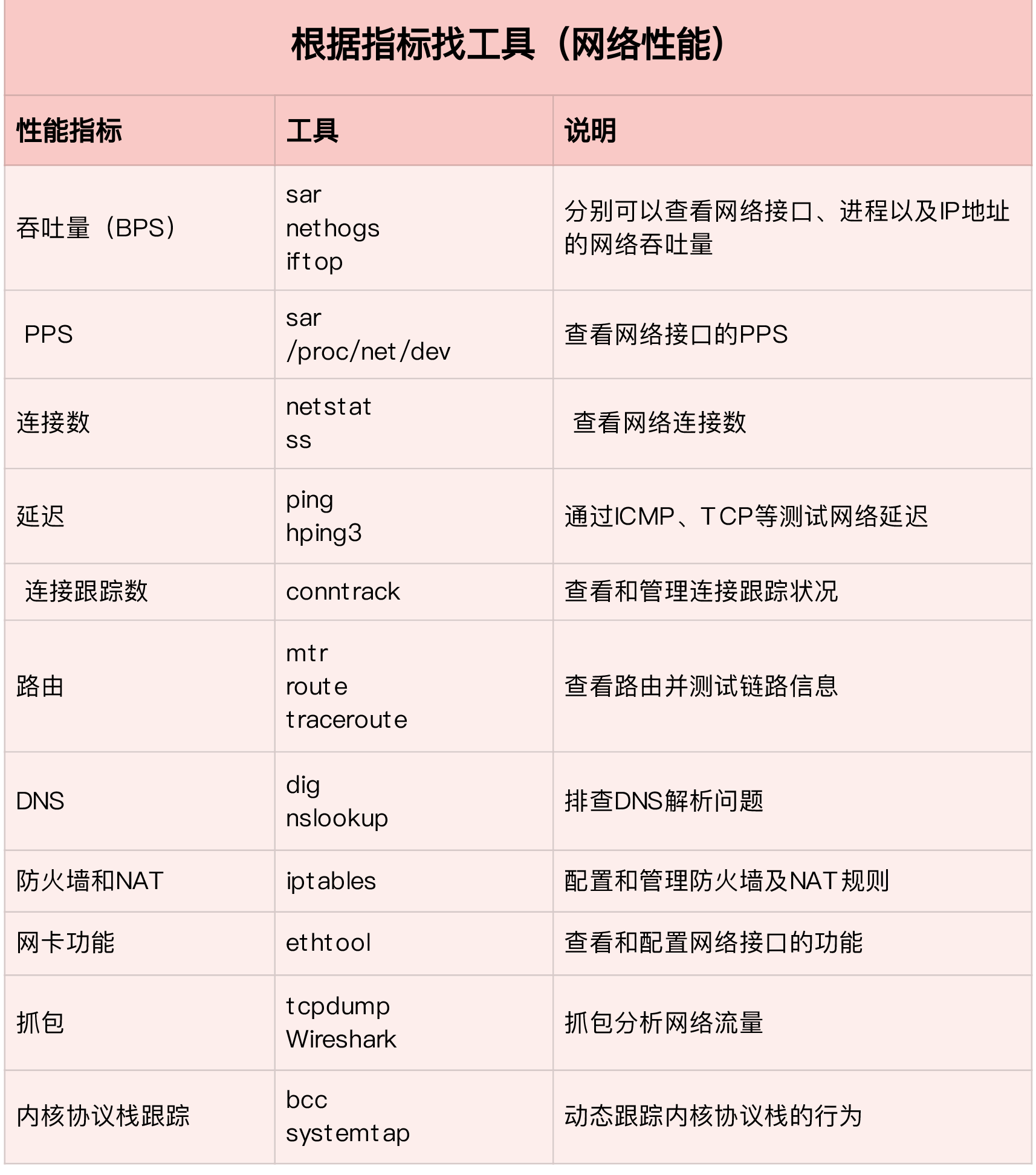
根据工具查找指标
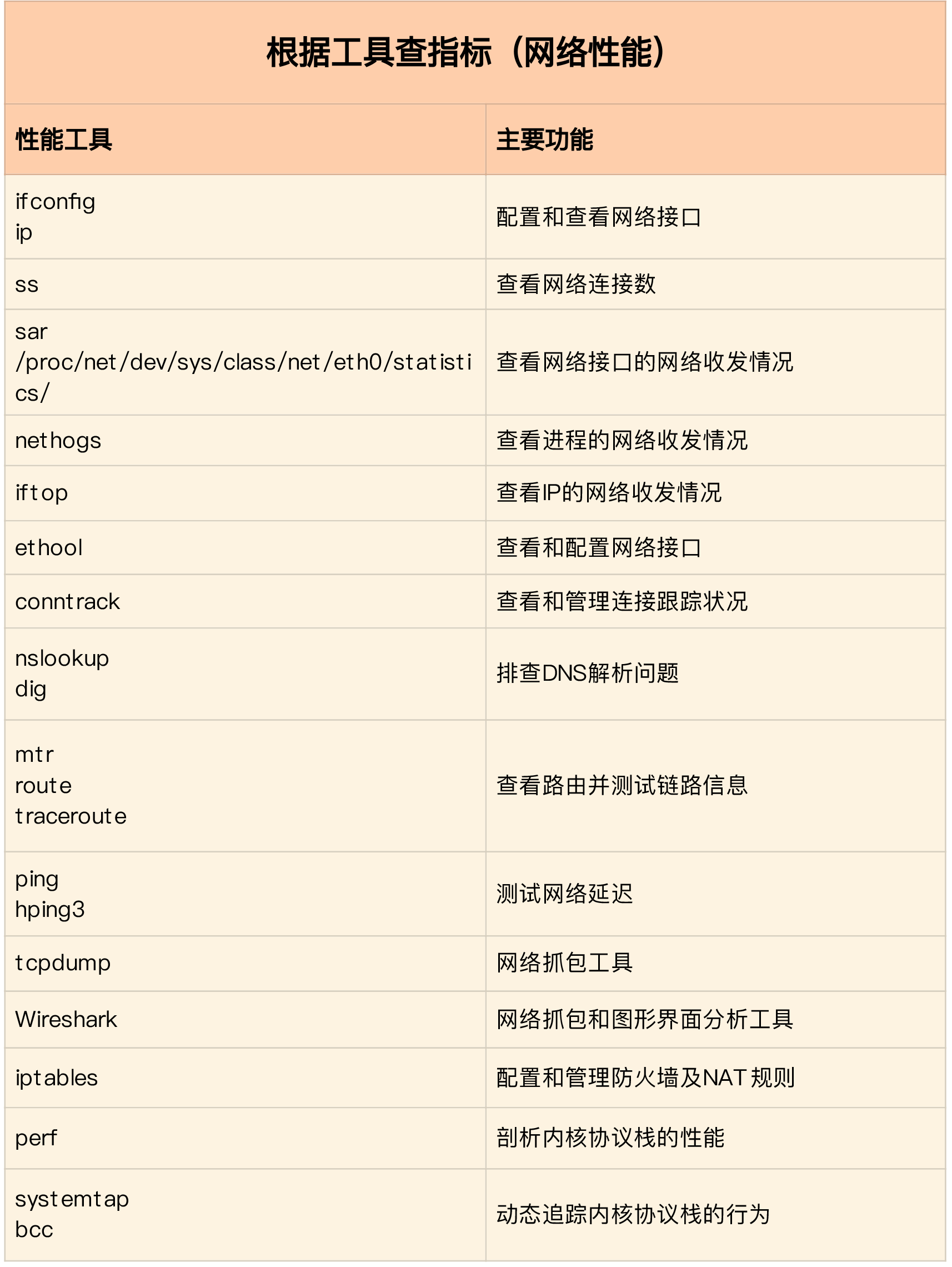
实践
服务器总是时不时丢包,我该怎么办?
内核线程 CPU 利用率太高,我该怎么办?
动态追踪怎么用?
服务吞吐量下降很厉害,怎么分析?
注意套接字部分的排查,netstat -s | grep socket
套接字丢包? 套接字队列溢出?
排查问题注意的指标
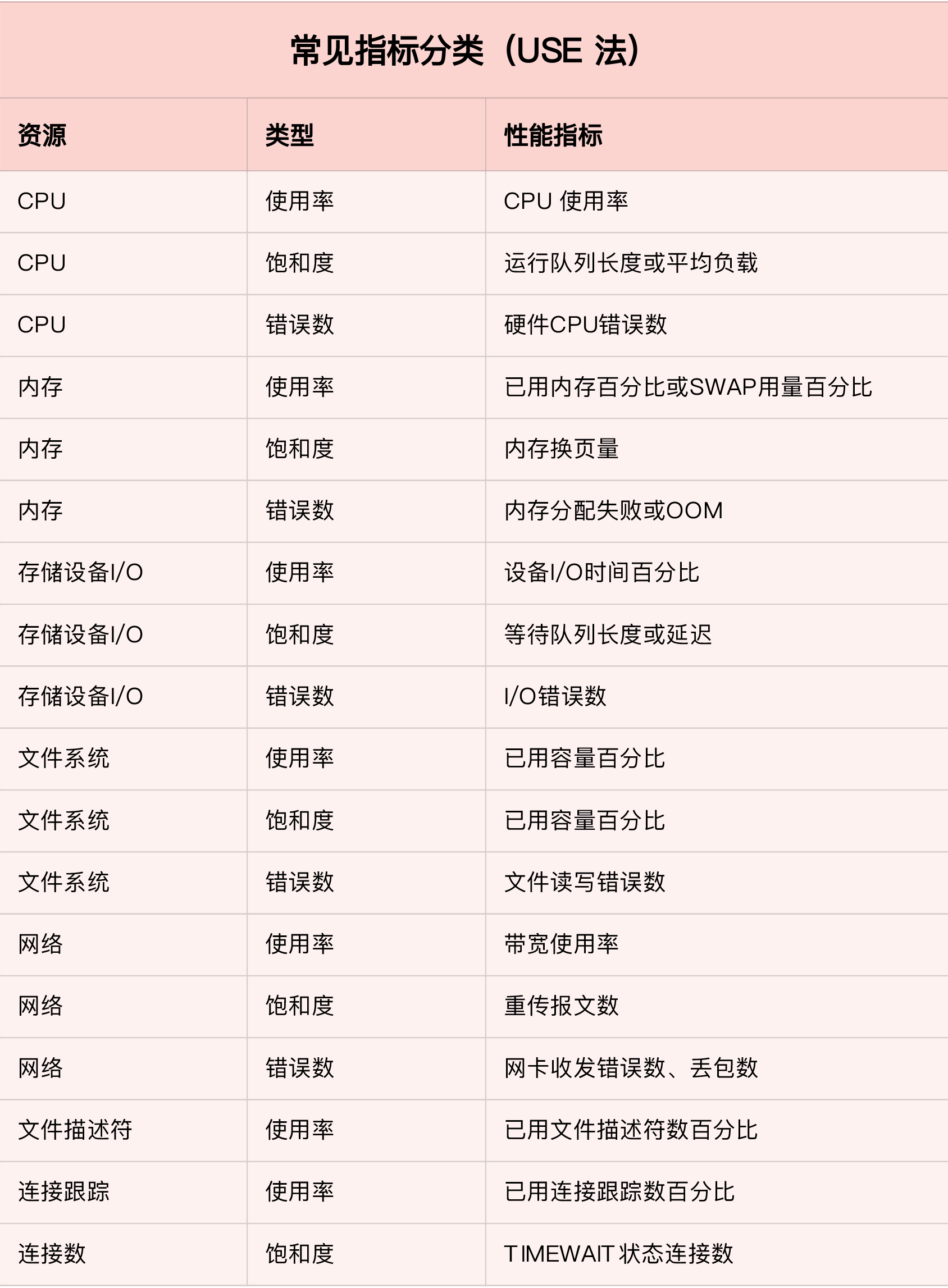
注意网络部分